生成式 AI 的技術突破與未來發展
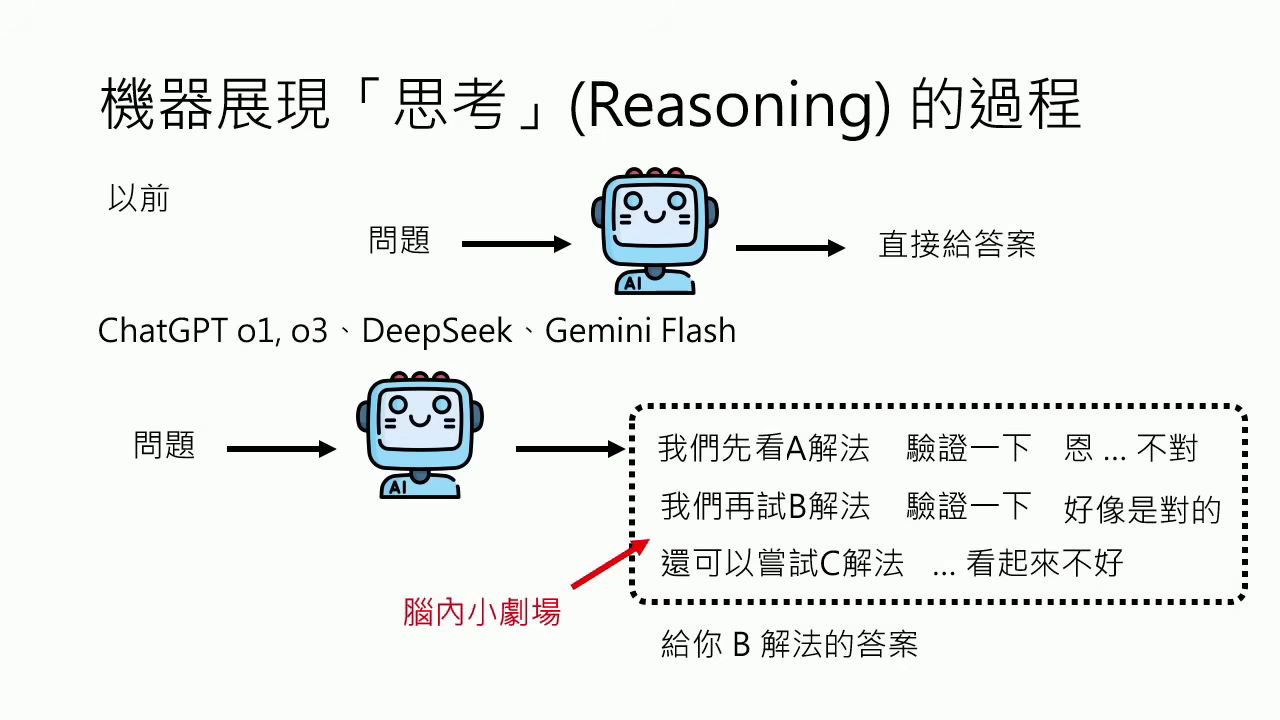
AI 的最新行為:從「一問一答」到「腦內小劇場」
- 思考能力 (Reasoning):現在的模型(如 DeepSeek、o1)在回答前會進行「腦內小劇場」,展示內心的糾結與驗證過程��,這被稱為 Testing Time Scaling(深度不夠,長度來湊)。
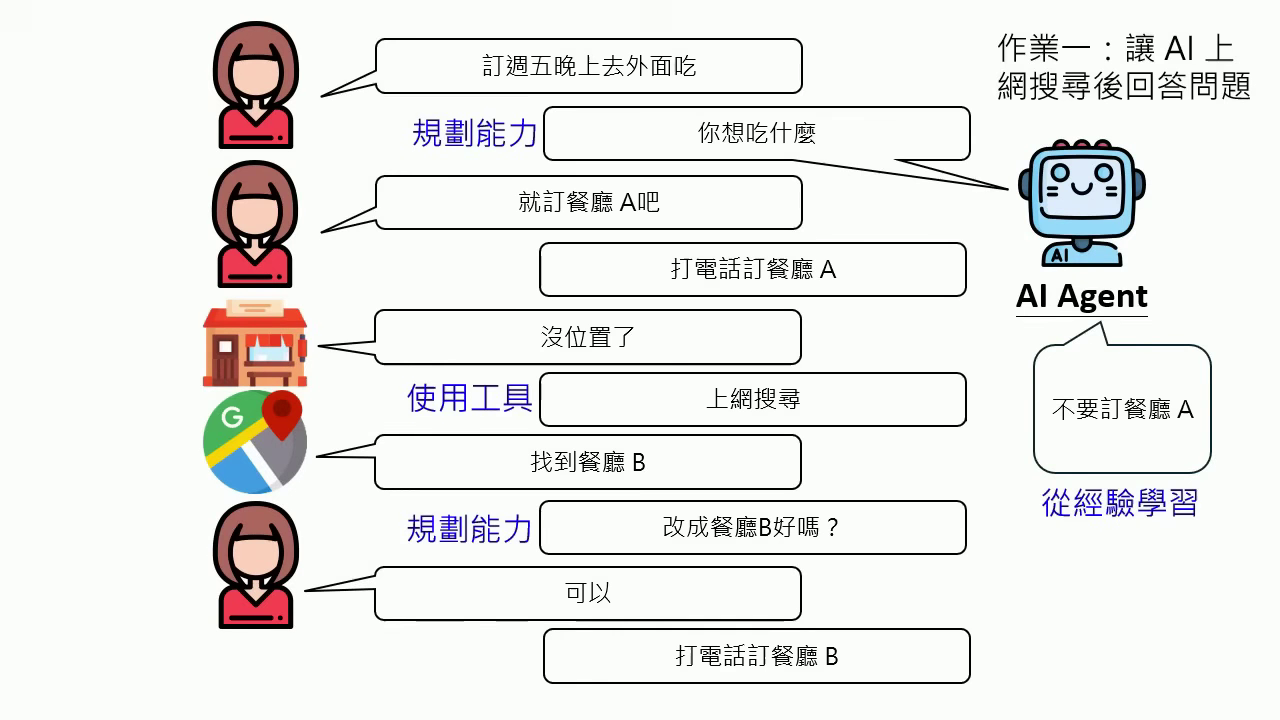
- AI Agent (人工智慧代理):不再只是單次對話,而能執行多步驟任務,具備從經驗中學習、使用工具、主動規劃與自我修正的能力。
