DeepSeek-R1 這類大型語言模型是如何進行「深度思考」(Reasoning) 的?
深度思考 (Reasoning) 的定義與原理
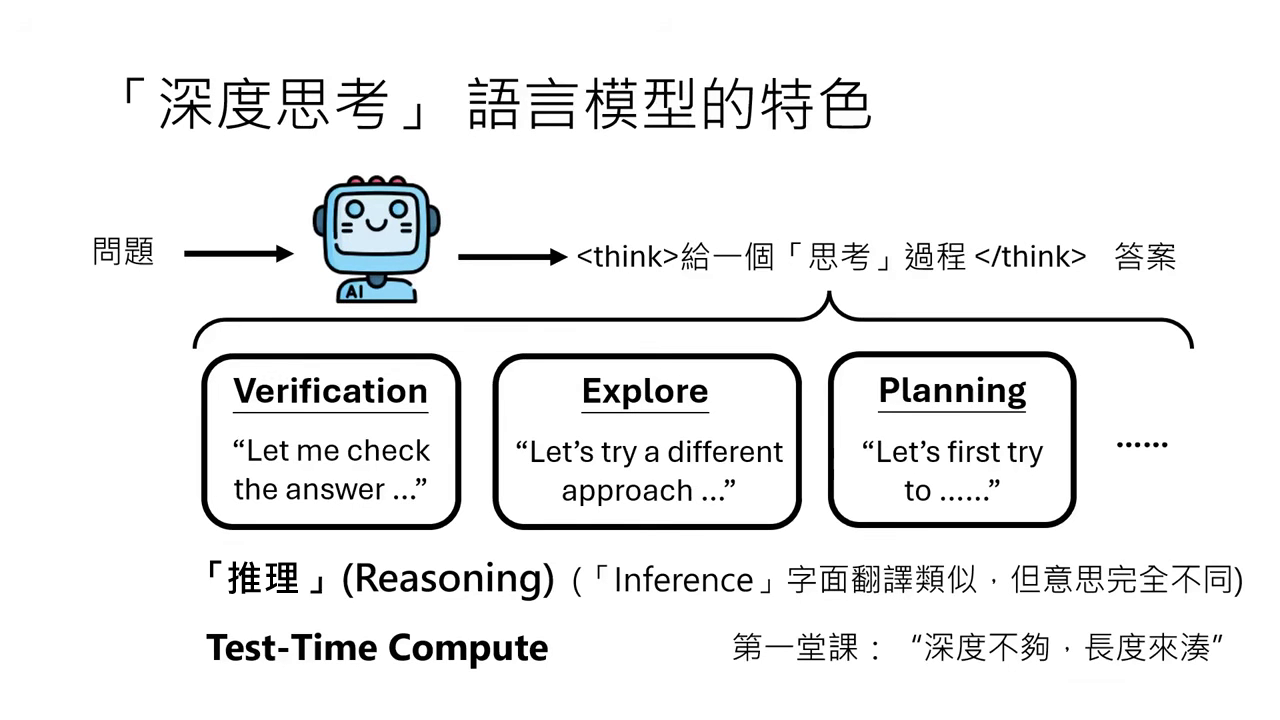
- 內心的小劇場:DeepSeek-R1、ChatGPT o1/o3 等模型在回答問題前,會先經歷一段長思考過程(如
<think>標籤內的內容)。這包含驗證(Verification)、探索(Explore)與規劃(Planning),這種行為被稱為 Reasoning(推理)。 - Reasoning vs. Inference:
- Inference(推論):指一般使用模型產生輸出的過程。
- Reasoning(推理):特指模型在 Inference 階段產生極長的思考過程。注意:這裡的「推理」不代表跟人類思考方式一樣,僅指該行為表現。
- Test-time Compute (測試時運算):
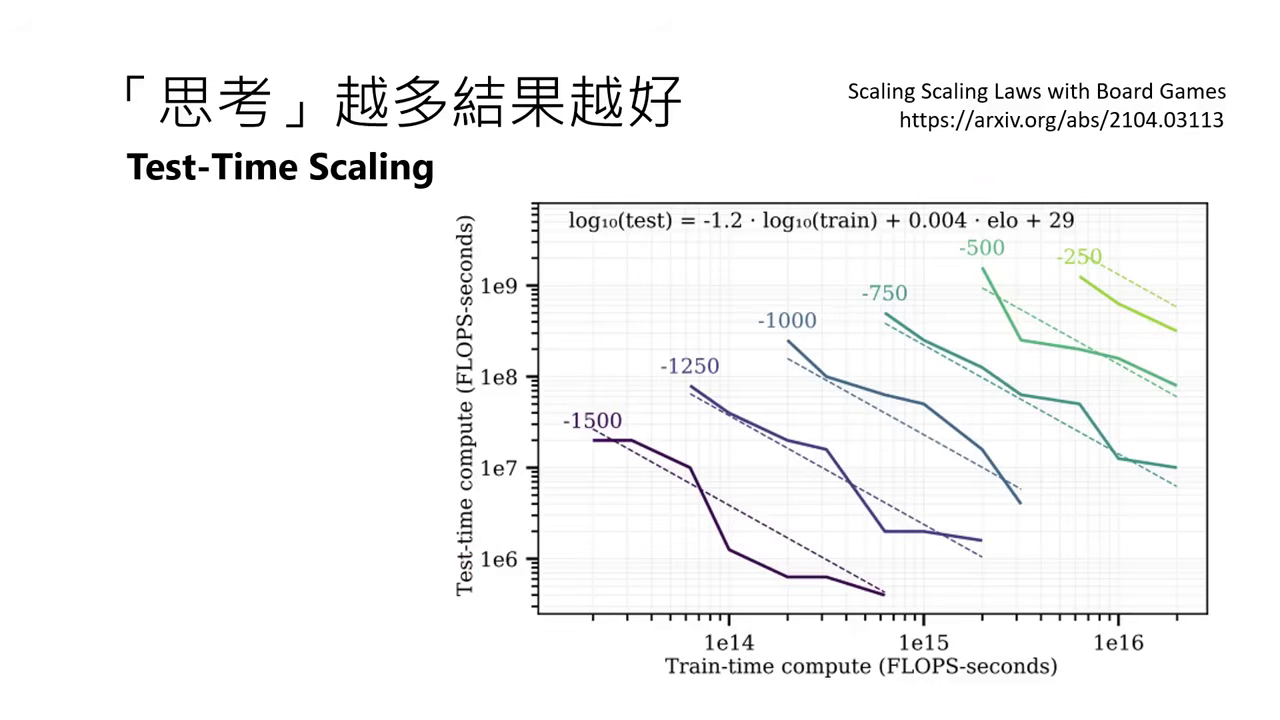
- 概念:在測試階段投入更多算力(思考更久),往往能得到更好的結果。這被稱為「深度不夠,長度來湊」。
- AlphaGo 的啟示:AlphaGo 除了訓練 Policy/Value Network,在下棋(Testing)時還使用了 Monte Carlo Tree Search (MCTS) 進行大量模擬運算。這證明了 Test-time Scaling 的潛力:用少量的測試運算資源,可以換取訓練階段需耗費巨量資源才能達到的效果。
