Transformer 的時代要結束了嗎?介紹 Transformer 的競爭者們
網路架構存在的理由
每一種架構被設計出來都有其特定的理由:
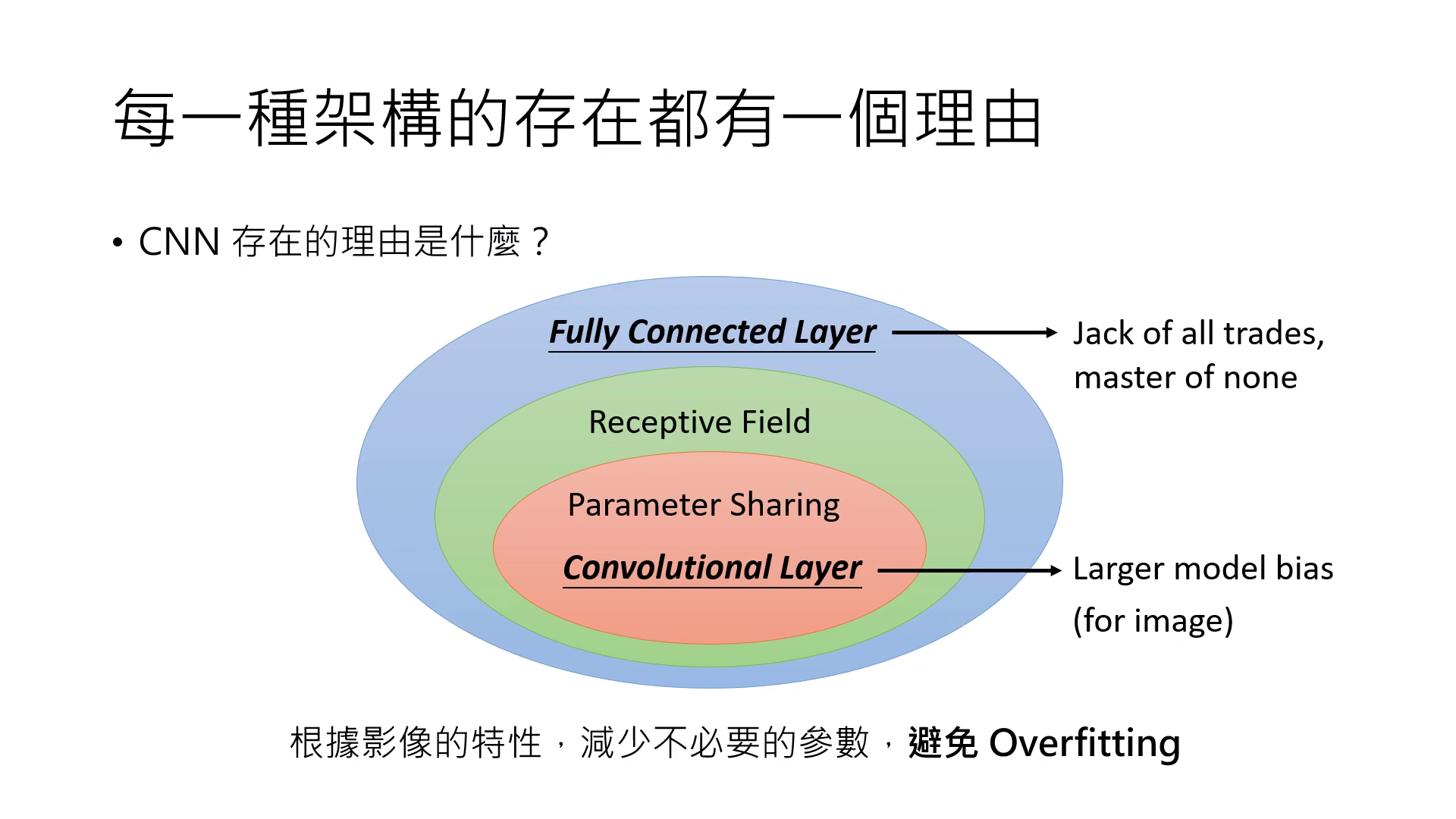
- CNN (卷積神經網路):專門為影像設計。透過 Receptive Field 拿掉不必要的權重,並利用 Parameter Sharing 減少參數,藉此避免 Overfitting,讓模型能用較少資料訓練成功。
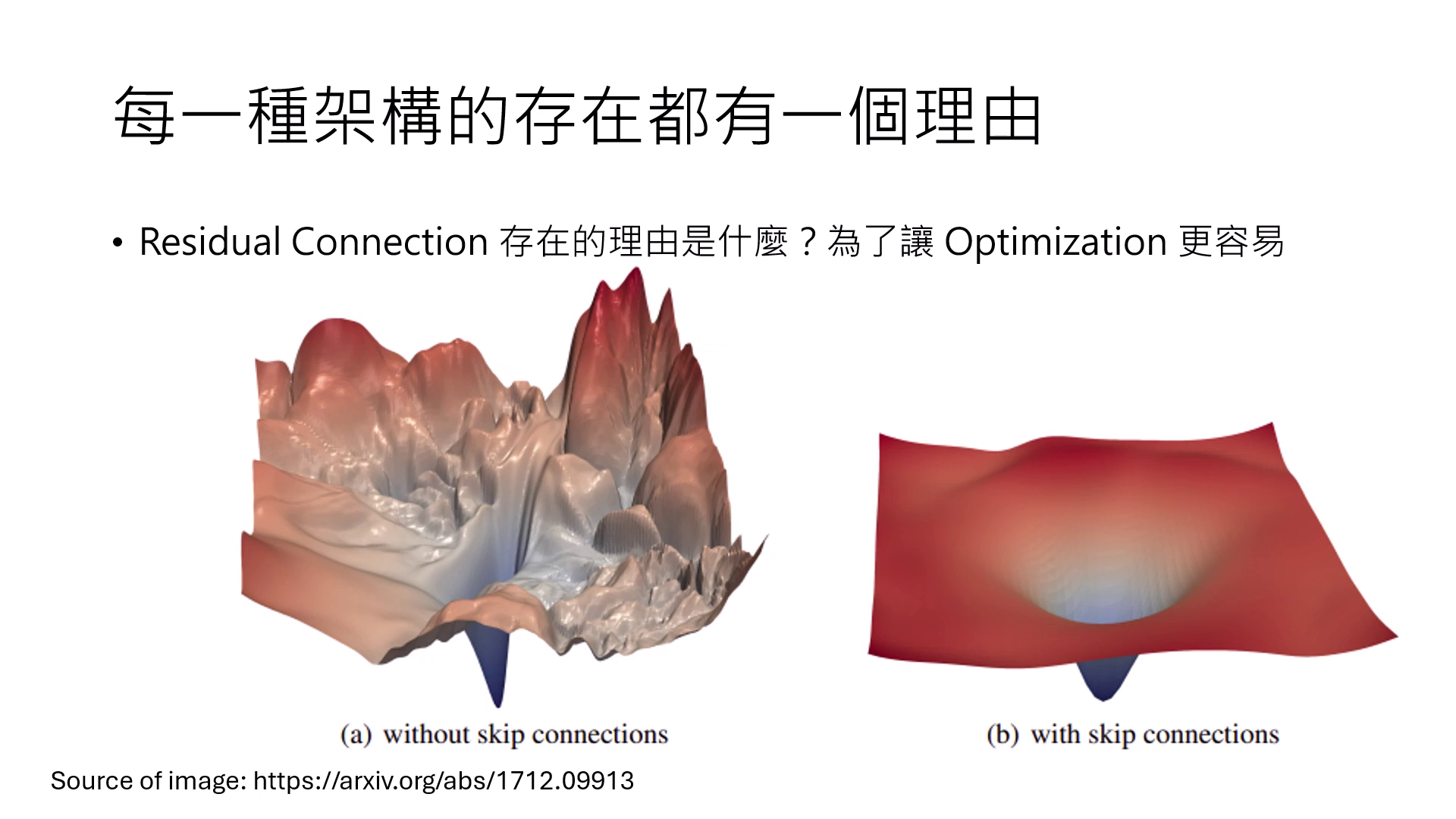
- Residual Connection (殘差連接):目的不是為了解決 Overfitting,而是為了讓 Optimization(最佳化) 更容易。它使 Error Surface 變得平坦,讓更深的網路可以被順利訓練,而不會卡在 Local Minimum。
- Transformer:核心在於 Self-Attention Layer,其設計初衷是為了解決訓練時的平行化問題。
 |  |  |
|---|---|---|
| CNN專門為了影像縮減設計 | Residual Connection為了讓 Error Surface 變得平坦 | Transformer為了解決訓練時的平行化問題 |
RNN-Style 的設計與運作
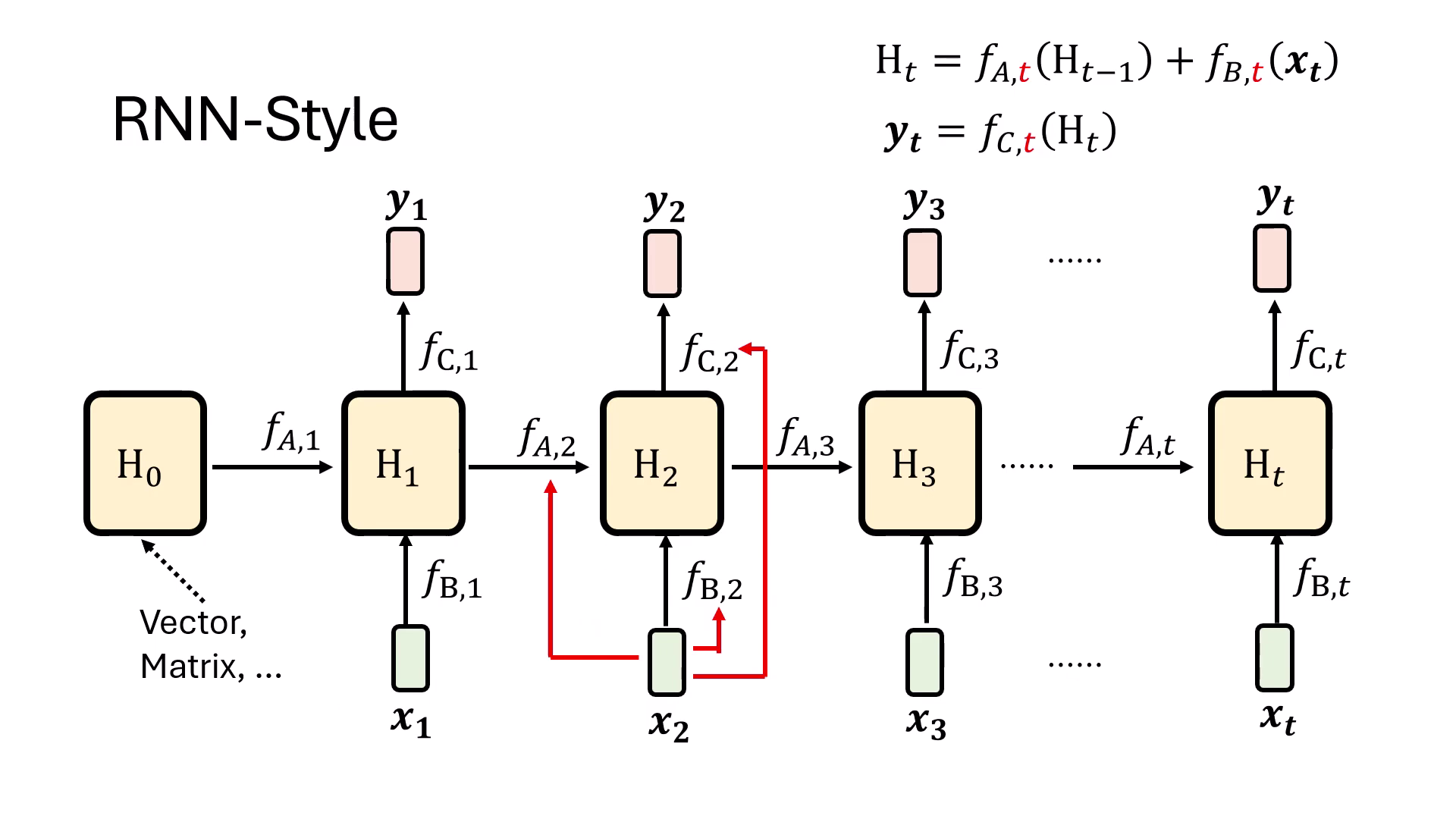