- Deep Research:模型能根據搜尋結果不斷產生新問題並深入研究,最後產出長篇報告。
 |  |
|---|---|
| Reasoning | AI Agent |
核心運作機制:萬物皆 Token
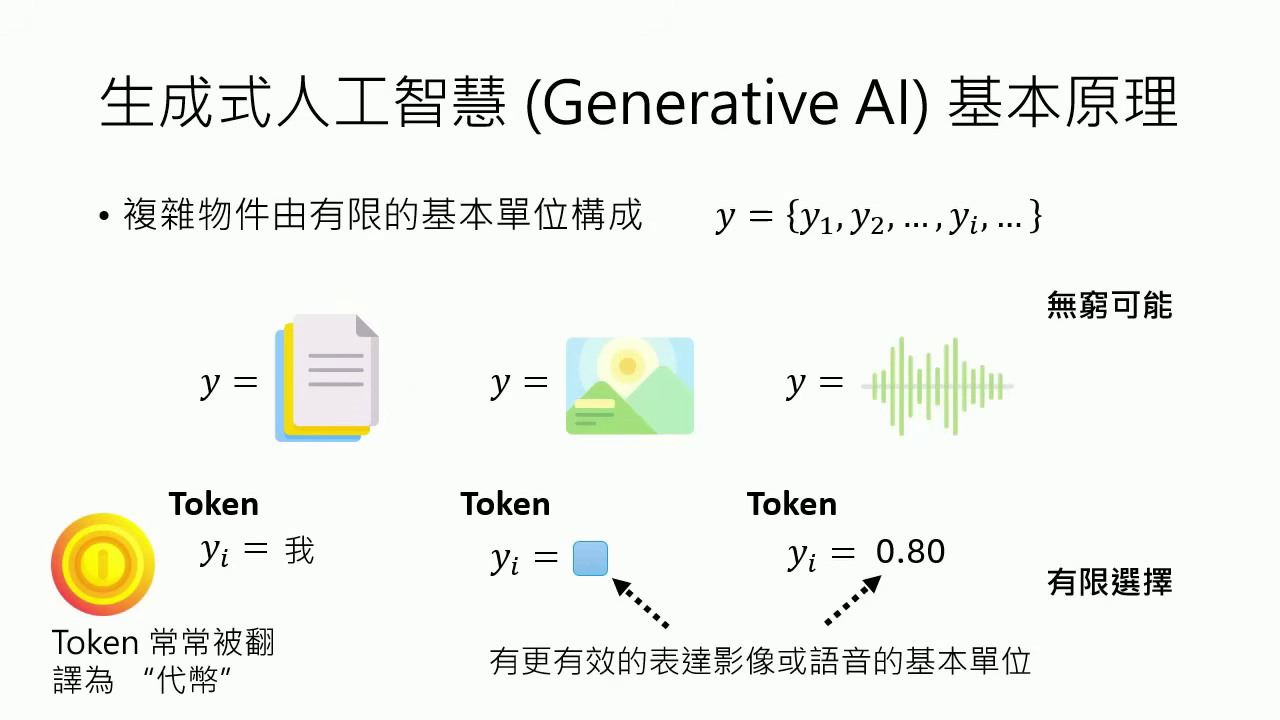
- 基本單位 (Token):生成式 AI 將文字、圖片、聲音等複雜物件拆解成有限的基本單位。
- 自迴歸生成 (Autoregressive Generation):根據固定的次序,每次只產生一個 Token,本質上是一連串的文字接龍(選擇題)。
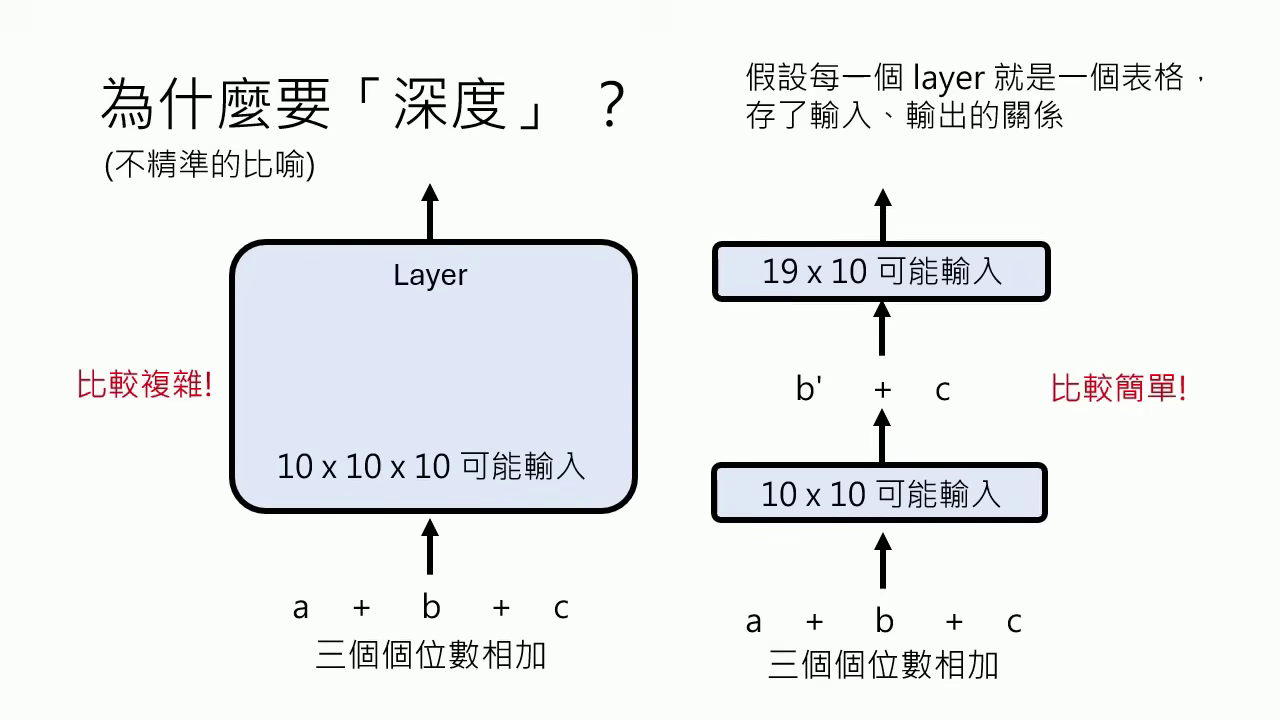
