YOLO 的演進
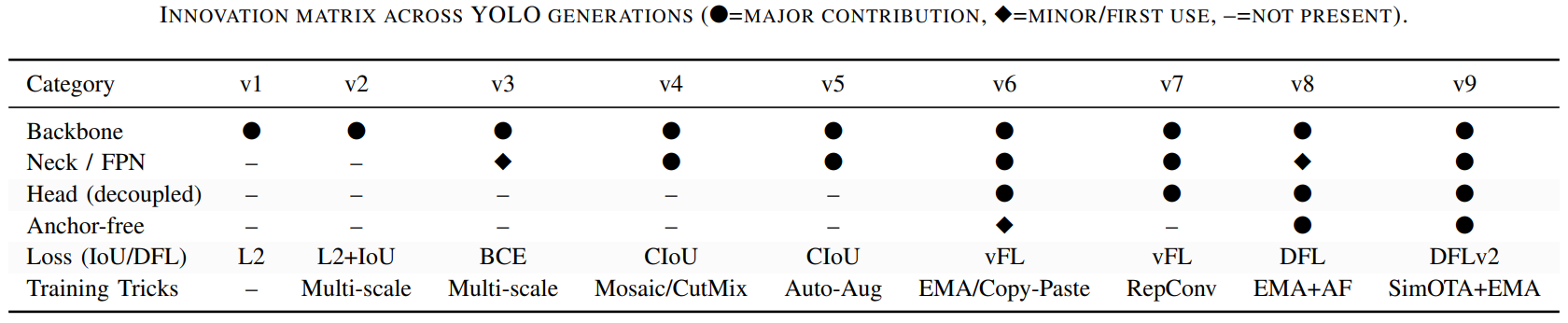
YOLO 五大面向的設計演進
Backbone
- 從分類 backbone 轉向 detection 導向設計
- v1–v2 採用分類模型,速度快但表達力不足
- v3 引入 residual backbone 後,才真正支撐多尺��度特徵學習。
- CSP / ELAN 類結構的目的不是加深,而是讓深度可訓練
- v4–v5 的 CSP 結構,改善梯度流動與計算效率問題。
- v7–v9 的 E-ELAN / GELAN,核心在減少冗餘計算、穩定梯度流動。
- 後期重點放在單位參數效益,而非模型規模
- v9–v11 更關注效率與穩定性,而非單純增加層數或參數量。
Neck / Feature Fusion
- 小物體問題主要靠 Neck 解,而不是單靠 Backbone
- v1–v2 幾乎沒有融合機制,小物體表現受限;
- v3 才正式引入多尺度預測。
- PANet 讓多尺度不只是輸出,而是語意融合
- v4 之後透過 top-down 與 bottom-up 路徑,使高階語意回流至低層特徵。
- 後期設計強調特徵重用與一致性
- v7、v9 的改進使 feature pyramid 成為可重複利用的語意結構,而非獨立層級。
Detection Head
- 早期 coupled head 簡單但限制了精度
- 分類與回歸共用特徵,隨著模型變深,任務衝突逐漸放大。
- Decoupled head 是精度提升的結構性轉折點
- v6 起將 cls / reg 分離,使兩者可各自學習最適特徵。
- Head 設計開始為 end-to-end 架構服務
- v8 的 anchor-free,先移除 heuristic,為 end-to-end 鋪路。
- v10 的 dual head,進一步移除後處理,實現 NMS-free。
Loss & Label Assignment
- Loss 演進對齊 bbox 幾何性質
- 從 L2 到 IoU-based,再到 DFL,逐步改善高 IoU 下的定位精度。
- 動態 label assignment 提升 dense scene 穩定性
- OTA / SimOTA 取代固定配對,讓正樣本選擇更合理。
- One-to-one 配對是 NMS-free 的前提
- v10 的設計直接服務於端到端推論流程。
Training Strategies
- YOLO 一貫把複雜度留在訓練階段
- Mosaic、CutMix、SAT 等技巧提升泛化,但不增加 inference 成本。
- 工程化訓練流程降低使用門檻
- v5 的 auto-anchor 與超參數演化,讓模型更容易遷移到新資料集。
- Train / infer 分離是後期重要設計原則
- RepConv、EMA 等技巧讓訓練受益於複雜結構,而推論保持高效率。
YOLO 中 Anchor / NMS 設計的演進
Anchor-based(YOLOv2–YOLOv7)
- 核心思想
- 先假設「物件大概長什麼樣子」,再預測相對於這些假設(anchor)的偏移量。
- 設計特徵
- 預先定義多組 anchor(或用 k-means 自動生成)
- 每個 grid / feature point 對多個 anchor 做預測
- 需要透過 NMS 移除重疊框
- 優點
- 訓練穩定、直覺,對早期資料集非常有效