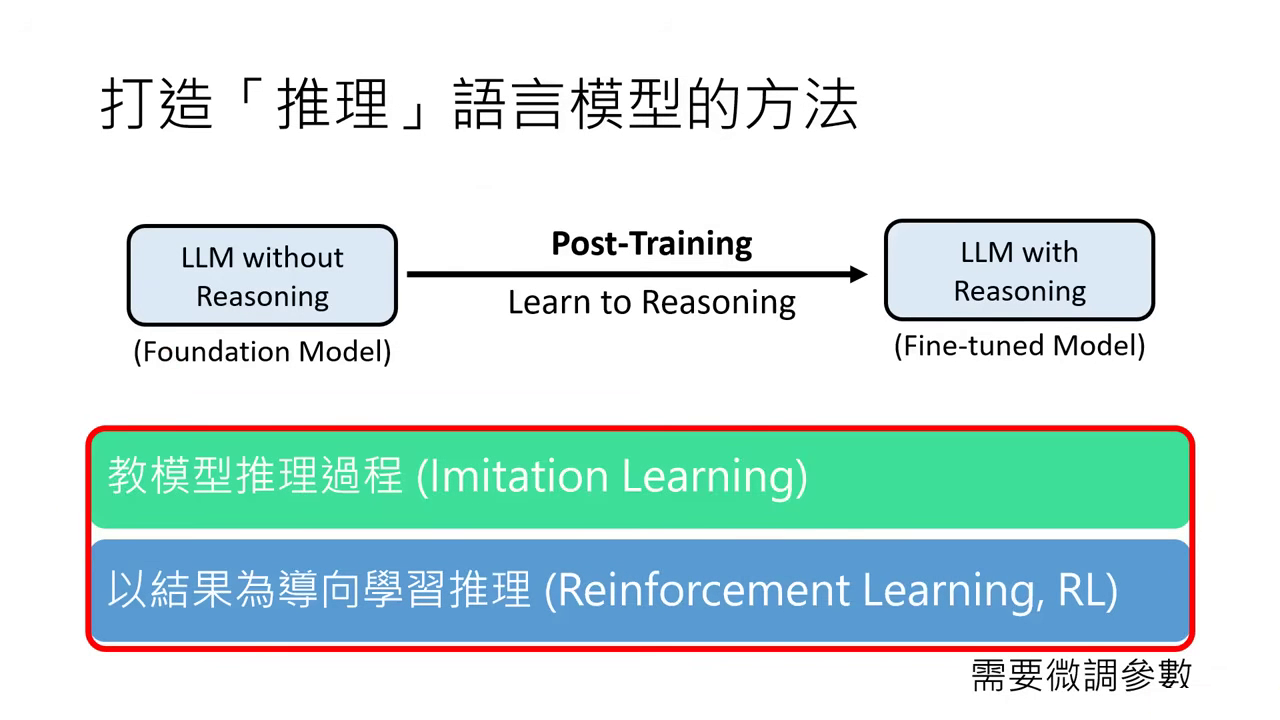
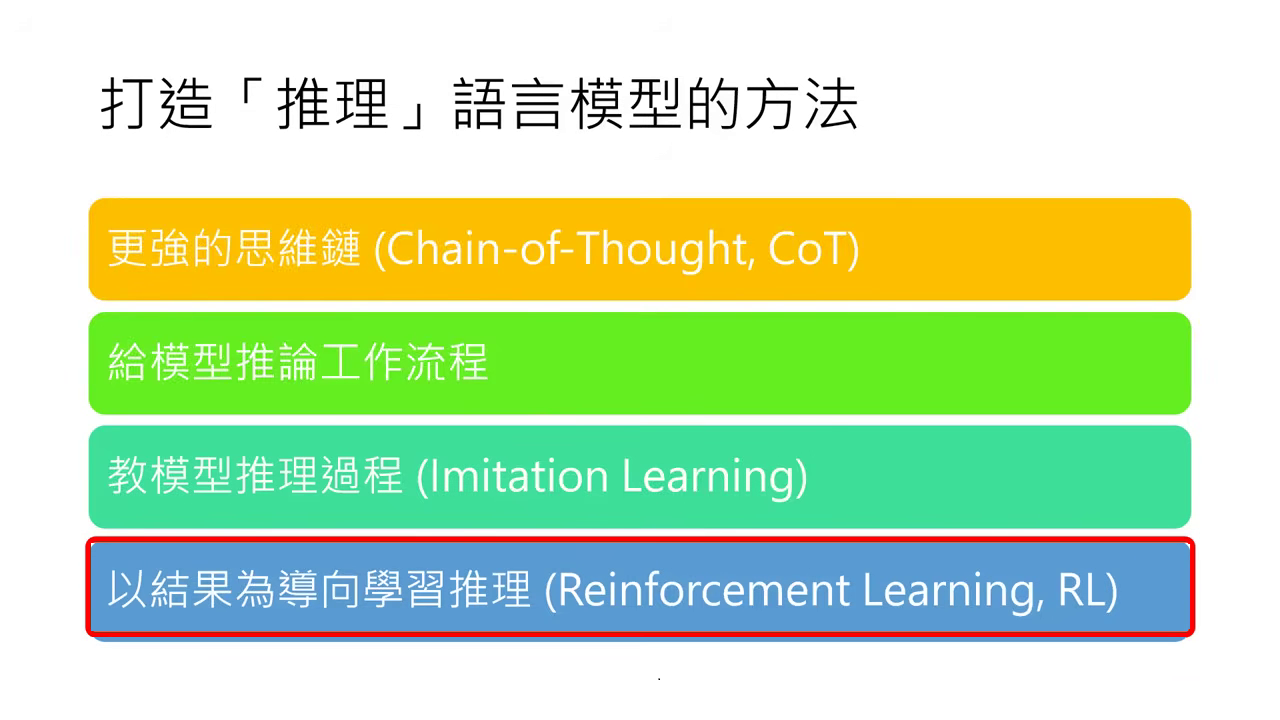
打造「推理」語言模型的方法
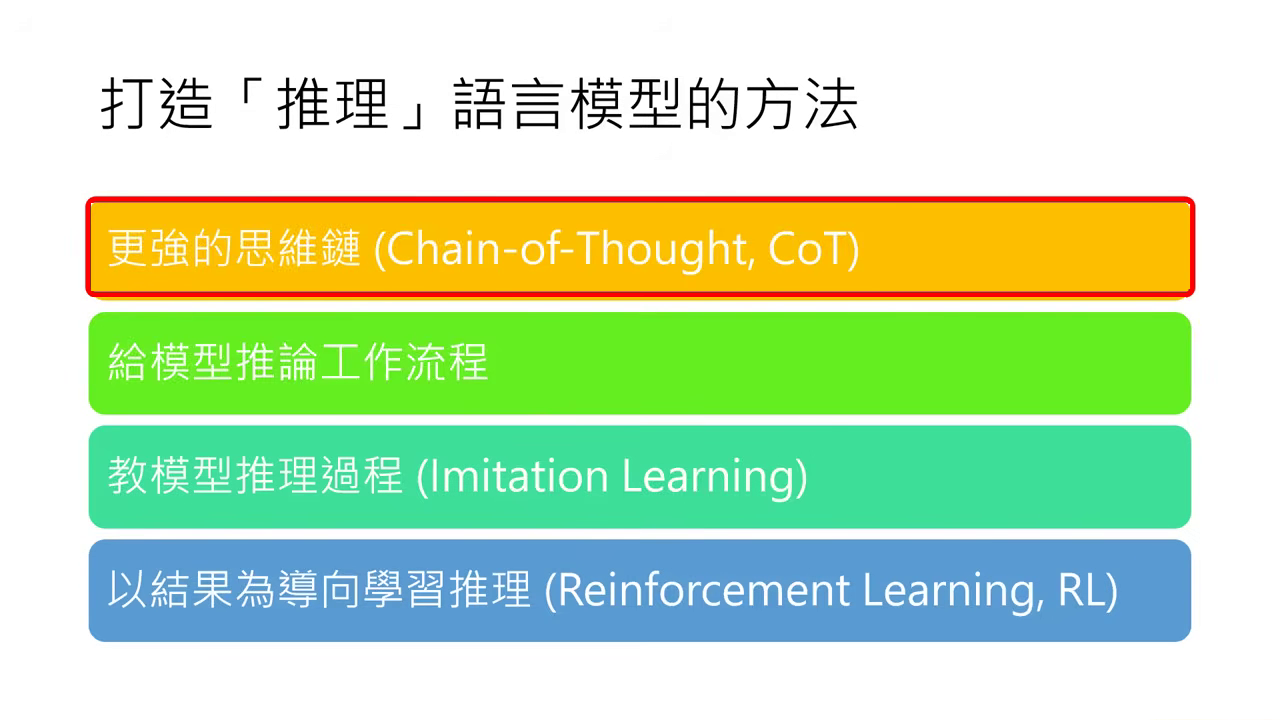
- 四種路徑的分類邏輯:我們將構建深度思考(Reasoning)模型的方法歸納為四大類,其核心區別在於是否需要對模型進行參數微調(Fine-tuning)。
- 無需微調參數:前兩種方法(更強的思維鏈 CoT、推論工作流程)適用於現有的模型,僅透過 Prompt 引導或外部演算法介入即可提升推理能力,不需更動模型權重。
- 需要微調參數:後兩種方法(Imitation Learning、Reinforcement Learning)則屬於 後訓練(Post-Training) 的範疇,需要準備特定資料來更新 Foundation Model 的參數,直接教會模型如何思考。

方法一:更強的思維鏈 (Chain-of-Thought, CoT)
此方法不需要微調參數,僅透過 Prompt 引導。
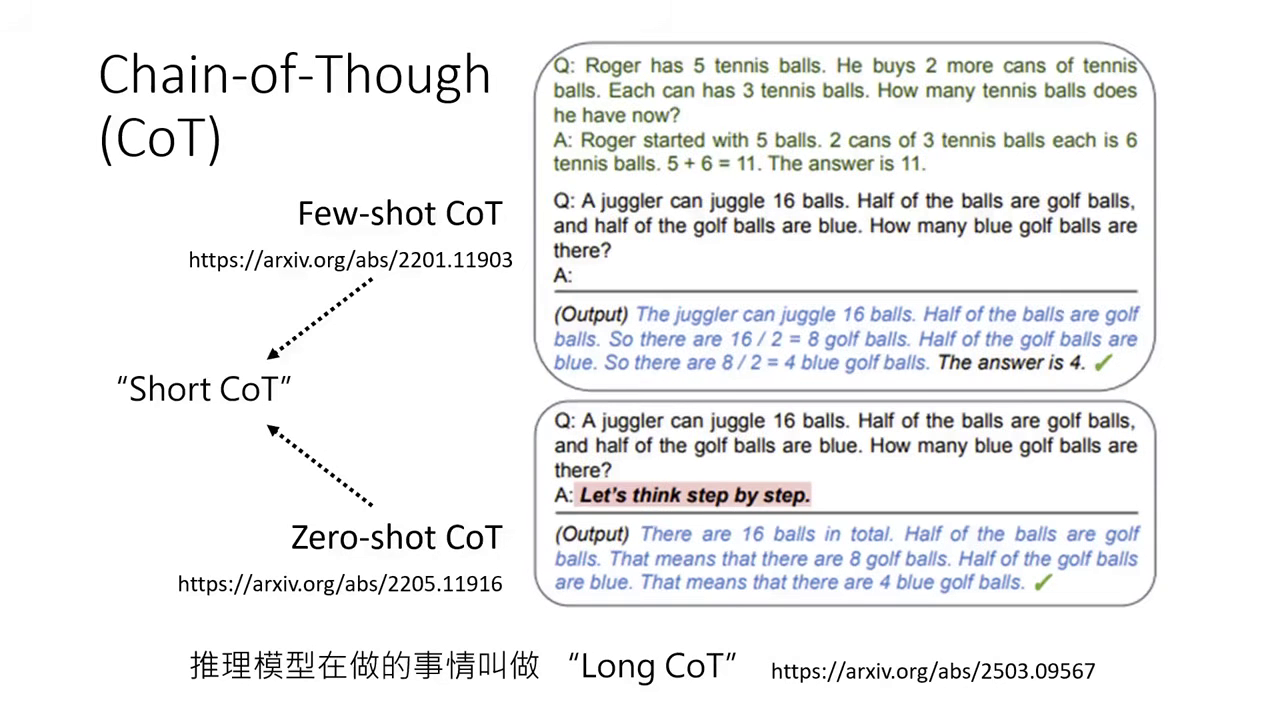
CoT 的演進
- Short CoT:包含 Few-shot(給範例)與 Zero-shot("Let's think step by step")。
- Long CoT:現今推理模型產生的思考過程極長,需透過更精確的指示激發。