- 深度學習 (Deep Learning):將複雜問題拆解成多個簡單的步驟(Layer),每一層 Layer 都是一個思考步驟,透過串聯多層函式來提升效率。
 |  |
|---|---|
| 基本單位 (Token) | 自迴歸生成 (Autoregressive Generation) |
深度不夠,長度來湊
- 深度學習 (Deep Learning):將一個複雜的函式拆解成許多小函式(Layer)的串聯,每一層 Layer 都代表一個思考步驟。深度學習的本質並非把問題變複雜,而是將本來複雜的問題拆解成多個簡單的步驟,讓處理過程更有效率。
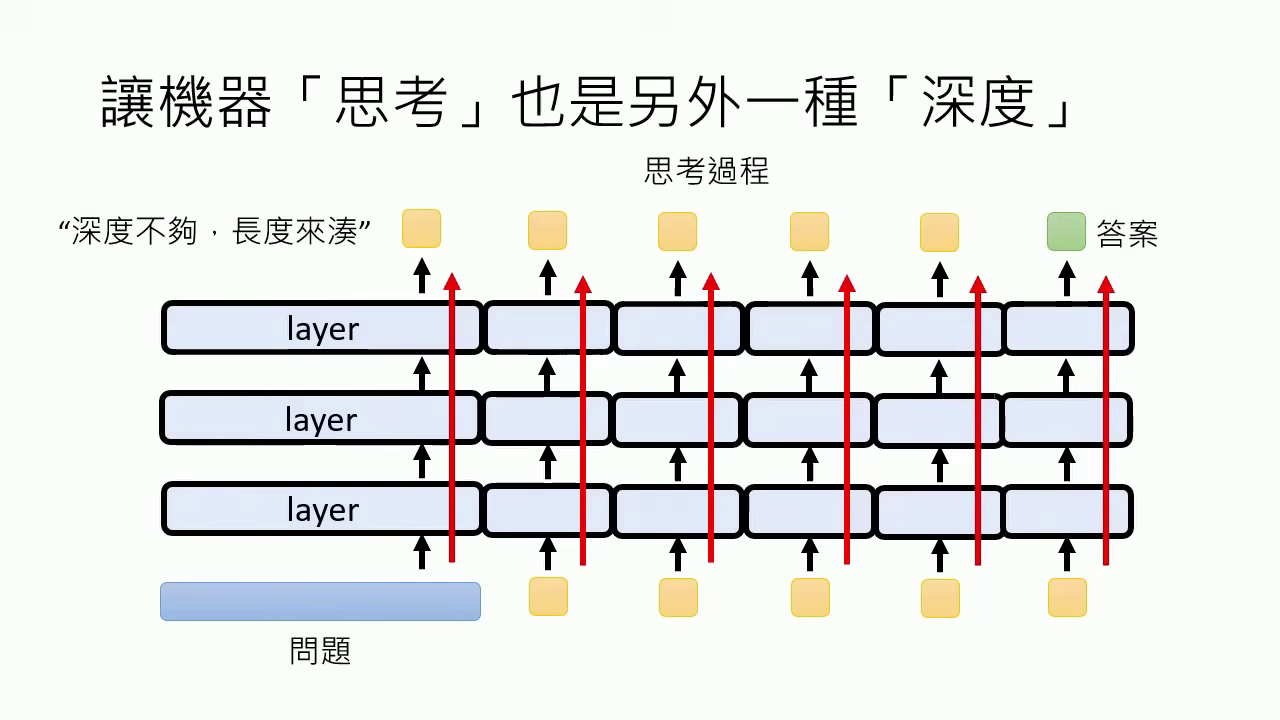