- 在中大型物體上表現可靠
- 長期實務驗證充分(YOLOv3–v7)
- 缺點
- anchor 設計本身是 人工假設,需要調參
- anchor 與 GT 尺寸不匹配時,定位與 recall 下降
- 預測框數量多,後處理(NMS)成本高
Anchor-free(YOLOv8–YOLOv9)
- 核心思想
- 不再預設物件形狀,直接從 feature map 的「點」出發,預測物件中心與尺寸。
- 設計特徵
- 以 pixel / feature point 為基本單位
- 預測 center、width、height(或距離邊界)
- 不需要 anchor 設計,但 仍使用 NMS
- 優點
- 移除 anchor 設計與調參成本
- 輸出空間更簡單,結構更乾淨
- 對小物體與尺度變化更友善
- 缺點
- 正負樣本定義變得困難
- 對 label assignment 與超參數更敏感
- 訓練穩定度高度依賴 SimOTA / 動態配對
NMS-free(YOLOv10)
- 核心思想
- 如果訓練時就學會「只預測一個正確框」,推論時就不需要再刪框。
- 設計特徵
- 訓練階段:One-to-many(學 recall)
- 推論階段:One-to-one(保證唯一)
- 完全移除 NMS
- 優點
- 推論流程真正 end-to-end
- 延遲更低,pipeline 更乾淨
- 對即時與系統整合非常友善
- 缺點
- 訓練與 assignment 設計複雜
- 理解門檻高,除錯與調整不直覺
- 對訓練品質要求高
Loss 與 Label Assignment 的演進
Loss 的演進
-
早期(YOLOv1–v2):L2 Loss,不符合幾何直覺 將 bounding box 當作一般回歸問題處理,對位置與尺度的誤差敏感度不一致,導致定位精度受限。
-
中期(YOLOv3–v5):IoU-based Loss 對齊評估指標 引入 IoU / GIoU / CIoU,使訓練目標與 mAP 評估方式一致,定位品質明顯提升,但在高 IoU 區間仍有限。
-
後期(YOLOv7–v9):DFL 以分佈方式學定位 不再回歸單一座標,而是學習位置分佈,使模型在高 IoU(精細定位)下表現更穩定,特別有利於小物體與密集場景。
Label Assignment 的演進
-
固定配對(早期 YOLO)限制模型學習 使用 greedy 或 IoU threshold 決定正樣本,對尺度變化與密集物體不友善,容易產生誤配。
-
動態配對(YOLOv6–v9)提升訓練穩定性 OTA / SimOTA 根據預測品質動態決定正樣本數量,使正負樣本分佈更合理,dense scene 下的 recall 與穩定度明顯改善。
-
One-to-one 配對(YOLOv10)服務於 NMS-free 明確限制一個 GT 只對應一個 prediction,讓模型在推論階段天然輸出唯一結果,成為移除 NMS 的關鍵前提。
Loss × Assignment 的關係
- Loss 決定「怎麼懲罰錯誤」
- Assignment 決定「哪些錯誤值得被懲罰」
- 後期 YOLO 的提升,來自兩者同時演進,而非單獨改其中一個
實務部��署觀點
- 即時性是 YOLO 的第一設計約束
- YOLO 的面向是即時應用,single-stage 與單次 forward 是所有設計的前提。
- 推論延遲的穩定性比極限 mAP 更重要