Supervised CoT
- 做法:在 Prompt 中詳細規定思考流程(如:拆解計畫、執行子計畫、多次驗算、把思考放在特定標籤內)。
- 限制:只適用於較強的模型(如 GPT-4o),較弱的模型(如 Llama-3 8B)可能無法遵循複雜指令。


透過人類知識告訴模型如何思考 GPT照著流程生出計畫
方法二:給模型推論工作流程 (Inference Workflow)
此方法不需要微調參數,透過多次生成與演算法選出最佳解。

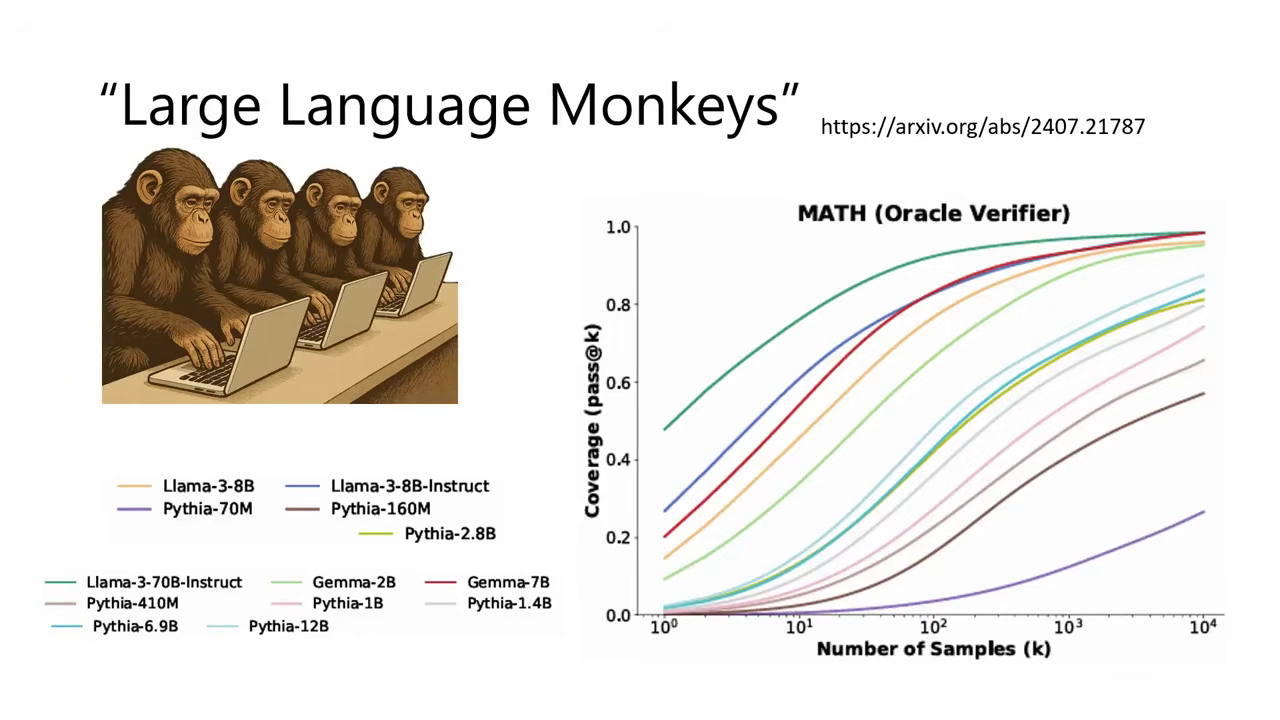
Large Language Monkeys (無限猴子理論)
- 核心概念是讓模型對同一題回答上千次,只要次數夠多,即使是較小的模型(如 1B 或 7B)也有機會「賽到」正確答案。
- 實驗顯示,只要嘗試次數(Sample counts)足夠多,模型的覆蓋率(Coverage,即至少答對一次的機率)會顯著提升,這被稱為「愚者千慮,必有一得」。
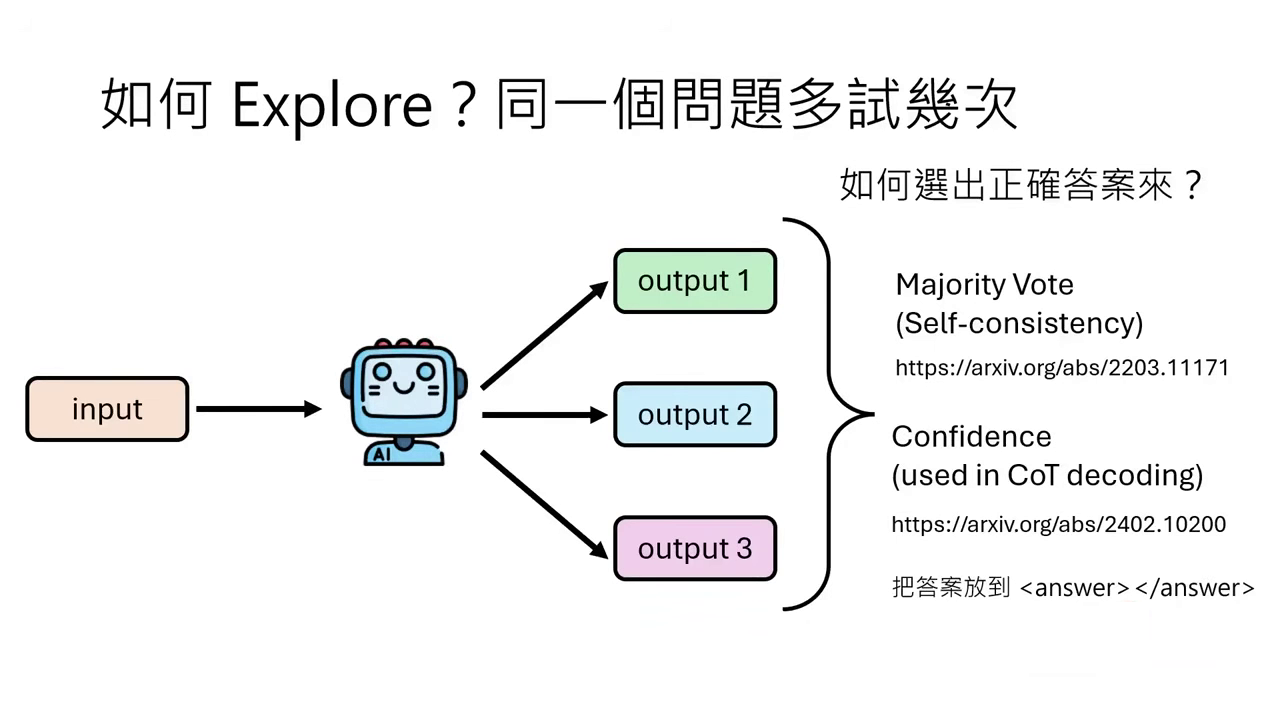
當模型產生了上千個答案,我們需要策略來挑出正確的那一個:
Majority Vote (Self-consistency)
- 運作原理:這��是最簡單且強大的 Baseline。讓模型生成多次,統計出現次數最多的答案即視為正確解。
- 實作技巧:為了方便統計,通常會在 Prompt 中強迫模型將答案夾在特定符號(如