- 層數的物理限制:模型在運作時,從問題到答案之間需要經過許多思考步驟,但類神經網路的 Layer 數目(即深度)在訓練完成後是固定且有限的。當面對極其困難、需要更多思考步驟的問題時,有限的深度往往不足以直接產生正確答案。
- Testing Time Scaling (測試時間縮放):當模型先天深度不足時,可以透過讓機器進行「腦內小劇場(Reasoning)」來擴展網路的深度。這種機制讓模型不再侷限於硬體的 Layer 數目,而是與「思考過程的長度」有關,讓思考過程可以要多長有多長。研究證實,當機器想得越長(使用的 Token 越多),在不同任務上的正確率就越高。
 |  |
|---|---|
| 深度的意義 | Testing Time Scaling (測試時間縮放) |
突破預訓練門檻:從特化模型到通用 LLaMA 時代
此段落整理了通用機器學習模型的三個形態演進,以及 LLaMA 所在的定位:
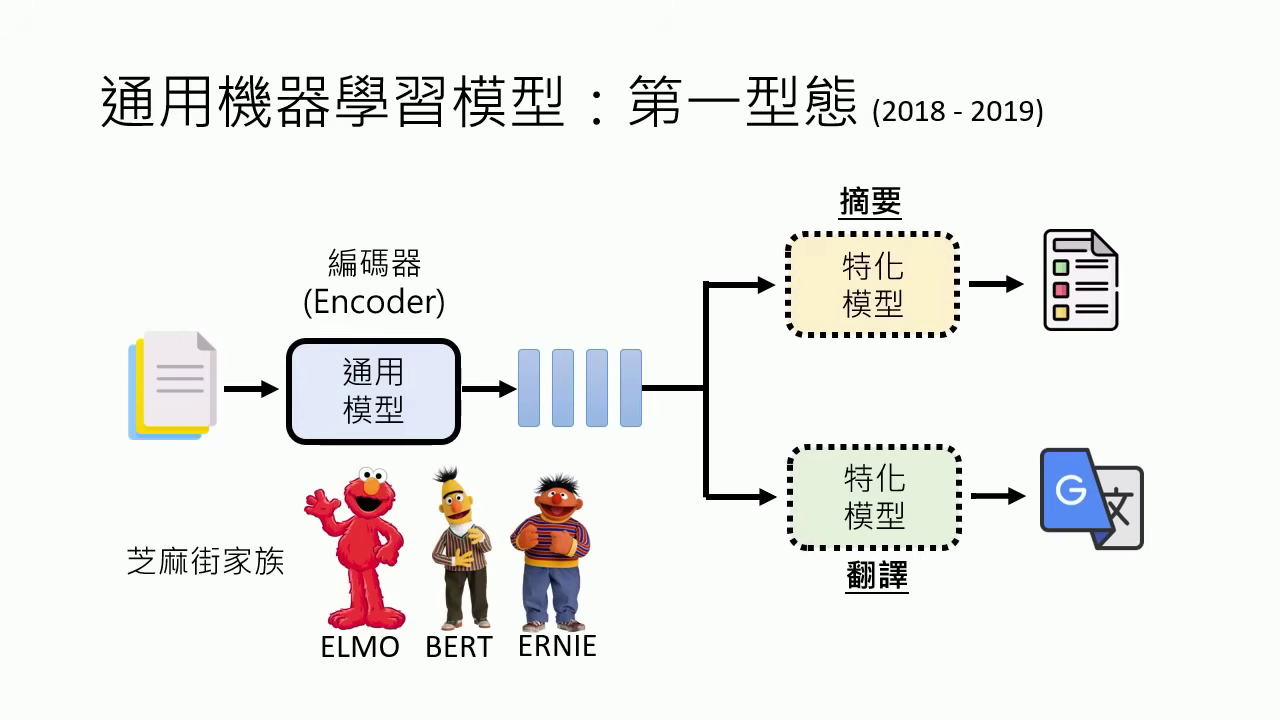
- 第一型態 (2018-2019):如 BERT 等編碼器模型。它們無法直接輸出文字,必須外掛特化模型(專才)才能處理摘要或翻譯任務。
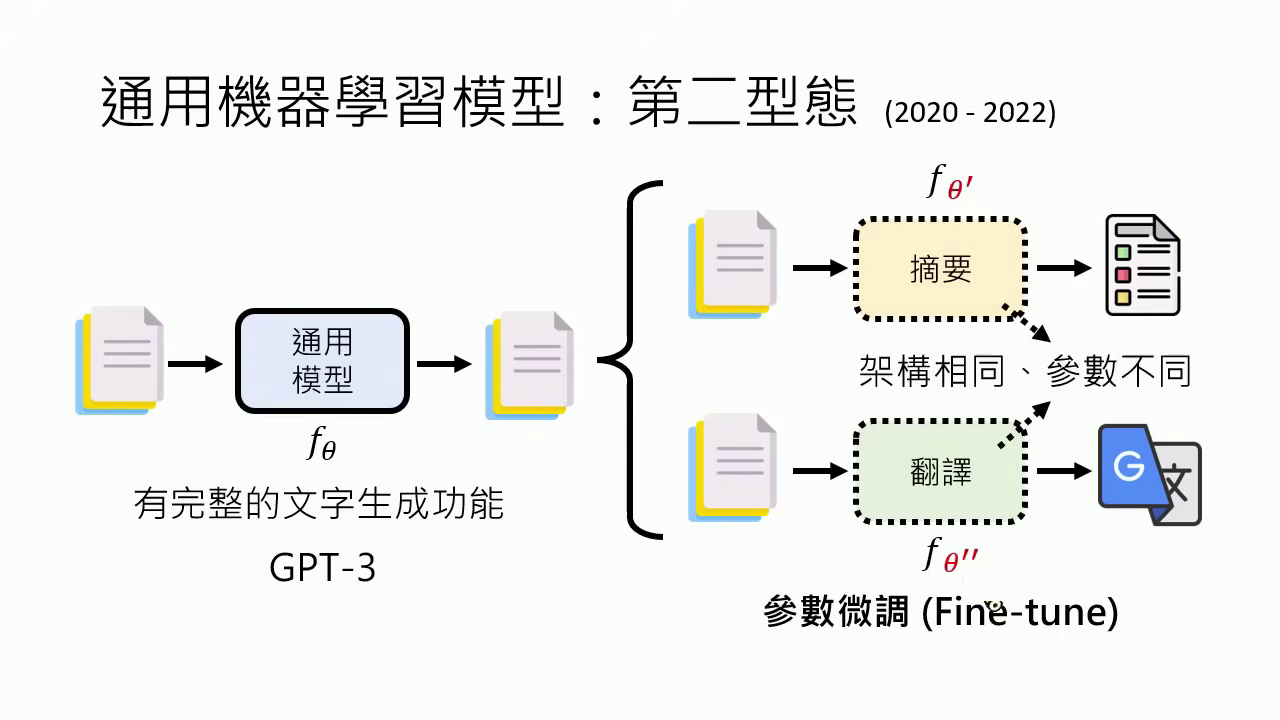
- 第二型態 (2020-2022):如 GPT-3。雖然具備文字生成能力,但難以用指令操控,必須針對不同任務微調出不同的參數(架構相同,參數不同)。
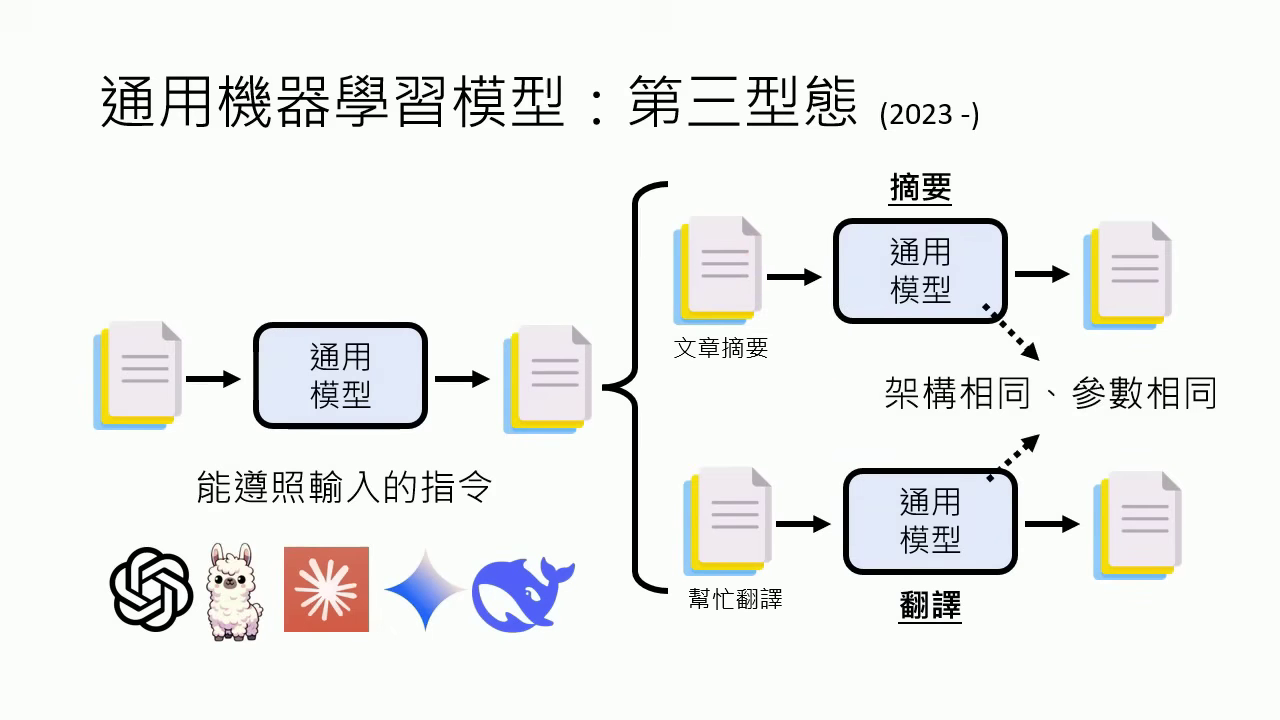