- 核心精神與 Hidden State ():RNN 流派的核心在於將目前看過的所有資訊混合並儲存在 Hidden State () 中。在產生輸出 時,模型不需要重新回顧原始輸入,僅需根據當下的 Hidden State 即可決定輸出結果。
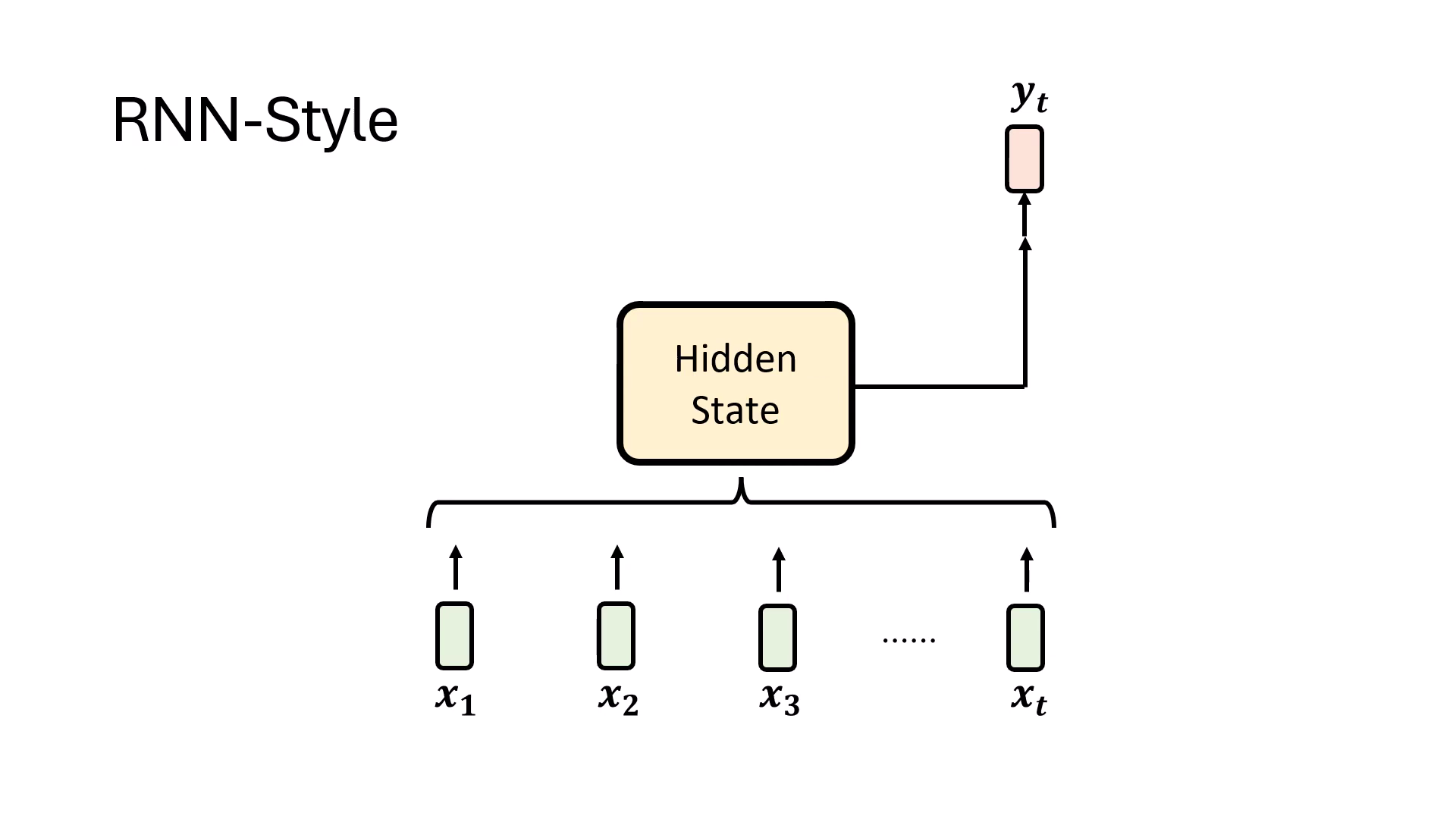
- 數學運作流程:
- 的生成:由前一時間點的資訊 通過函式 ,結合當前輸入 通過函式 共同合成。
- 的產出:將最新的 通過函式 轉換後得到最終輸出。
- 對 Hidden State 的誤解與彈性:
- 記憶空間:許多人誤以為 RNN 的 Hidden State 只能是存儲量極少的向量,但實際上它也可以被設計成一個巨大的矩陣,具備儲存大量資訊的潛力。
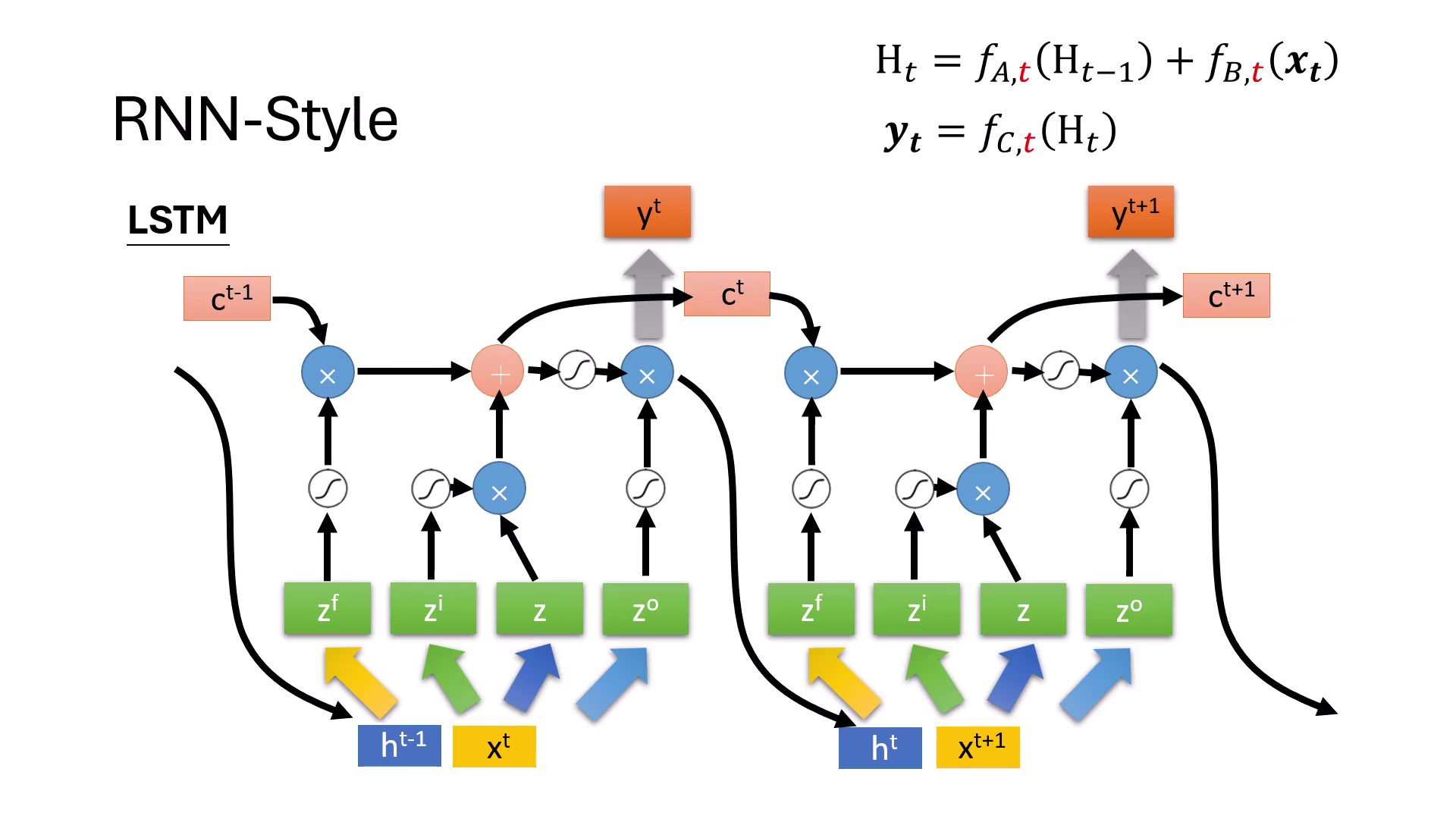
- 動態調整 (Gates):函式 可以隨時間(即隨輸入 的不同)而動態變化。例如,當模型偵測到換行符號時, 可執行「清除」動作;若資訊不重要, 則會「關閉書寫」以節省儲存空間,這正是 LSTM 或 GRU(具備 Gate 機制)的設計原理。
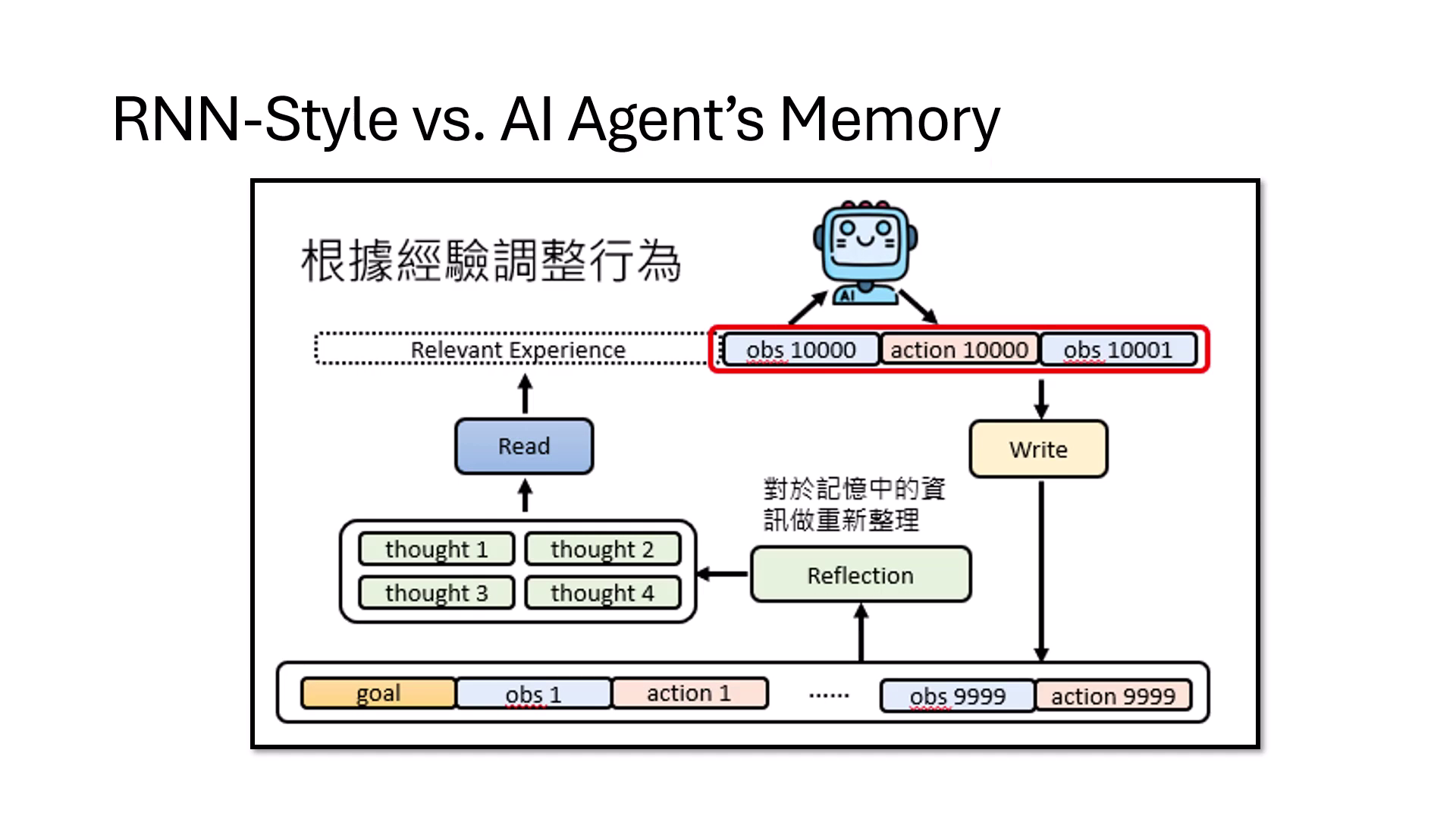
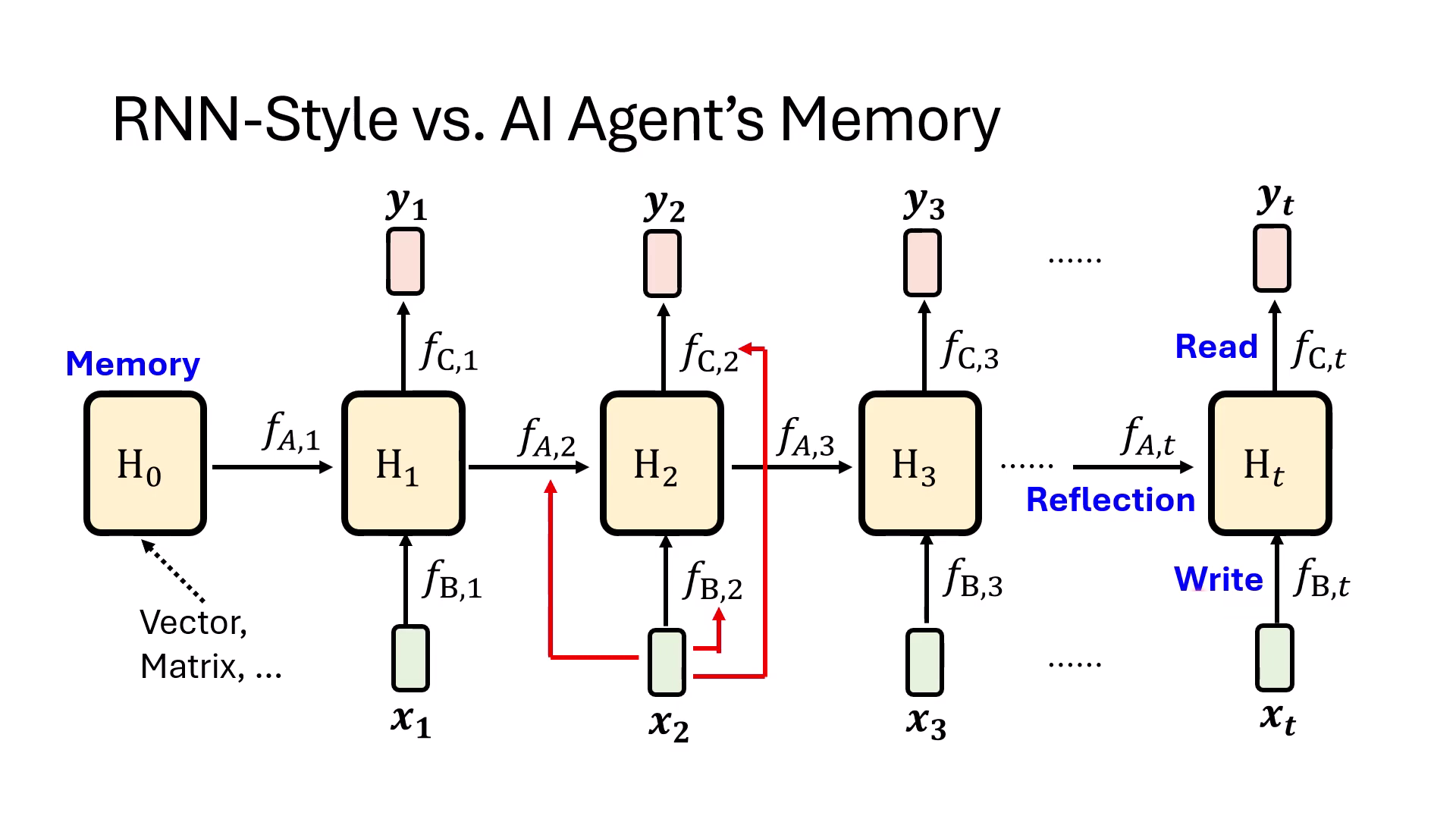
- 對應 AI Agent 的記憶模組:RNN 的架構運作可精準對應到 AI Agent 的行為:
- (Hidden State) 對應 Memory:負責儲存長期資訊。