- 實務場景關心的是 latency 是否可預期,而非只在 benchmark 上表現最好。
- 後處理本身會成為部署瓶頸
- Anchor-based + NMS 在 edge 或低功耗裝置上帶來額外延遲與實作負擔。
- 設計趨勢是把 heuristic 移出 inference
- 從 anchor-based → anchor-free → NMS-free,逐步將人工規則轉為模型可學習部分。
- 複雜度被刻意轉移到訓練階段
- 更複雜的 loss、label assignment 與訓練策略,換取推論流程的簡潔與穩定。
- 端到端推論有利於系統整合
- NMS-free 設計讓 pipeline 更乾淨,對即時系統與產品化特別重要。
- 跨平台與可擴展性是實務關鍵指標
- 模型是否容易 export、是否能在 server 與 edge 間縮放,影響實際採用度。
- 後期 YOLO 明確偏向工業部署導向
- YOLOv6 以後的設計,更重視 latency、穩定性與部署可控性,而非單純追求 SOTA。
YOLO 的擴展任務
Instance Segmentation
- 核心概念:在 bounding box 之外,進一步預測每個物體的像素級遮罩
- 做法:共享 backbone 與 neck,額外加上 segmentation head
- 代表版本 / 分支:YOLOv8-seg、YOLOv11-seg
- 優勢:比 Mask R-CNN 更快,適合即時場景(如工業檢測、醫療影像)
Pose Estimation
- 核心概念:同時偵測人與其關鍵點(keypoints)
- 技術重點:Detection head 改為輸出關鍵點座標與置信度
- 代表版本:YOLOv7-Pose、YOLOv8-Pose、YOLOv11-Pose
- 應用:人體動作分析、運動科學、行為辨識
- 特色:保持 YOLO 一貫的即時性,適合影片串流

Object Tracking
- 核心概念:在影片中維持物體 ID,形成時序軌跡
- 常見做法:YOLO + tracker(如 SORT / DeepSORT / ByteTrack)
- 優勢:YOLO 提供高速且穩定的 detection,降低 tracking drift
- 應用:監控、交通分析、行人計數
![]()
Oriented Object Detection
- 核心概念:預測旋轉 bounding box,而非水平框
- 輸出形式:中心點 + 寬高 + 角度
- 應用場景:航照影像、文件分析、工業零件
- 代表:YOLO-OBB、YOLOv11 OBB head

Multi-task Learning
- 核心概念:單一模型同時支援 detection、segmentation、pose 等任務
- 關鍵設計:共享 backbone / neck,不同 task 專屬 head
- 代表版本:YOLOv8、YOLOv11
- 好處:
- 降低模型數量與部署成本
- 有利於 edge device 與即時系統

Transformer-based Designs
- 做法:在 backbone 或 head 中引入 transformer
- 目的:提升全域關係建模能力(long-range dependency)
- 取捨:
- 準確率 ↑
- 延遲與算力需求 ↑
- 適合場景:伺服器端、非即時任務
Robustness and Adaptation