<answer>...</answer>)中間。 - 效能表現:實驗證實,隨著生成次數增加(如從 到 次),正確率會顯著上升。雖然單靠此方法,1B 模型仍難以超越 8B 模型,但已比原本表現好上許多。
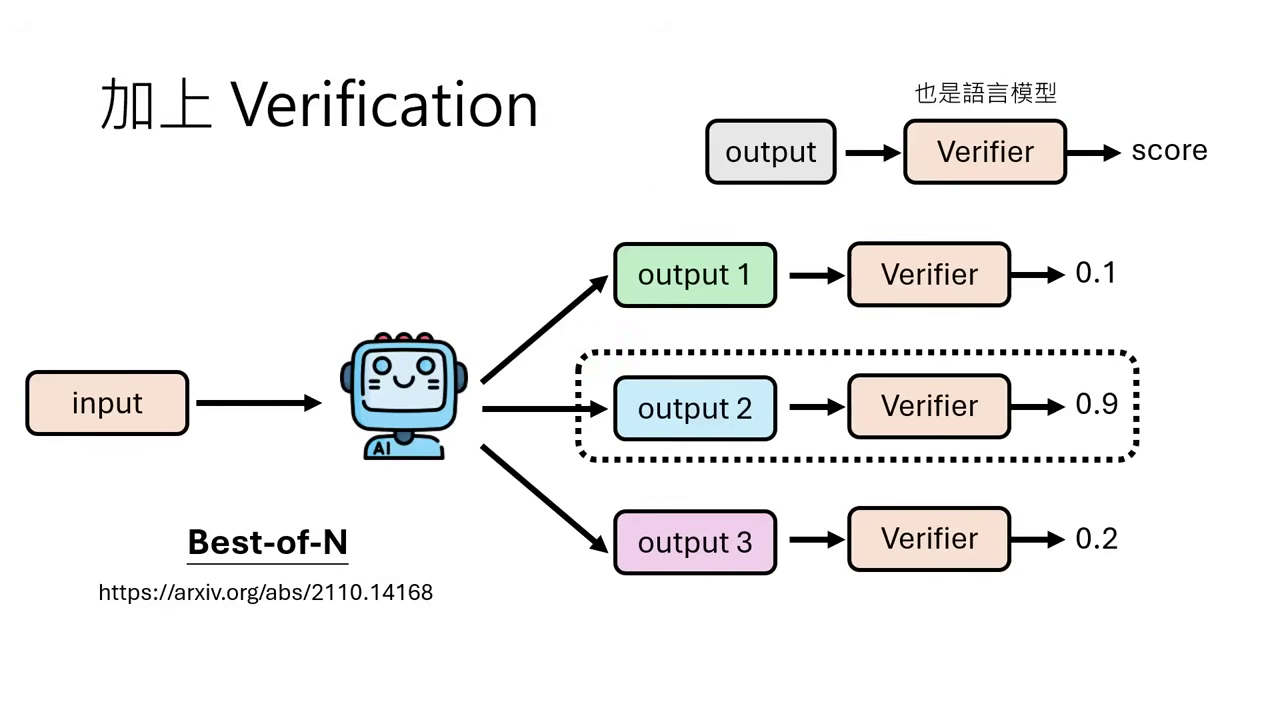
Best-of-N (Verifier)
- 運作原理:訓練一個獨立的 Verifier(驗證器) 來對模型產生的多個答案進行評分,最後選擇分數最高的那個。
- 驗證器的訓練:利用現有的問題與正確答案(Ground Truth),讓模型產生多個解。若解出的答案與標準答案相符,標記為 1(正樣本);若不符則標記為 0(負樣本)。用這些資料訓練 Verifier,讓它學會判斷哪些答案較可能是對的。
- 結果:實驗顯示 Best-of-N 的效果通常優於 Majority Vote。
除了最後選答案,我們還可以控制模型生成答案的流程與中間驗證:
Parallel vs. Sequential (並行與序列)
- Parallel:同時讓模型獨立解題多次,再從中選最好的。
- Sequential:讓模型先解一次,第二次解題時參考第一次的解法(無論是對是錯)進行修正或優化,具有迭代的概念。
- 混合策略:實務上可以同時結合兩者,例如先並行產生多個解��,再針對特定解進行序列優化。
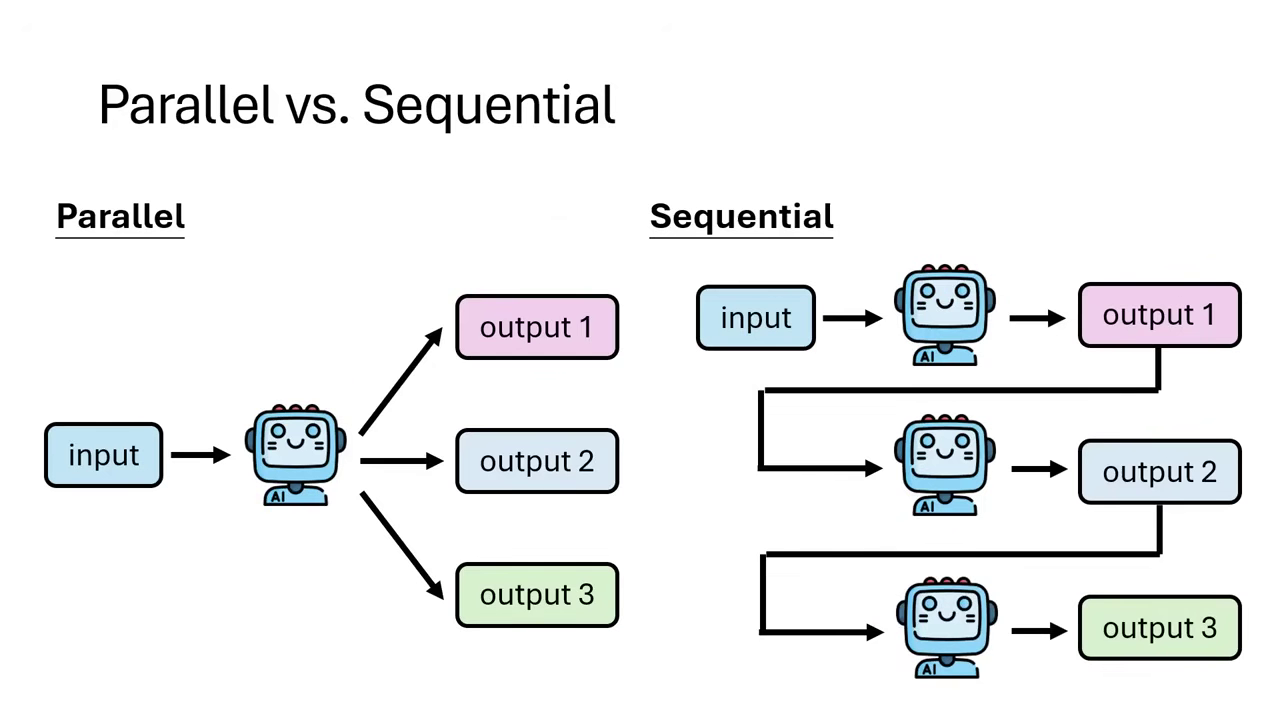
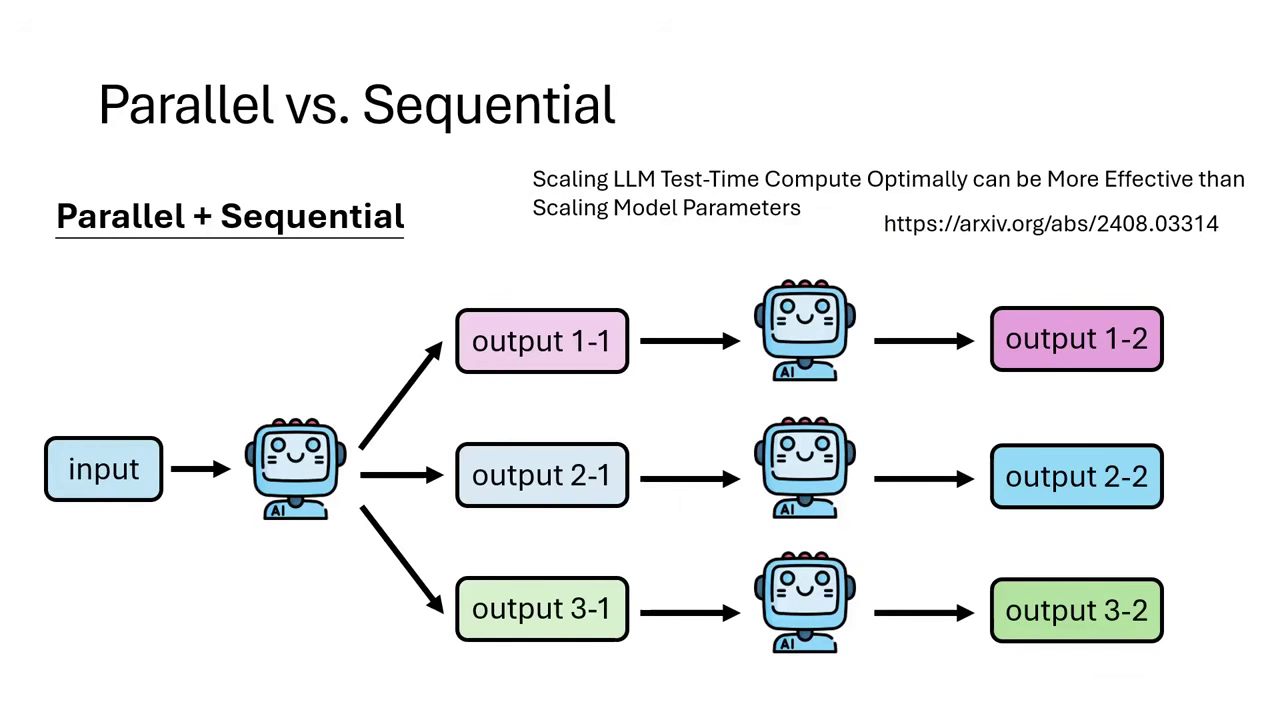
推論流程可以是並行或序列 實務上可以同時結合兩者