- 對應 Write:決定哪些新資訊要寫入記憶。
- 對應 Read:決定從記憶中讀取哪些資訊來進行決策。
- 對應 Reflection:決定記憶中的資訊如何重新整理、過濾或遺忘。
AI Agent 的記憶模組 RNN的架構可以對應到AI Agent的行為
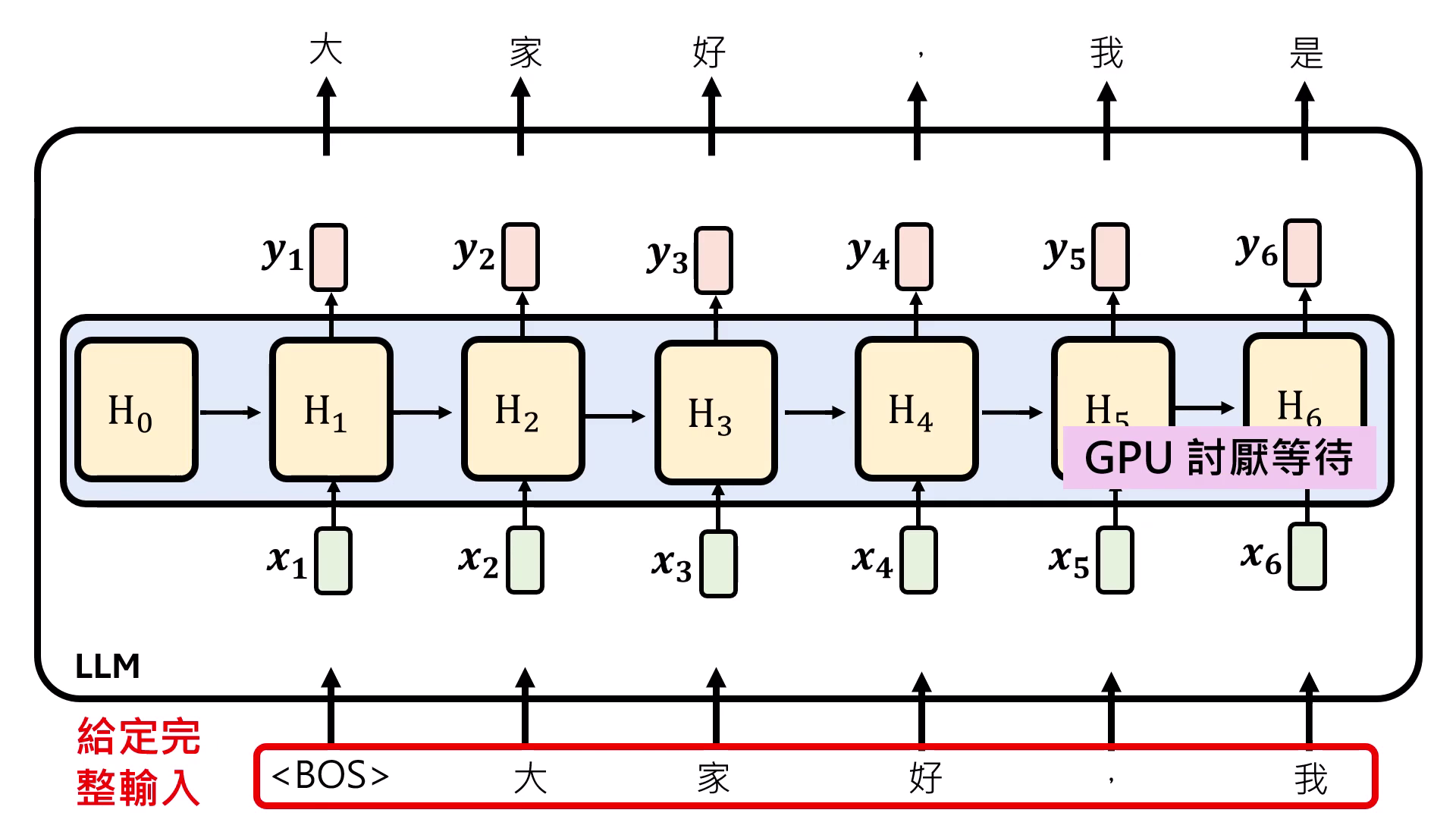
- 推論優勢與侷限:在推論 (Inference) 階段,RNN 每一步的運算量是固定的,且只需記住前一個時間點的 ,因此對記憶體需求極低。然而,由於 必須等待 算完才能進行,這導致其在訓練階段難以平行化運算,無法有效發揮 GPU 的效能。
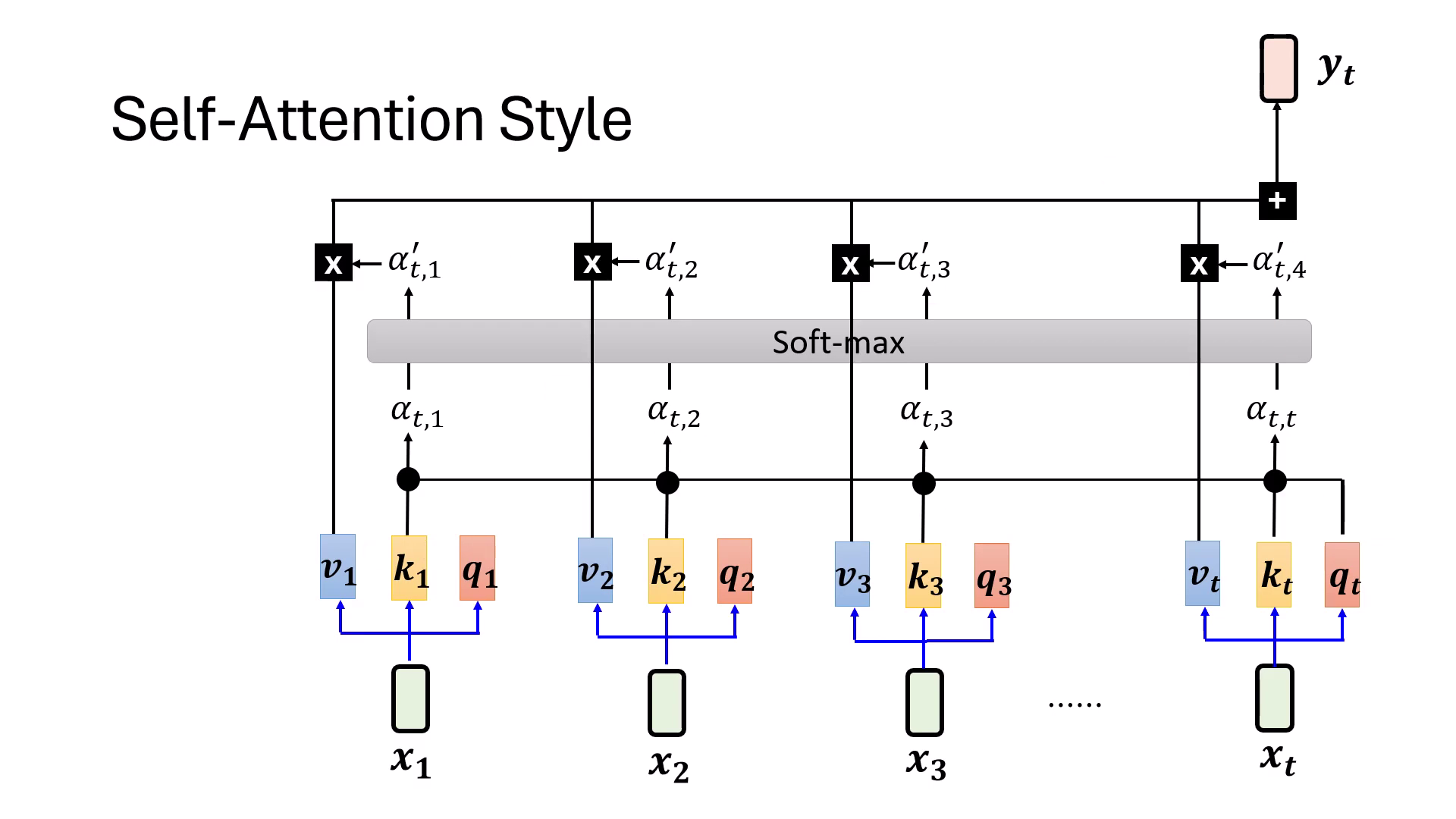
Self-Attention Style 的設計與運作
- QKV 運作機制:每個輸入向量 會乘上三個不同的轉換矩陣,分別產生 (Query)、 (Key) 與 (Value)。在計算時間點 的輸出 時,會拿當下的 與所有位置的 做內積,得到 Attention Weight ()。
- Softmax 的關鍵作用:內積後的權重會通過 Softmax 函式進行正規化。Softmax 的妙用在於能根據當前序列中「誰更重要」來動態調整權重;當出現更重要的資訊時,舊資訊的權重會相對變小,進而達成記憶的動態更新與遺忘。最後將處理後的權重與各位置的 做加權總合 (Weighted Sum) 得到輸出。