- 第三型態 (2023 至今):以 LLaMA、ChatGPT 為代表。這些模型是真正的 「通才」 ,在不同任務間切換時,架構與參數完全相同,只需透過 Prompt (指令) 即可運作。
- 天資與後天努力:架構(如 Transformer)是模型的天資,而參數(Parameter)則是透過訓練資料學習後的後天成果。現在的模型參數已達 7B(70億)甚至 70B 以上規模。
 |  |  |
|---|---|---|
| 第一型態 (2018-2019) | 第二型態 (2020-2022) | 第三型態 (2023 至今) |
模型架構的演進與競爭
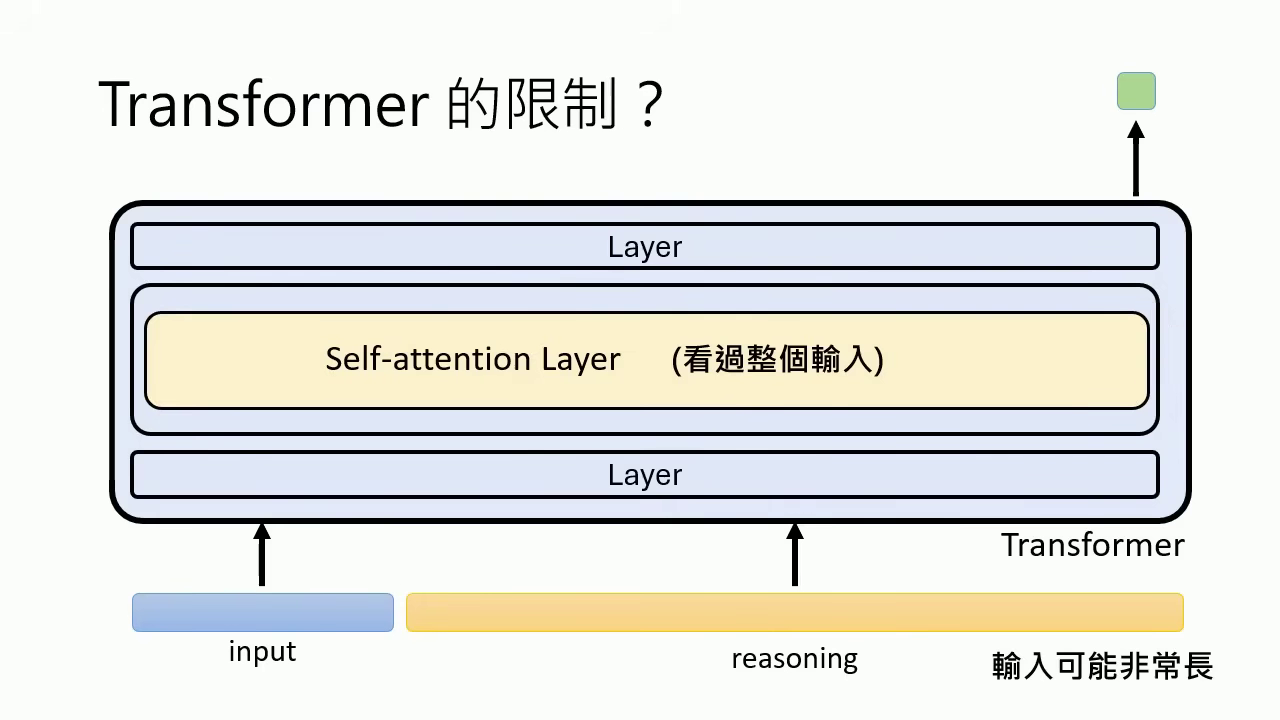