中間步驟驗證 (Process Verifier)
- 原理:不等到最後才驗證答案,而是在每個步驟(Step)結束時就進行驗證。若第一步就算錯,就直接停止該路徑,節省算力。
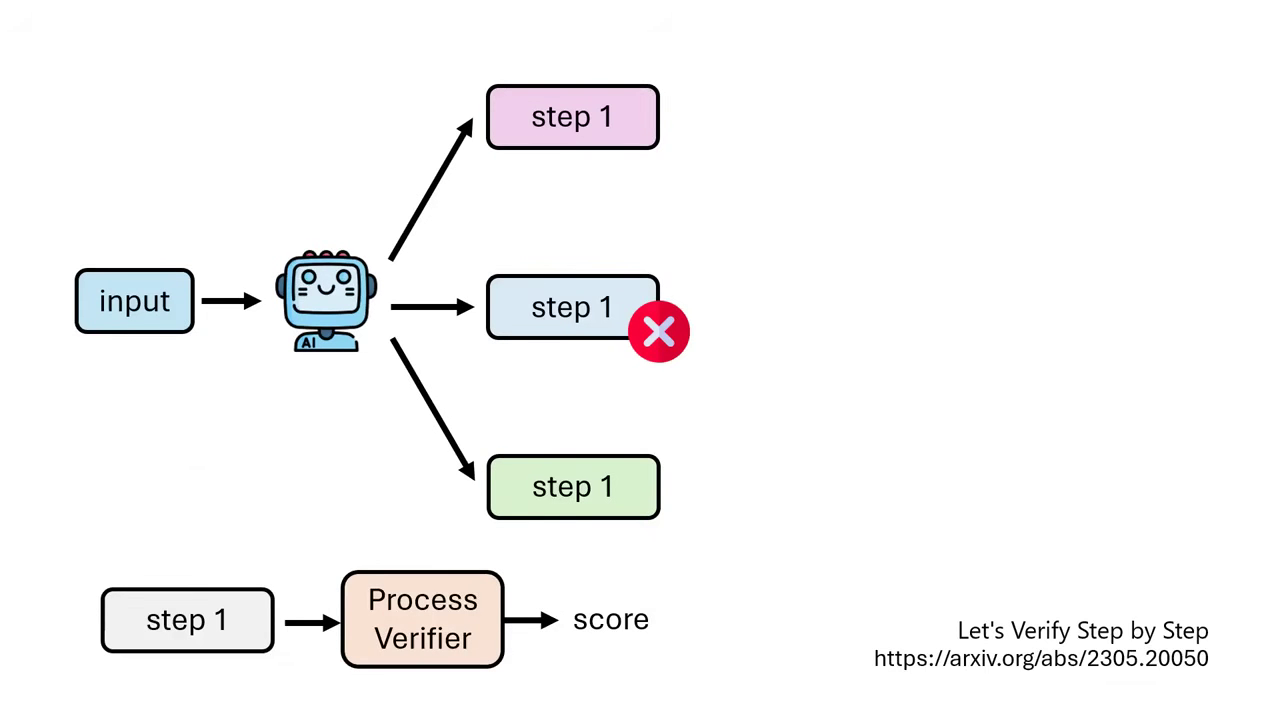
- 訓練方式:透過蒙地卡羅(Monte Carlo)模擬,讓模型從某一步驟開始多次解題,統計最終能答對的機率,以此作為該步驟的分數來訓練 Process Verifier。
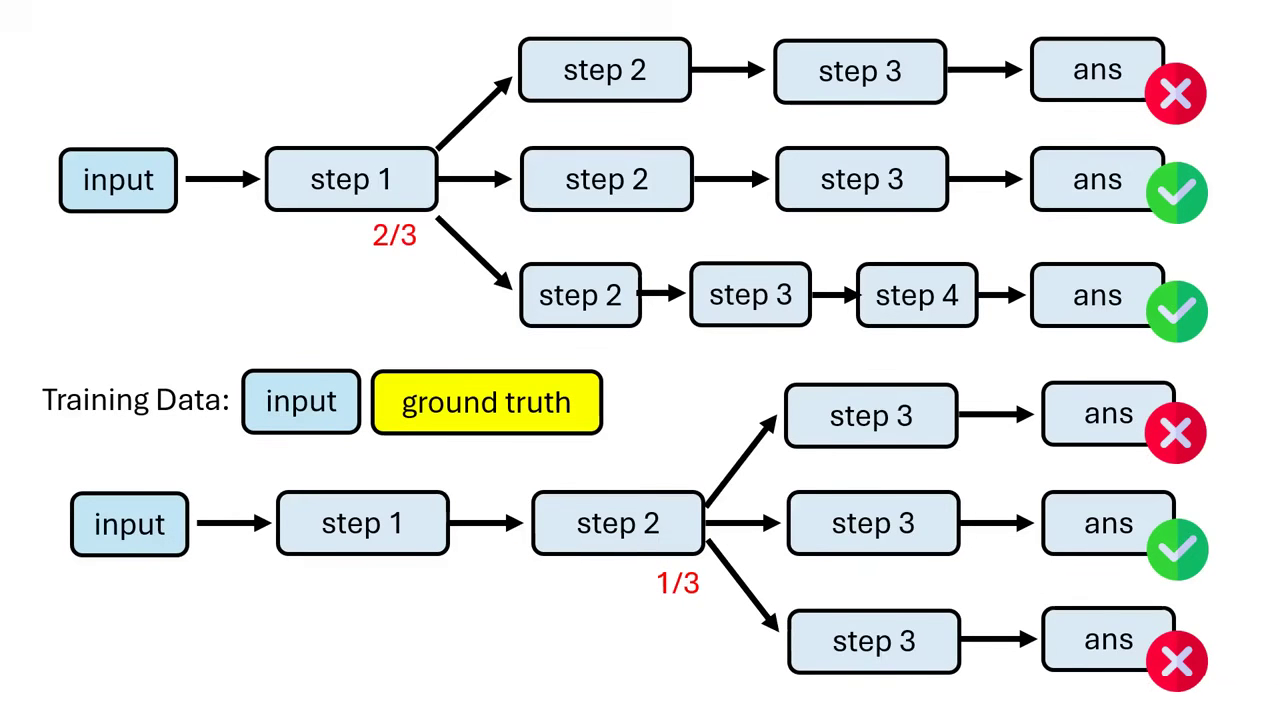
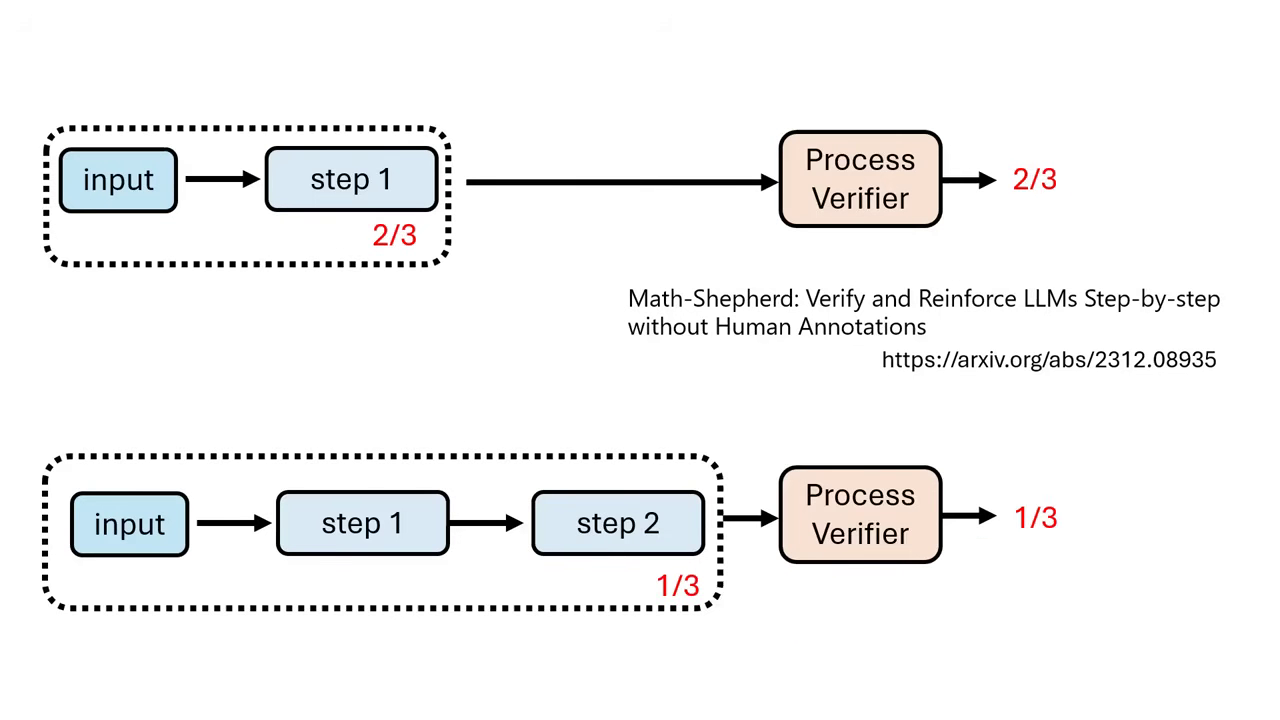
統計最終能答對的機率 將機率直接當作分數
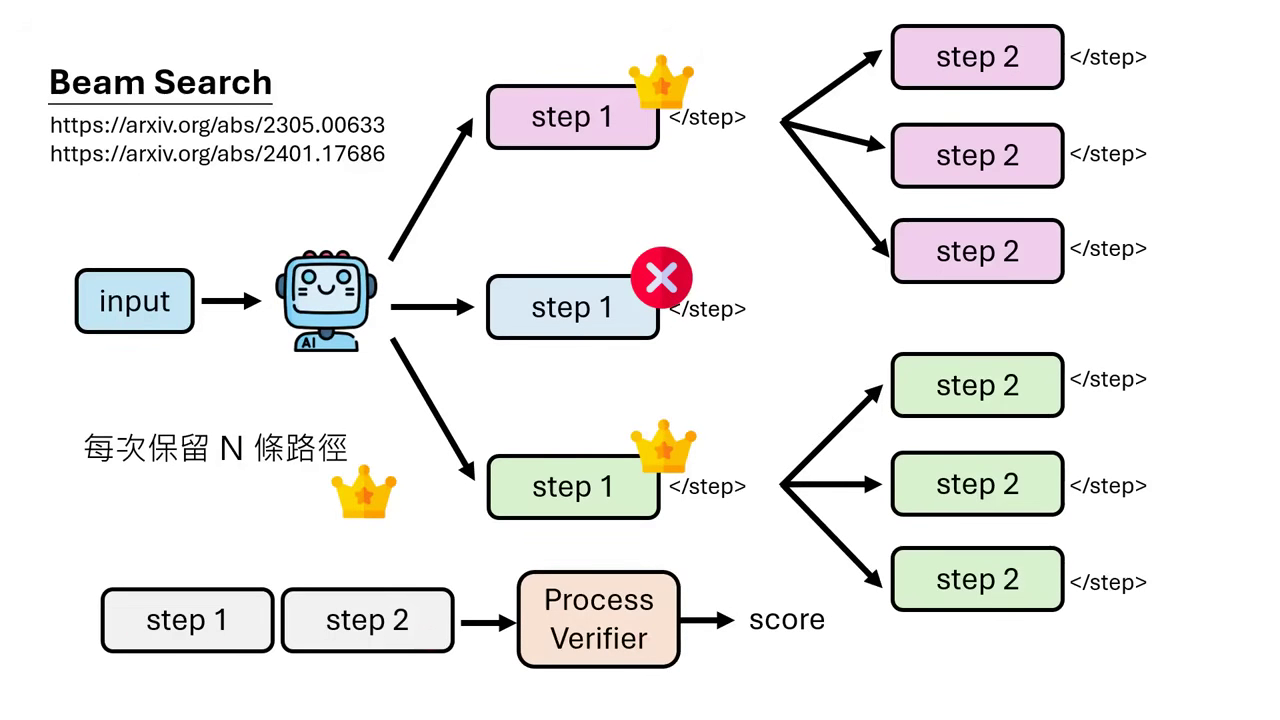
Tree Search (樹狀搜尋) 與 Beam Search
- 運作機制:結合 Beam Search 或 Bin Search 的概念。在生成每一個步驟(Step)後,利用 Process Verifier 評分,每次只保留最好的 N 條路徑(例如前 25% 或分數最高的 2 條)繼續往下生成,將算力集中在最有希望的路徑上。
- 越級挑戰:實驗驚人地發現,1B 的小模型搭配 Bin Search 這種推論工作流程,其解題正確率甚至能超越 8B 的大模型。這證明了只要懂得「如何思考」(Workflow),小模型也能透過演算法戰勝大模型。