- 訓練優勢:高度平行化與 GPU 友好:這是 Transformer 能取代 RNN 的核心理由。不同於 RNN 必須等待前一個狀態算完,Self-Attention 可以一次性輸入完整的序列,並透過矩陣運算同時平行算出每個時間點的結果。這種設計能最大化發揮 GPU 的運算效能,大幅縮短訓練時間。
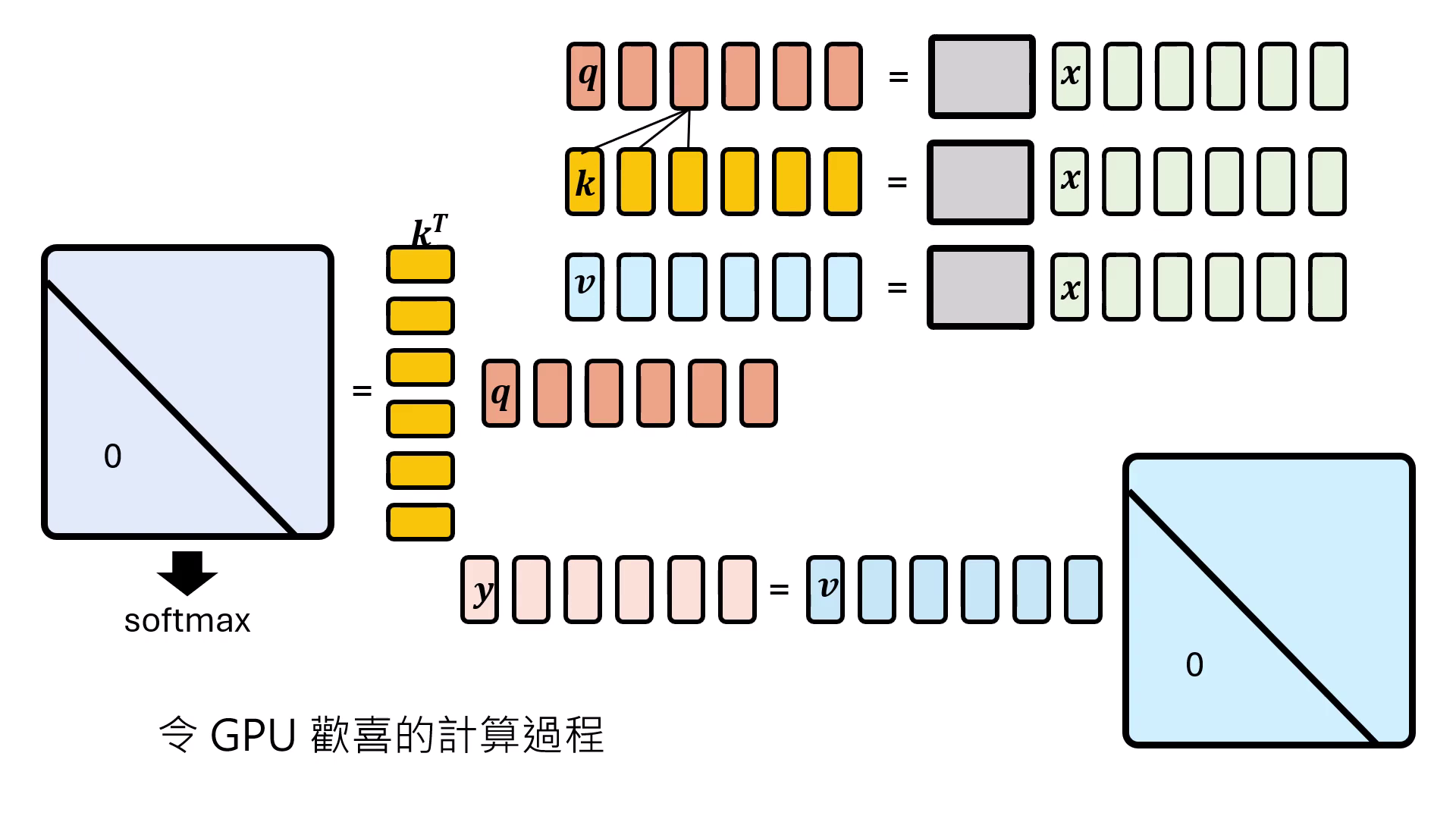
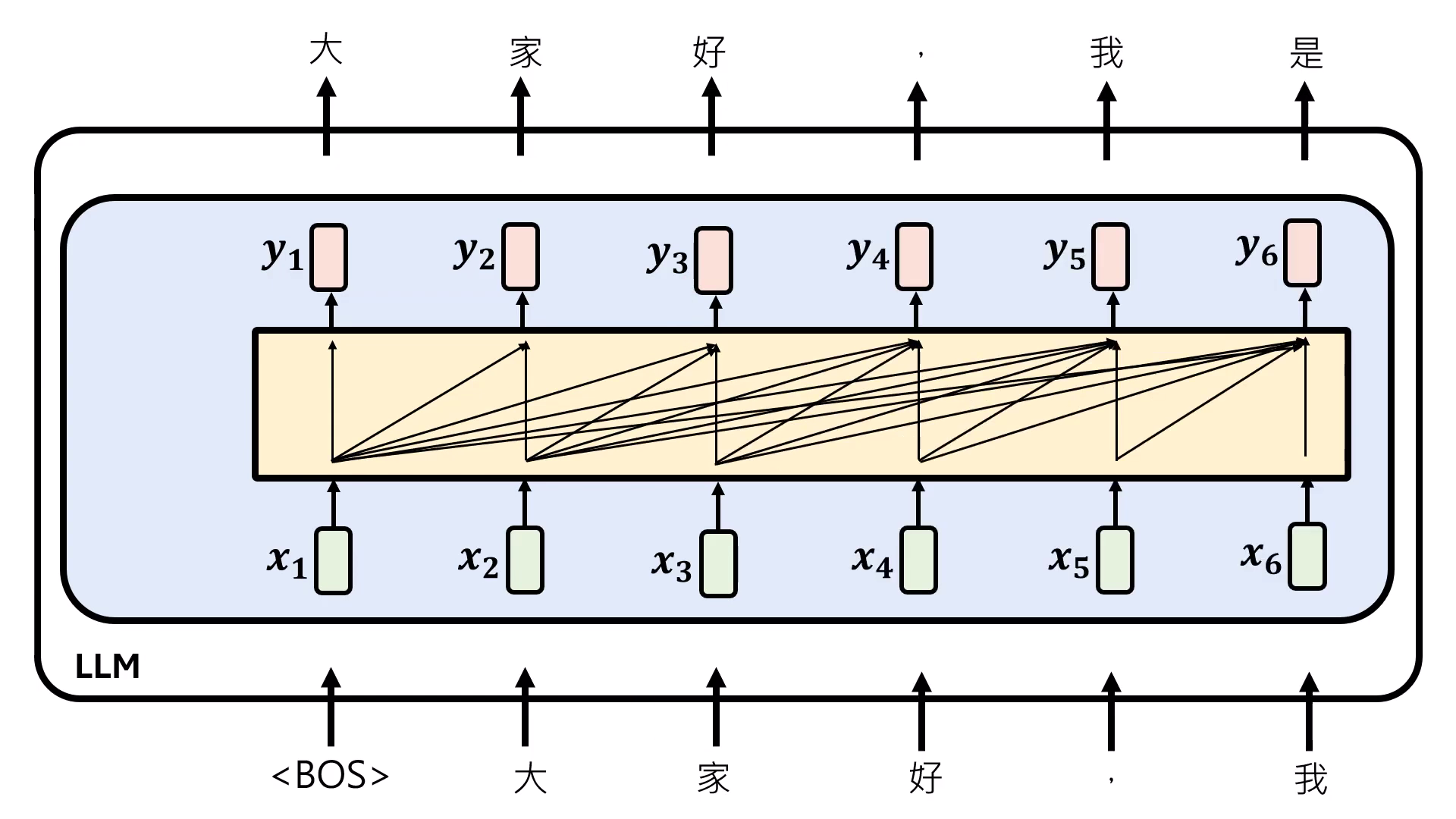
- 推論劣勢:運算量與記憶體需求遞增:在生成(Inference)階段,Self-Attention 必須記住前面出現過的所有 才能產生新的輸出,非常耗費記憶體。且隨著序列越往後,需要計算的箭頭(對比次數)越多,運算量會隨序列長度增加而膨脹。
Self-Attention vs. RNN 的權衡
- 推論 (Inference) 階段:
- RNN:每一步運算量固定,且只需記得前一個時間點的 ,記憶體需求較低。
- Self-Attention:越往後運算量越大,且必須記住前面所有的 才能產生新輸出,極度耗費記憶體。
- 訓練 (Training) 階段:
- RNN:難以平行化,必須等前面的 算完才能算後面的,GPU 效率低。
- Self-Attention:GPU 友好,可以一次輸入完整序列並平行算出每個時間點的答案,大幅加速訓練�。
| Self-Attention | RNN | |
|---|---|---|