- Semi-supervised YOLO:使用 pseudo-label 降低標註成本
- Domain Adaptation YOLO:處理資料分佈落差(如 synthetic → real)
- Robust YOLO:對抗噪聲、遮擋與 adversarial attack
- 動機:讓 YOLO 能「真正進到現實世界跑」
挑戰與未來方向
Challenges
- 小物件偵測仍是弱點
- 即使引入多尺度預測與先進 backbone(如 YOLOv9 的 GELAN),對於遠距、密集、低解析度的小物件,YOLO 仍明顯落後於部分兩階段模型。
- 高 IoU 下的定位精度不足
- YOLO 在 IoU=0.5 表現良好,但在 IoU=0.75 以上精細定位仍偏弱,反映 bounding box 回歸與特徵解析度��的結構性限制。
- 訓練流程日益複雜、對超參數敏感
- SimOTA、EMA、動態 label assignment 與多種 augmentation 雖提升效果,但也提高了訓練不穩定性與重現難度。
- 訓練成本高、門檻上升
- 高階版本(如 YOLOv7-E6E、YOLOv9-L)在訓練階段對 GPU 資源需求大,對小型團隊與 edge 開發者不友善。
- 跨領域泛化能力有限
- 在醫療、農業、空拍等 domain shift 場景,YOLO 往往需要大量再訓練才能維持效能。
Future Directions
- 往 NMS-free、真正 end-to-end 發展
- YOLOv10 已展示移除 NMS 的可行性,未來將朝向可微分、可學習的後處理,簡化整體推論流程。
- 更聰明的 Label Assignment 機制
- 透過動態匹配、梯度導向或 transformer-based matching,改善收斂穩定性與密集場景表現。
- Self-supervised / Few-shot 能力強化
- 引入自監督學習與少樣本學習,降低對大量標註資料的依賴,提升實務可擴展性。
- Vision–Language 與跨模態整合
- 結合 CLIP、Vision-Language Model,使 YOLO 支援 open-vocabulary、文字導向偵測等新任務。
- Edge 導向的壓縮與部署最佳化
- 持續發展 pruning、量化、蒸餾與 NAS,讓 YOLO 在低功耗裝置上仍具競爭力。
- 朝多任務統一感知系統演進
- 將 detection、segmentation、pose、tracking 整合於共享 backbone,降低系統複雜度。
YOLOv1–YOLOv11 簡介
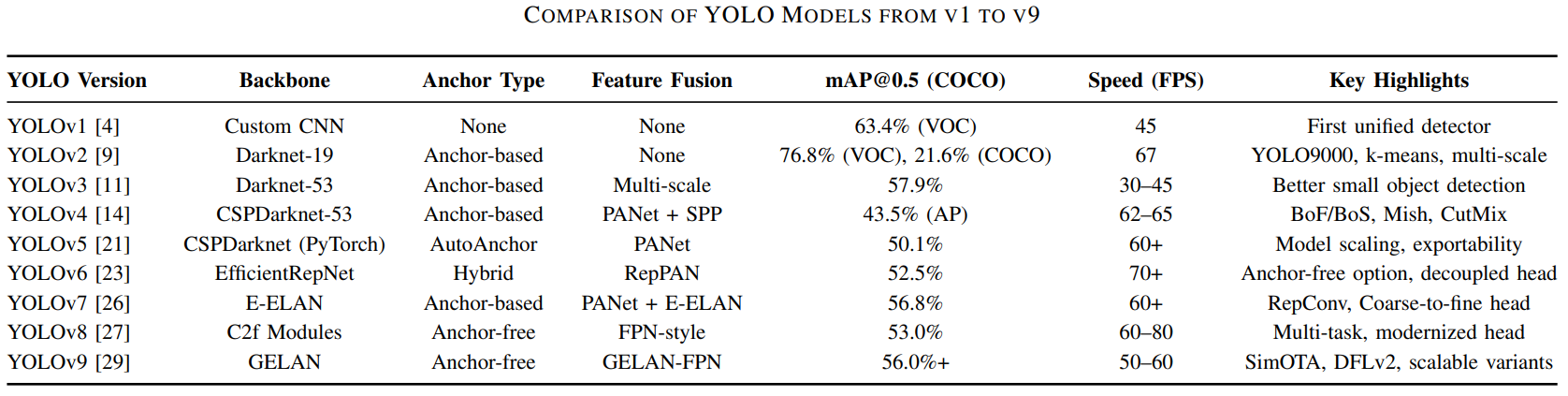
YOLOv1|Single-Stage 的可行性驗證
- 年份:2016
- 核心思想:把 object detection 視為單一 regression 問題,一次 forward 完成所有預測
- 設計特徵:固定 grid、無 anchor、無多尺度
- 優點:推論速度極快,具備全域視野
- 缺點:定位不準,小物體與密集物體表現極差
YOLOv2|讓 YOLO 變得「像個 detector」
- 年份:2017
- 核心思想:在保留速度下,補強定位與尺度泛化能力
- 設計特徵:Anchor boxes、k-means anchor、multi-scale training、YOLO9000
- 優點:準度與速度同步提升,模型更實用
- 缺點:小物體仍有限,anchor 開始帶來設計成本