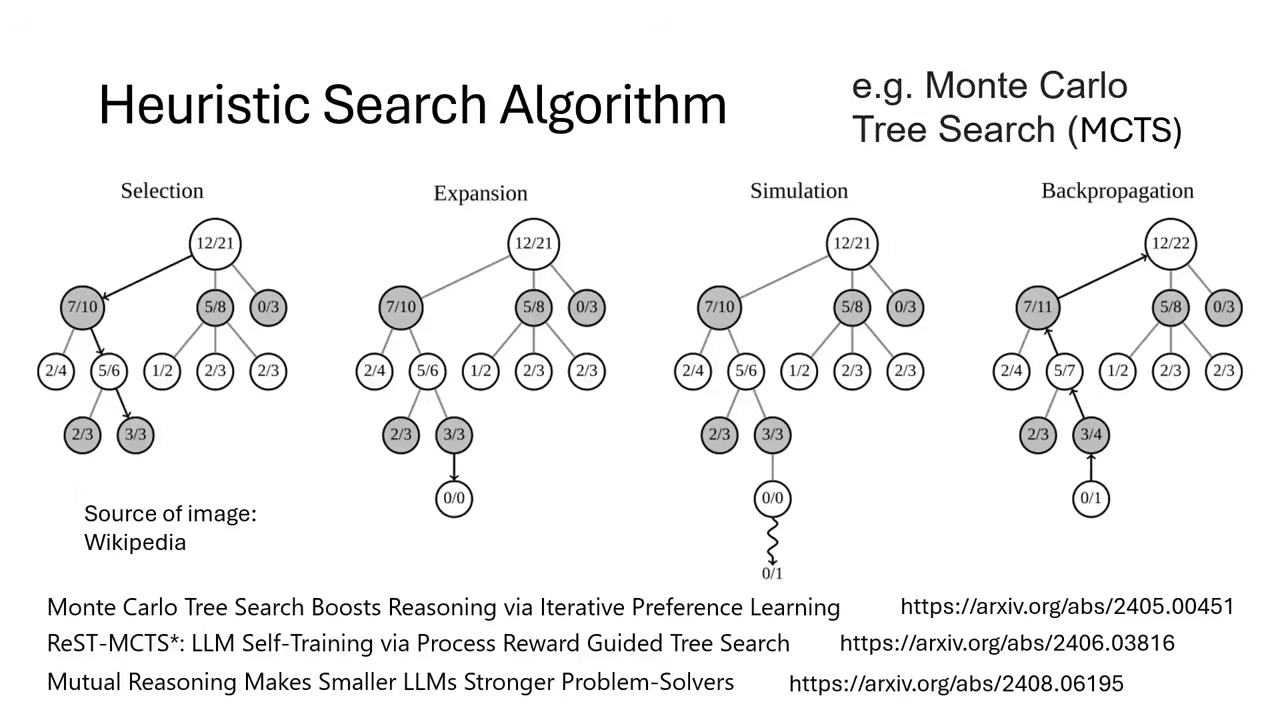
- 多樣化變形:除了 Bin Search,還有 A*、Monte Carlo Tree Search (MCTS) 等多種啟發式搜尋演算法(Heuristic Search)可應用於此框架中。
 |  |
|---|---|
| Beam Search 只保留最好的N條路徑繼續搜尋 | 更多的啟發式搜尋演算法應用到路徑搜尋 |
方法三:教模型推理過程 (Imitation Learning)
此方法需要微調參數,直接教模型模仿推理過程。

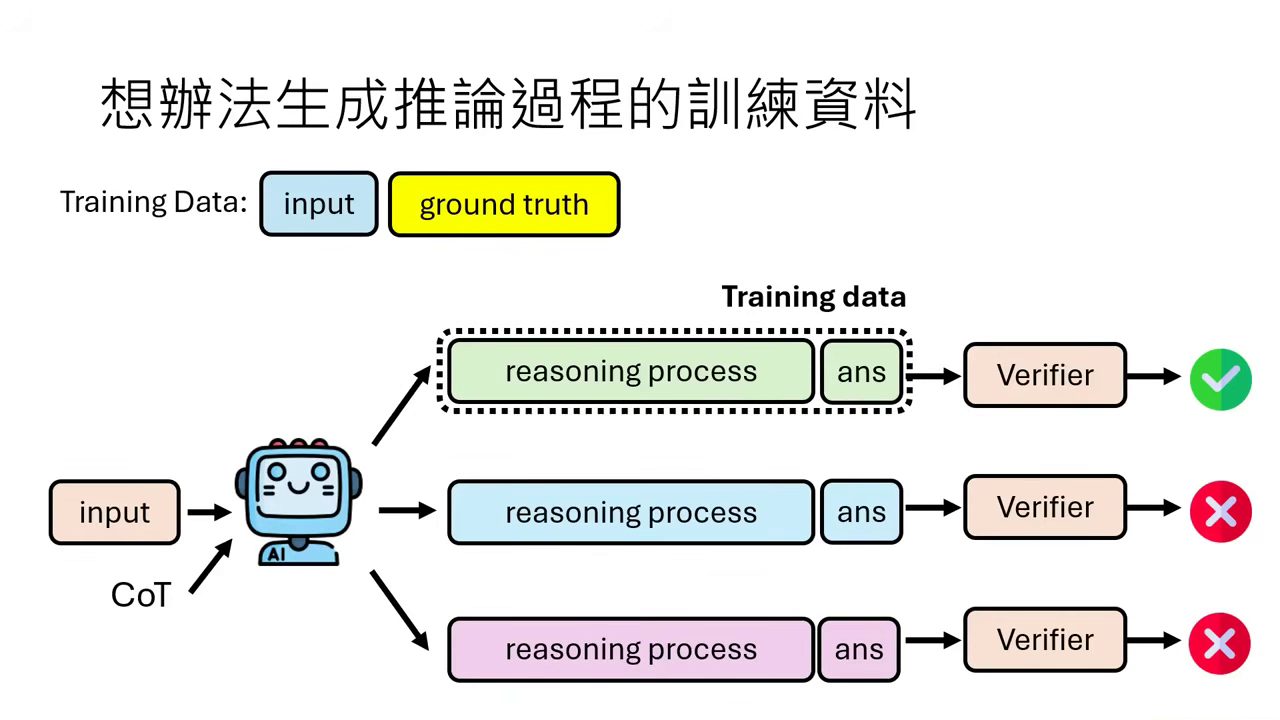
想辦法生成推論過程的訓練資料 (Self-output)
- 難點與解法:一般的訓練資料通常只有「問題」與「正確答案」,缺乏中間的推論過程。解決方案是讓語言模型自己生成 CoT(Chain of Thought),若最終答案與標準答案(Ground Truth)相符,就假設其中間的推理過程也是正確的,並將其作為訓練資料。
- 驗證機制:除了比對答案,也可以引入一個 Verifier(驗證器) 來判斷答案的正確性。若 Verifier 認為答案是對的,就採納�該推理過程。
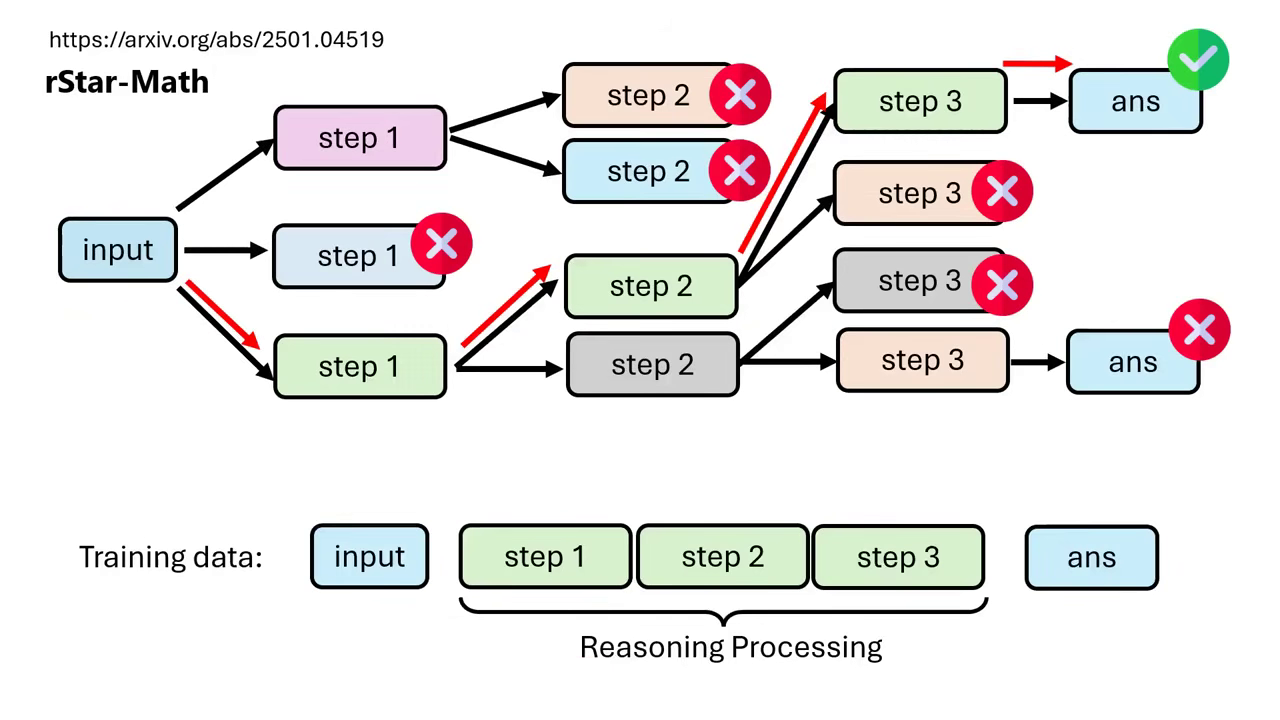
rStar-Math (確保步驟正確性)
- 解決「幸運猜對」的問題:單純的 Self-output 無法保證「答案對,過程就一定對」(可能只是賽到的)。rStar-Math 透過展開樹狀搜尋(Tree Search),並使用 Process Verifier 對每一個步驟進行驗證。