| Inference | 計算量、記憶體需求隨序列長度增加 | 計算量、記憶體需求固定 |
| Training | 容易平行化 | 難以平行化(?) |
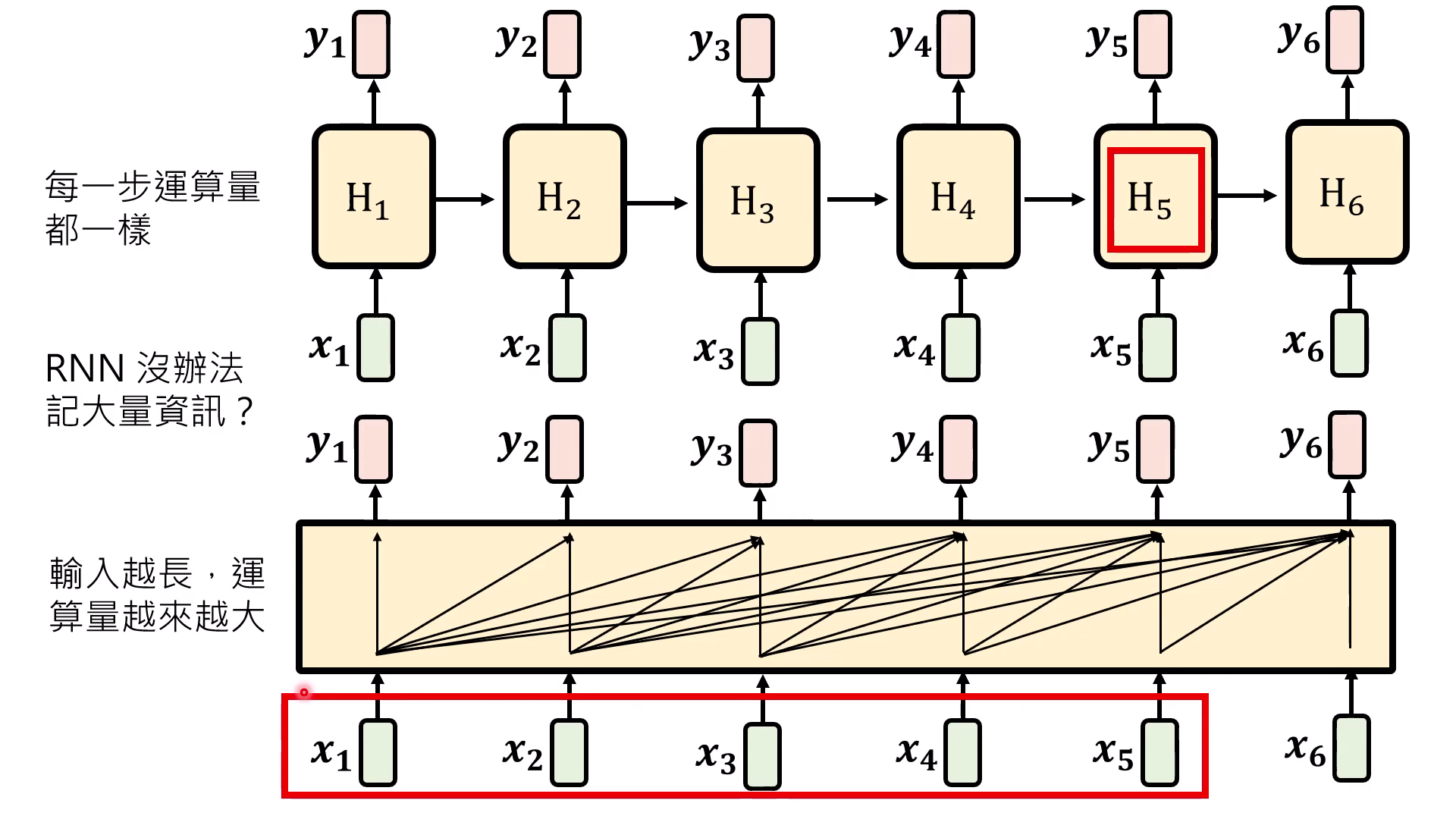
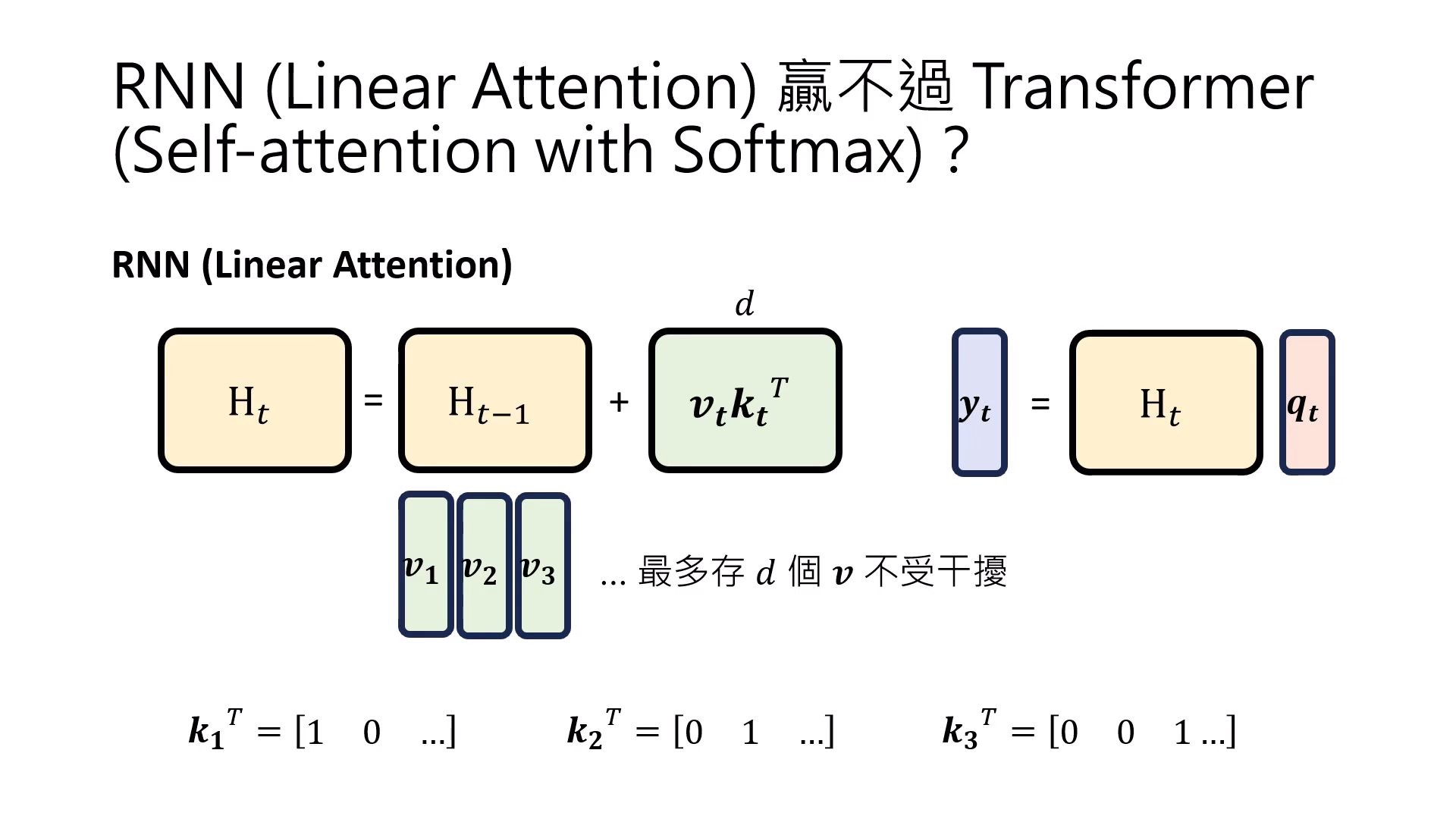
RNN 訓練平行化的可能性
- 展開式與 的瓶頸:若將 RNN 的數學式展開,會發現計算到後面的時間點(如 )時,輸入資訊必須通過一連串連續的 (Reflection/反思函式) 呼叫。這種長鏈的連續依賴性導致 GPU 必須等待前一個函式計算完成後才能進行下一步,因此在結構上難以平行化。

- 移除 簡化運算:拿掉負責 Reflection 的 後,Hidden State () 簡化為所有輸入項經過 處理後的加總結果。此舉消除了連續函式呼叫的長鏈依賴,使模型計算不再受限於前一狀態的產出,從而具備平行化的基礎。

- 序列的生成邏輯:在移除 的架構下,輸出 是當前 Query () 與先前所有輸入累積和的乘積。具體運算為 、、,這代表輸出是從過去記憶的加總中提取資訊。

- 移除 就是 Linear Attention:研究發現若將負責 Reflection 的 函式移除,Hidden State () 就會簡化為所有輸入項經過 處理後的加總運算。透過線性代數的重組,這個結構在數學上會等同於「沒有 Softmax 的 Self-Attention」,也就是所謂的 Linear Attention。