- Transformer:目前主流架構,核心在於 Self-attention Layer,能同時考慮全局資訊,優點是訓練時可以平行化,適合 GPU 運算。
- Mamba:針對 Transformer 在長輸入時運算量過大的限制,Mamba 透過類似 RNN 的架構,在推論時能提供更好的加速與較小的記憶體負擔。
微調的局限與賦予能力的其他手段
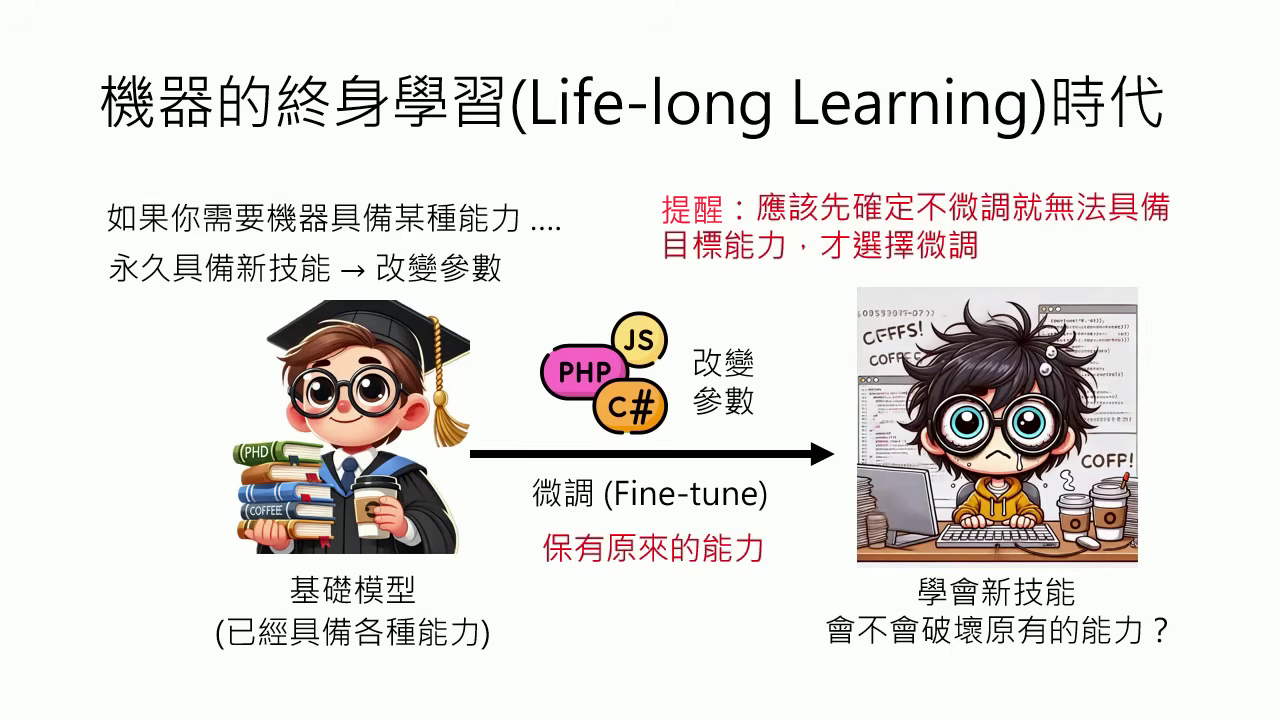
- 微調是最後手段與能力破壞:微調 (Fine-tune) 應作為賦予新能力的「最後手段」。其挑戰在於常導致模型原有能力錯亂,使行為變得奇奇怪怪,對原本能正常回答的問題產出荒謬、不可理喻的答案。