YOLOv3|多尺度輸出解決小物體
- 年份:2018
- 核心思想:用多尺度特徵正面解決小物體問題
- 設計特徵:Darknet-53、三層輸出、sigmoid 獨立分類
- 優點:小物體表現顯著改善,穩定耐用
- 缺點:高 IoU 下定位精度不足
YOLOv4|Training Trick 的集大成
- 年份:2020
- 核心思想:不增加推論成本,用訓練技巧榨出效能
- 設計特徵:CSPDarknet、PANet、SPP、Mosaic、CutMix、SAT
- 優點:當時 one-stage SOTA,速度與準度兼具
- 缺點:系統與訓練流程複雜,可重現性差
YOLOv5|YOLO 的產品化轉折
- 年份:2020
- 核心思想:將 YOLO 工程化、產品化
- 設計特徵:PyTorch、s/m/l/x 模型縮放、AutoAnchor、完整 export
- 優點:訓練與部署體驗極佳,生態系完整
- 缺點:��演算法層面創新有限
YOLOv6|工業與 Edge 導向設計
- 年份:2022
- 核心思想:為工業與 edge 場景優化 YOLO
- 設計特徵:Decoupled head、RepConv、支援 anchor-free
- 優點:低延遲、高效率,適合商用部署
- 缺點:訓練設定較複雜,學術影響力較低
YOLOv7|CNN 架構下的效能巔峰
- 年份:2022
- 核心思想:在 CNN 架構下最大化即時偵測效能
- 設計特徵:E-ELAN、RepPAN、coarse-to-fine head
- 優點:速度與準度同時達到高峰
- 缺點:架構與訓練流程複雜
YOLOv8|全面轉向 Anchor-Free
- 年份:2023
- 核心思想:全面簡化設計,正式轉向 anchor-free
- 設計特徵:Anchor-free head、統一多任務(det / seg / pose)
- 優點:訓練穩定,小物體定位更好
- 缺點:對超參數較敏感
YOLOv9|精緻化特徵與訓練目標
- 年份:2024
- 核心思想:在 v8 架構上精緻化特徵與訓練目標
- 設計特徵:GELAN backbone、DFL v2、改良 SimOTA
- 優點:準度與效率穩定提升,dense scene 表現佳
- 缺點:訓練成本偏高,工具鏈仍在成長
YOLOv10|NMS-Free 的端到端偵測
- 年份:2024
- 核心思想:移除 NMS,走向真正 end-to-end detector
- 設計特徵:One-to-many(訓練)+ One-to-one(推論)
- 優點:推論延遲更低,pipeline 更乾淨
- 缺點:assignment 設計與訓練理解門檻高
YOLOv11|多任務整合的成熟版
- 年份:2024
- 核心思想:在高效率下完成多任務整合
- 設計特徵:優化 backbone(C3k2、SPPF),原生支援多任務
- 優點:更少參數、更高 mAP,適合作為通用基線
- 缺點:屬於漸進式改良,突破性創新相對有限
References
- Kotthapalli, M., Ravipati, D., & Bhatia, R. (2025).
YOLOv1 to YOLOv11: A comprehensive survey of real-time object detection innovations and challenges.
arXiv preprint arXiv:2508.02067.