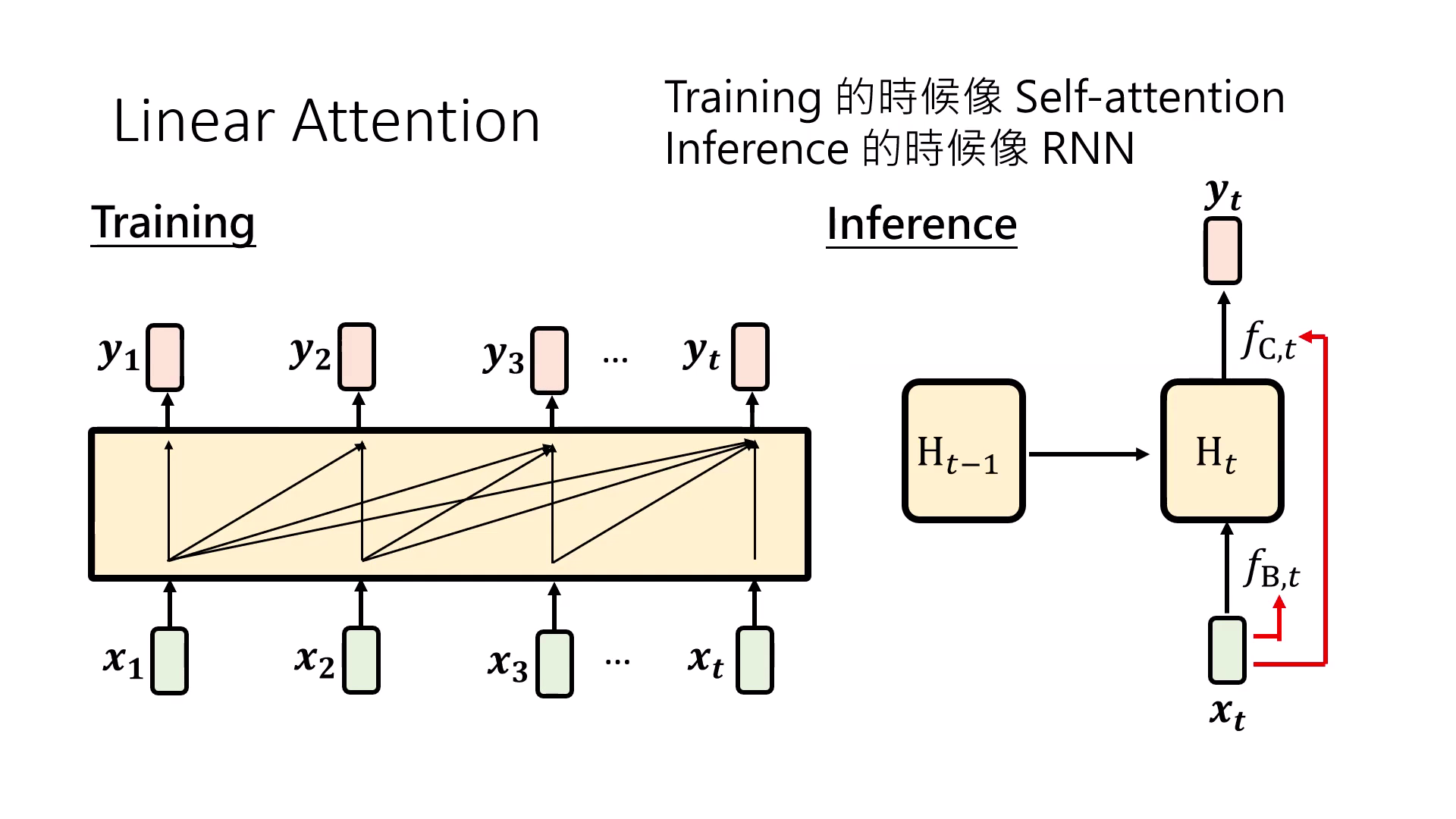
Linear Attention:RNN 與 Attention 的橋樑
研究發現,若將 RNN 展開並移除負責 Reflection 的 函式,其數學形式可以簡化並重組成與 Self-Attention 極為相似的結構:
- 定義:Linear Attention 其實就是沒有 Softmax 的 Self-Attention,也等同於沒有 Reflection 運算的 RNN。
- GPU 友好的設計:它兼具兩者優點,在訓練時可以像 Transformer 一樣平行加速,在推論時則像 RNN 一樣具備固定的運算與記憶體需求。
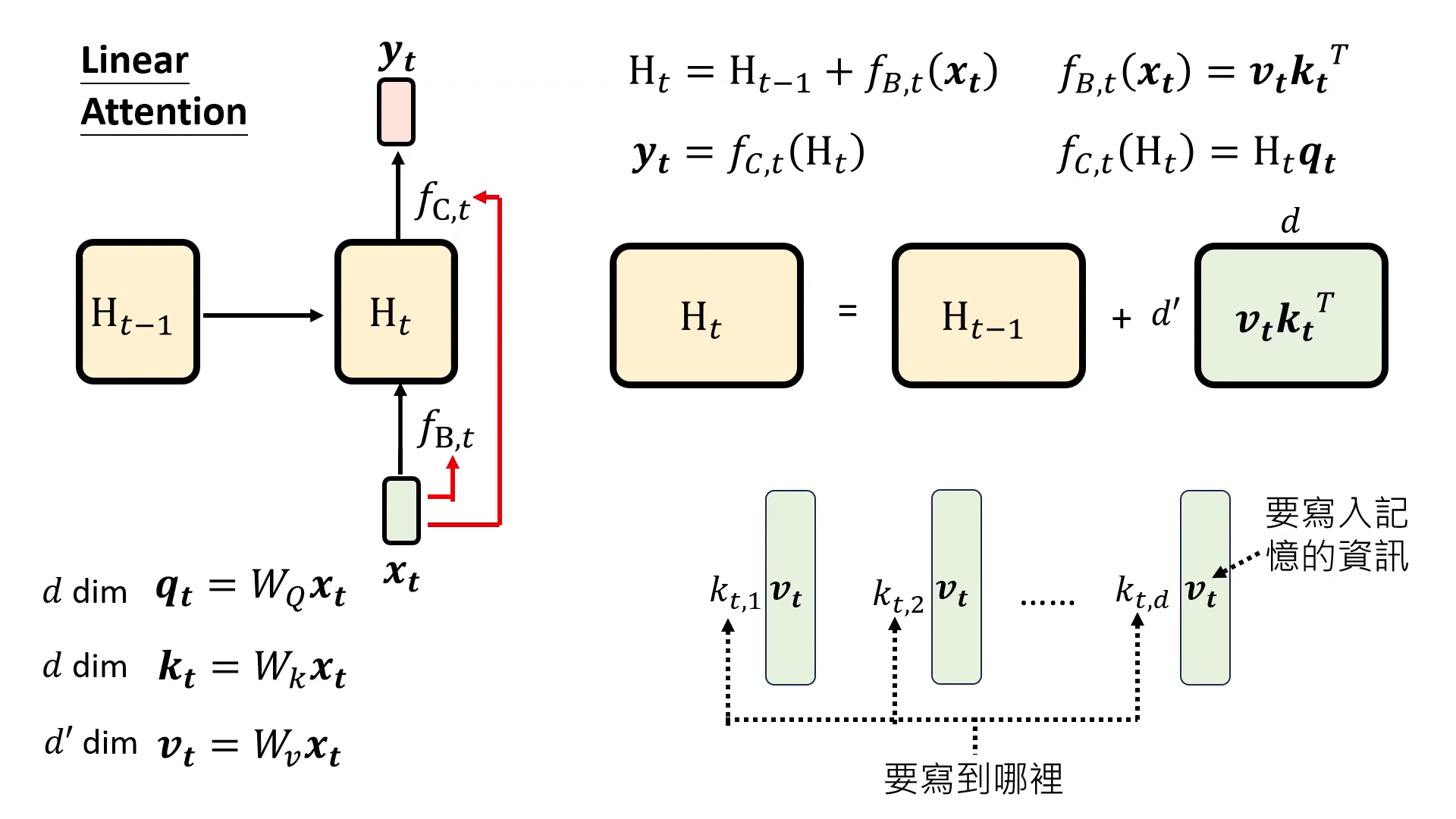
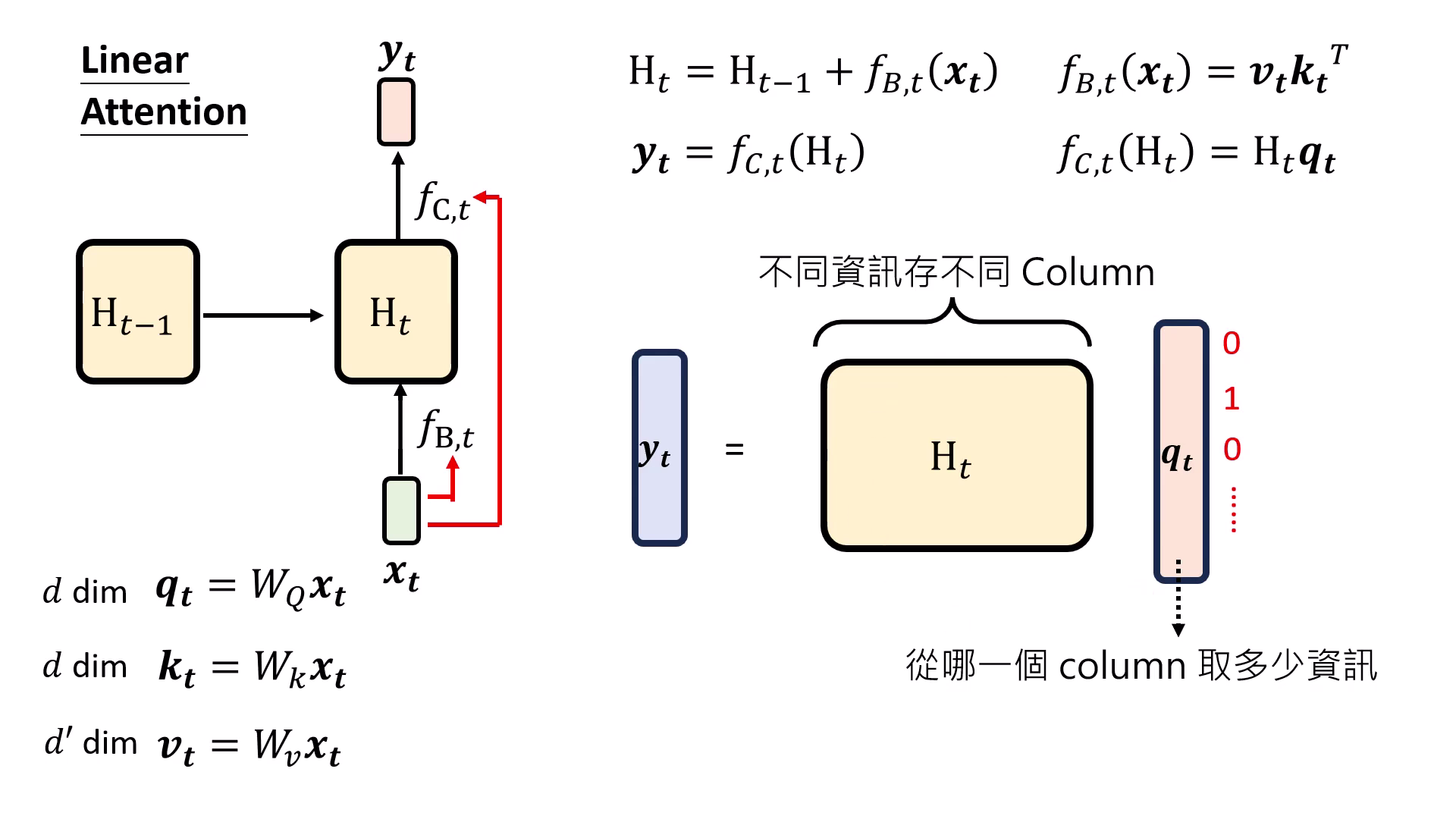
- 直觀解釋: 是預計寫入記憶的資訊, 決定寫到哪裡(哪個 Column),而 則決定從記憶中取回多少資訊。
 |  |
|---|---|
| 決定 要寫到哪裡 | 決定從記憶中取回哪些資訊 |
Self-Attention 的記憶限制與 Softmax 的關鍵性
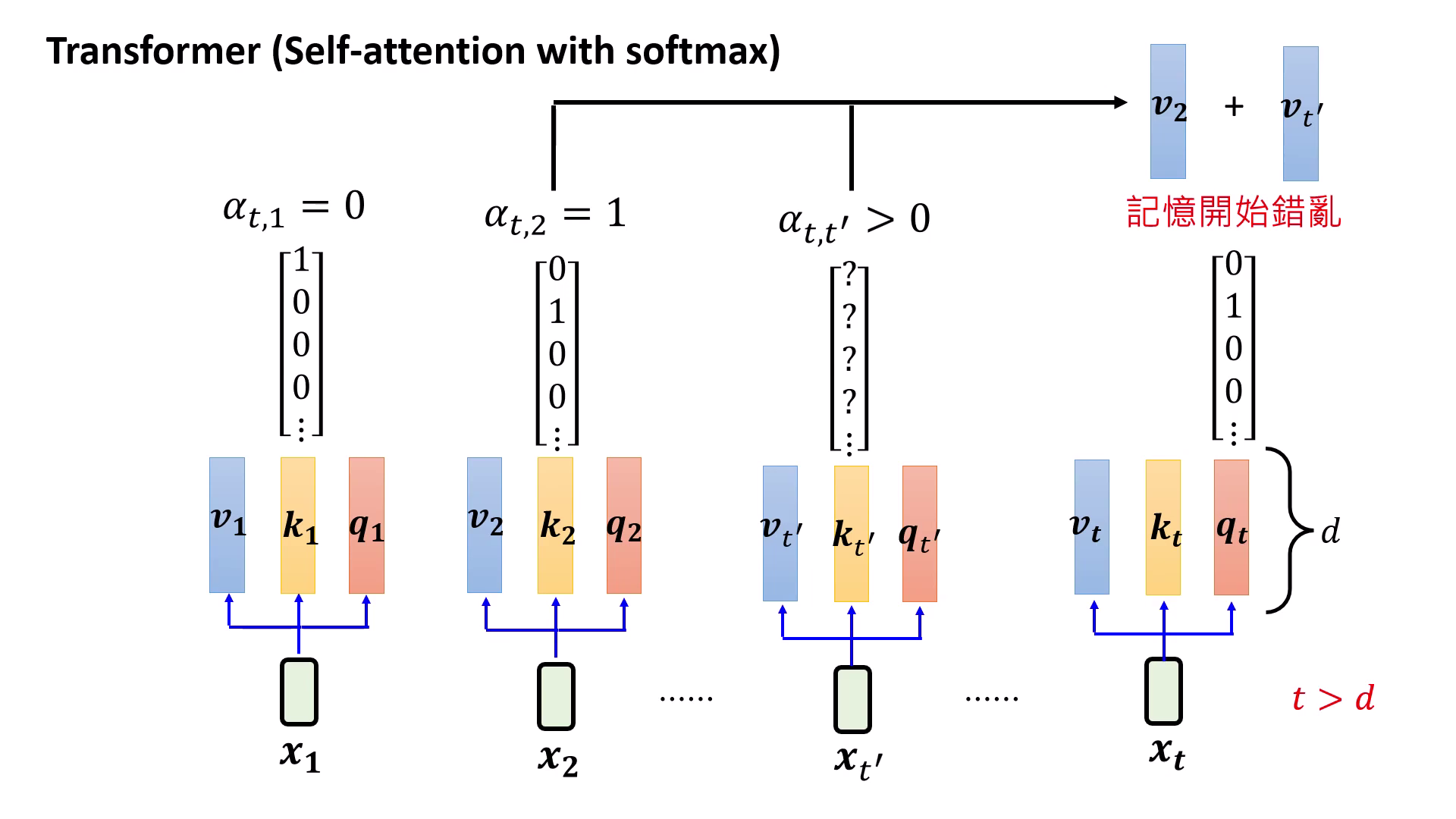
Self-Attention 不是無限記憶