- 高品質資料生成:只有當中間步驟被 Process Verifier 認為是合理的,且最終導向正確答案時,這整串路徑才會被合併成高品質的 Reasoning Process 資料給模型學習。這能確保模型學到的是邏輯嚴謹的推論,而非錯誤的歸因。
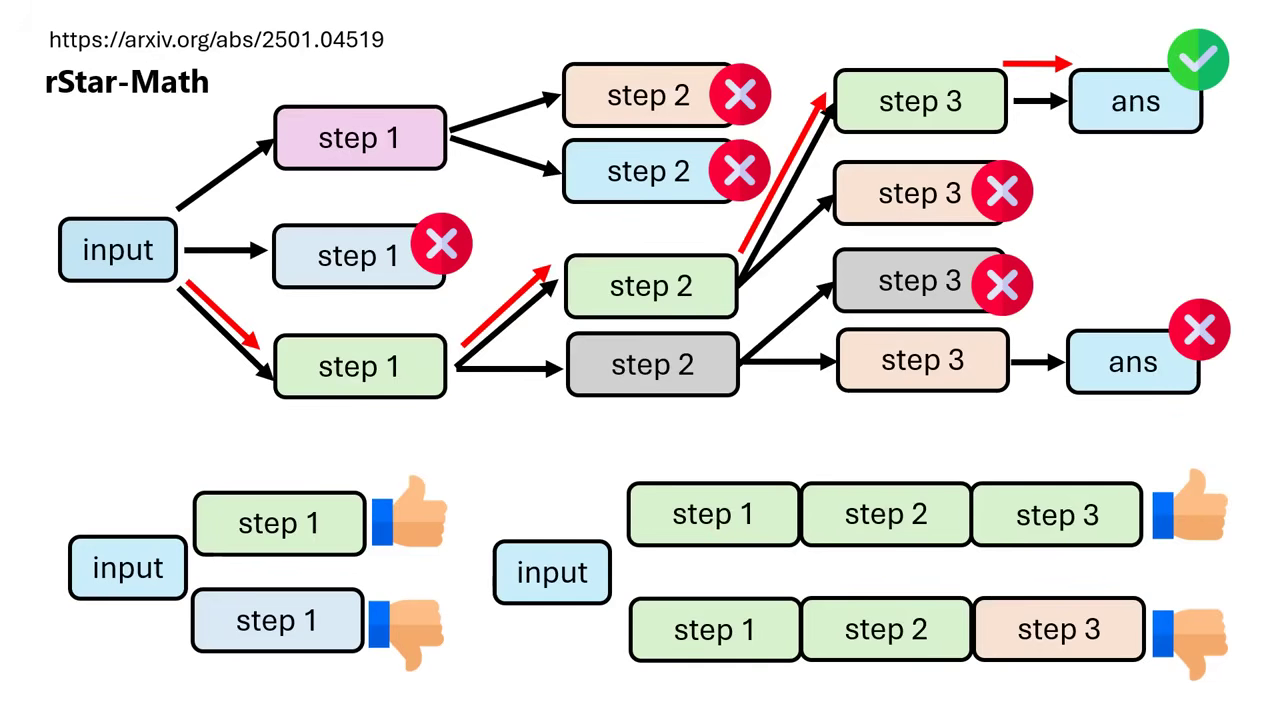
- 多樣化的訓練策略 (SFT & RL):
- Supervised Fine-tuning (Imitation Learning):將經由樹狀搜尋驗證過的正確推論路徑視為標準答案,直接進行監督式微調,教模型模仿正確的思考過程。
- Reinforcement Learning (RL):除了單純模仿,也可利用樹狀結構中的路徑差異(正確 vs. 錯誤路徑),告訴模型「哪一步是好的(增加機率)」、「哪一步是不好的(降低機率)」,類似 DPO 的做法。
 |  |
|---|---|
| 正確結果的路徑 Reasoning Process 資料給模型學習 | 不一定要Supervised Fine-tuning,RL也可以 |
Stream of Search 與 Journey Learning (學習知錯能改)
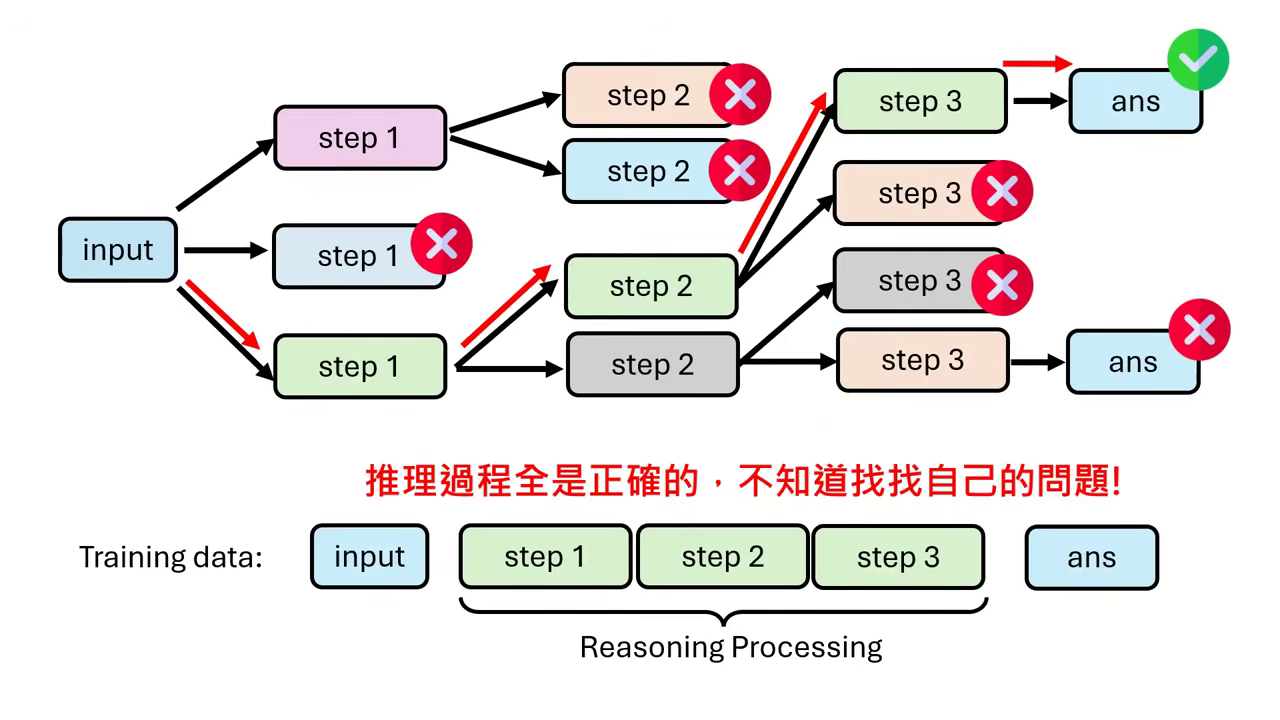