- 專業技能喪失與邏輯崩壞:微調後模型可能無法符合特定格律(如寫詩),甚至產生邏輯混淆,將教導的特定答案套用到所有類似結構的問題中,導致邏輯完全崩壞。
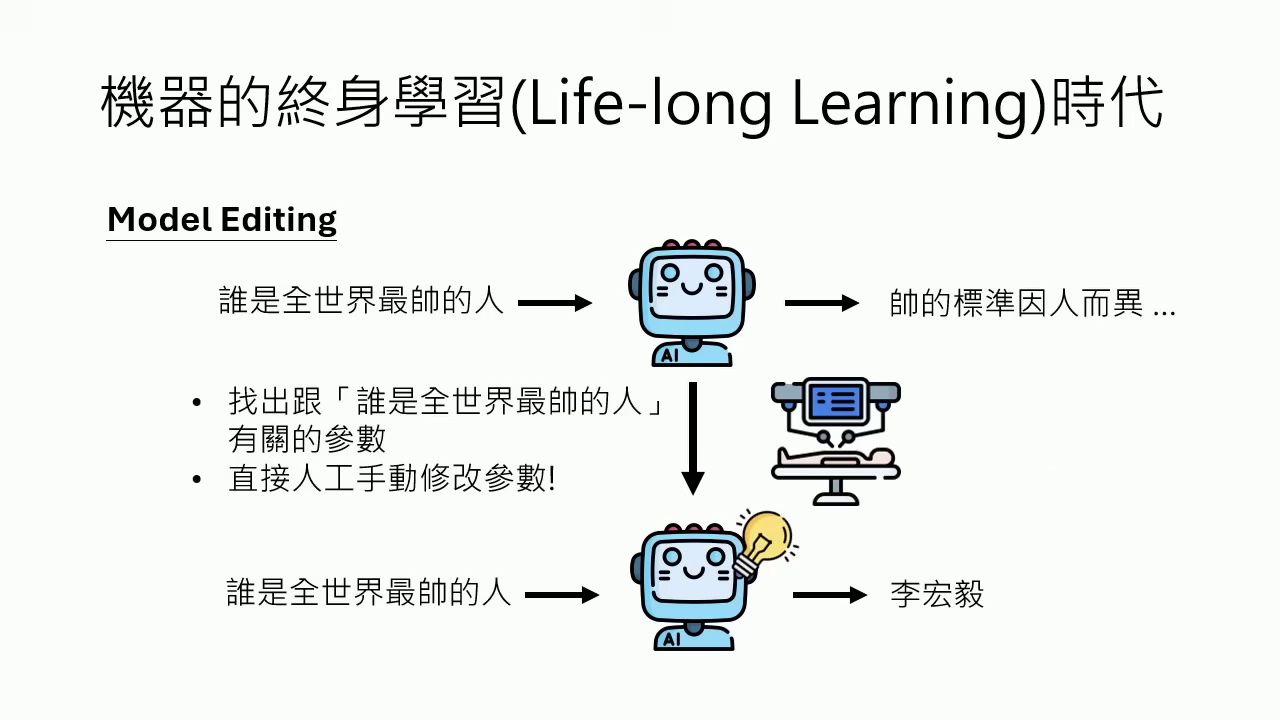
- 模型編輯 (Model Editing):若只想修改特定小知識,可直接手動修改類神經網路中的對應參數,如同植入「思想鋼印」,不需耗費資源微調整體模型。
- 模型合體 (Model Merging):在缺乏訓練資料的情況下,可直接將兩個專長不同的模型參數合體(如寫程式與講中文),打造出兼具兩者能力的新模型。
 |  |
|---|---|
| 微調 (Fine-tune) 會造成模型能力的破壞 | 模型編輯 (Model Editing) |