- Transformer 的記憶並非無窮:雖然 Self-Attention 被認為能回顧極長資訊,但這在數學上其實是個假象。
- 線性代數的空間限制:當輸入序列長度 () 超過向量維度 () 時,模型無法在有限的低維空間中找到足夠的正交向量來精確區分每一個位置。
- 資訊重疊與干擾:在 的狀態下,模型提取資訊時會因向量無法正交而導致不同位置的資訊重疊,最終造成記憶錯亂與干擾。
 |  |
|---|---|
| RNN 最多 個 不受干擾 | Self-Attention > 的時候也會造成干擾 |
Softmax 帶來的動態記憶更新
- Linear Attention 的靜態弱點:缺乏 Softmax 的架構(如 RNN 流派)最大的問題在於記憶寫入後「永不改變」,資訊一旦進入 Hidden State 就會一直存在,缺乏有效的過濾機制。
- 重要性的相對化:Softmax 的妙用在於讓每一件事的重要性變成是「��相對於全域」而言的;它能根據當前序列動態決定哪些資訊目前最關鍵。
- 動態遺忘與更新效果:一旦序列中出現更重要的新資訊,舊記憶的權重會經由 Softmax 正規化而相對變小,這讓模型在不改動儲存內容的情況下,達成類似「遺忘」舊資訊並優先處理新資訊的動態更新效果。

記憶更新與 Reflection
為了讓 Linear Attention 具備「記憶改變」的能力,研究者將先前為了平行化而移除的 Reflection(反思/遺忘) 機制重新引入,使模型能透過「逐漸遺忘」來動態調整記憶內容:
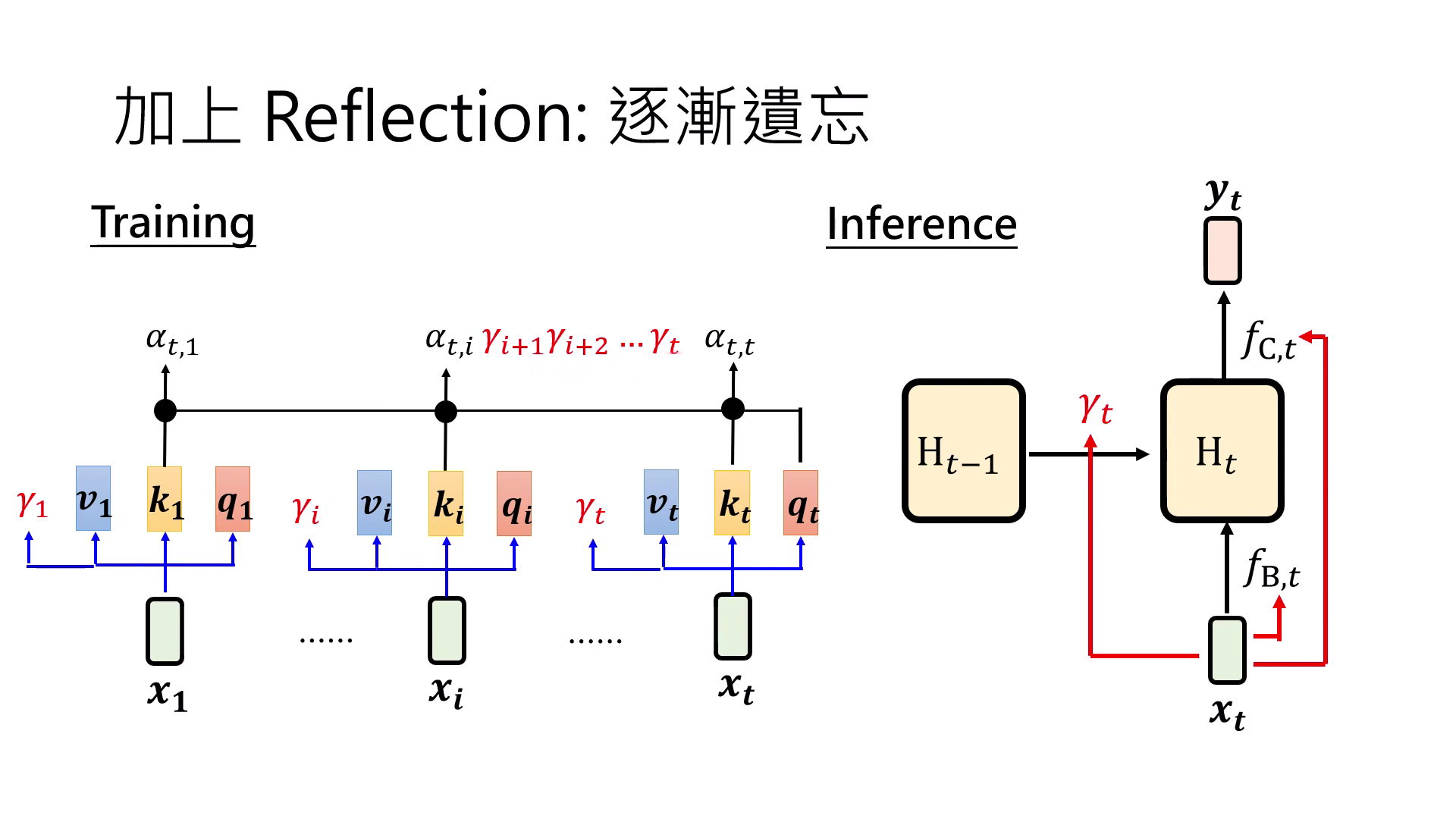
- Retention Network (RetNet):加入常數項讓記憶逐漸淡忘。
- Gated Retention / Mamba:將遺忘係數改為由模型學出來的 ,讓模型自行決定何時清空或保留記憶。Mamba 是首個在大規模測試中能微幅勝過 Transformer 的 Linear Attention 架構。
- DeltaNet:將記憶更新的過程看作是 Gradient Descent(梯度下降)。它在存入新資訊前會先嘗試清空舊位置的資訊,這也是 Titan 模型(Learning to Memorize at Test Time)的核心概念。
 |  |
|---|---|
| 加上 Reflection 逐漸遺忘 | DeltaNet 把記憶更新的過程看作是 Gradient Descent |
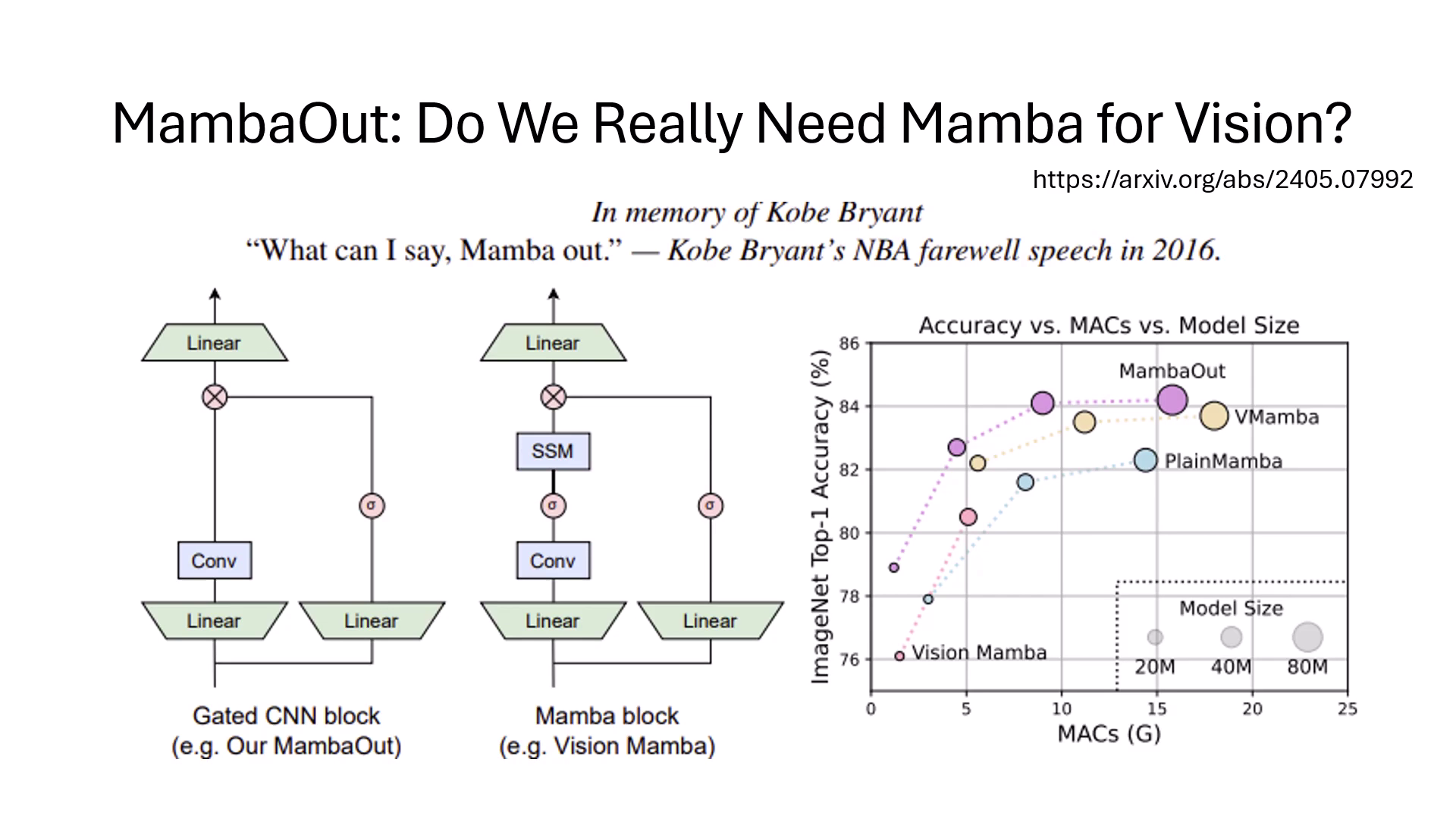
何時需要 Mamba?影像任務中的架構取捨
- MambaOut 的核心發�現:實驗證實,在影像分類任務中,拔除 Mamba 或 Attention 機制後的模型表現反而更好,說明傳統 CNN 在處理此類任務時已足夠。
- 特定任務的優勢:雖然在分類任務中 Mamba 非必要,但在需要處理更複雜資訊的任務(如影像分割)中,具備 Mamba 或 Self-attention 的架構效能仍優於純 CNN 架構,顯示架構選擇應取決於任務特性。