- Shortcut Learning 的陷阱:若只給模型看「每一步都完美」的推論過程(Shortcut Learning),模型會變成只能打順風局。一旦中間出錯,模型因為沒看過錯誤,會不知道如何修正,甚至會為了湊出答案而硬凹(Hallucination)。
- Journey Learning (逆轉勝):為了教導模型「知錯能改」,訓練資料必須包含「走錯路、發現錯誤、修正回來」的過程。
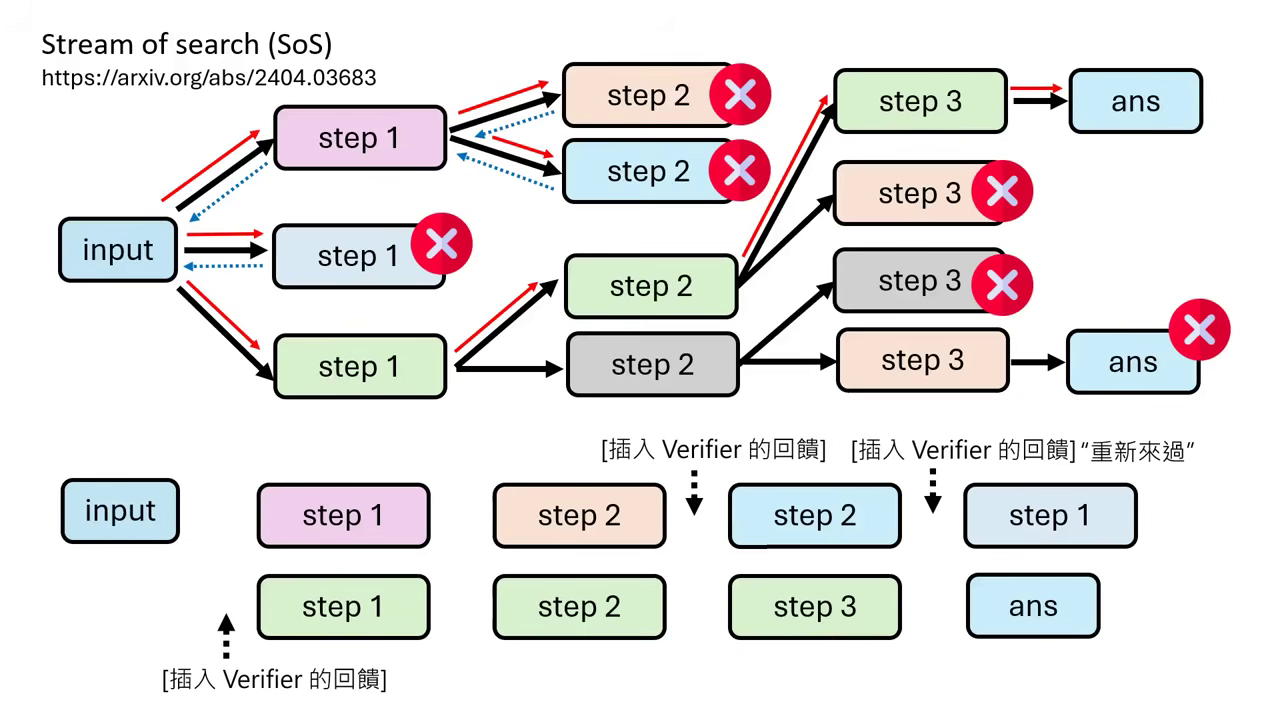
- Stream of Search:此方法會在訓練資料中故意保留錯誤的路徑(例如:先走錯的 Step 2,收到 Verifier 回饋說錯了,再退回重走正確的 Step 2)。
- 加入回饋與連接詞:為了讓語言邏輯通順,會在錯誤與修正之間插入 Verifier 的回饋(如:「這個解法有錯,讓我們重新來過」)作為連接詞。實驗證明,這種包含錯誤修正歷程的 Journey Learning,其訓練效果優於只學完美路徑。
 |  |
|---|---|
| 只給正確的推理過程,模型不知道找自己的問題 | 增加 Verifier 的回饋,可以幫助人讀懂邏輯順序 |
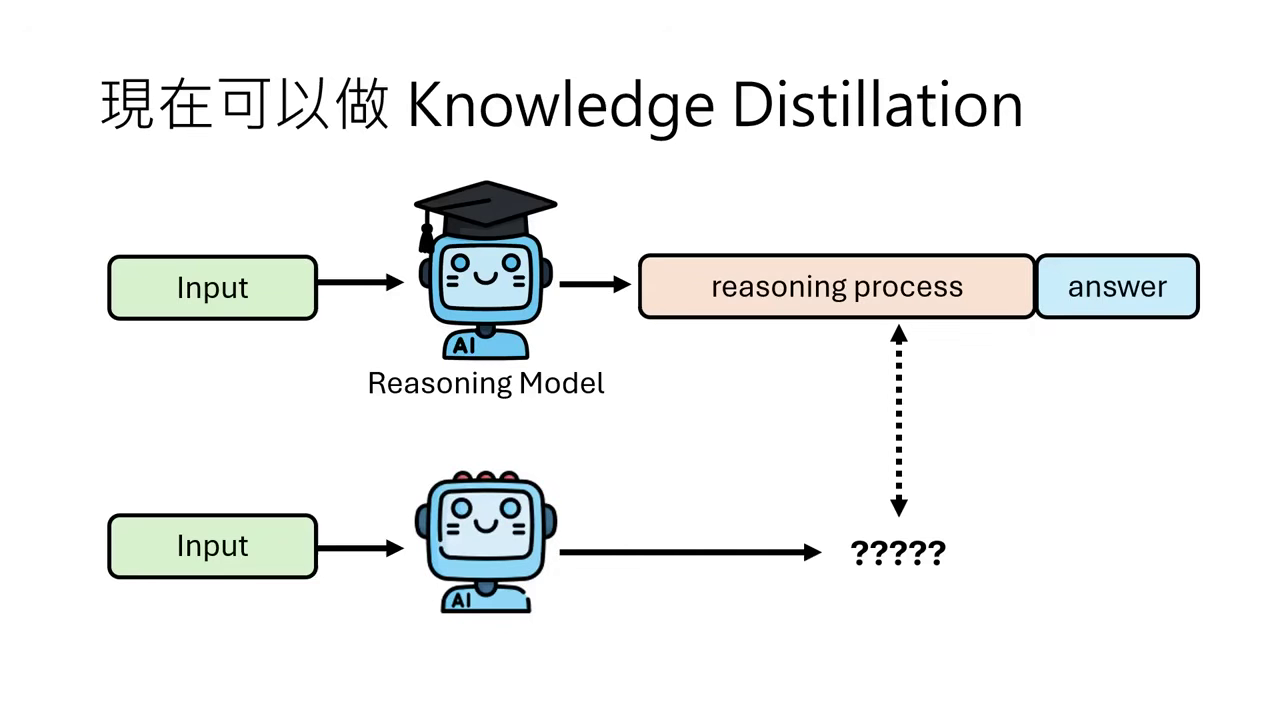
Knowledge Distillation (知識蒸餾)
- 站在巨人的肩膀上:既然市面上已有強大的推理模型(如 DeepSeek-R1),我們可以拿它當老師。直接將問題輸入給強模型,獲取其生成的完整推理過程,再拿這些資料來訓練較小的模型(如 Llama 或 Qwen)。
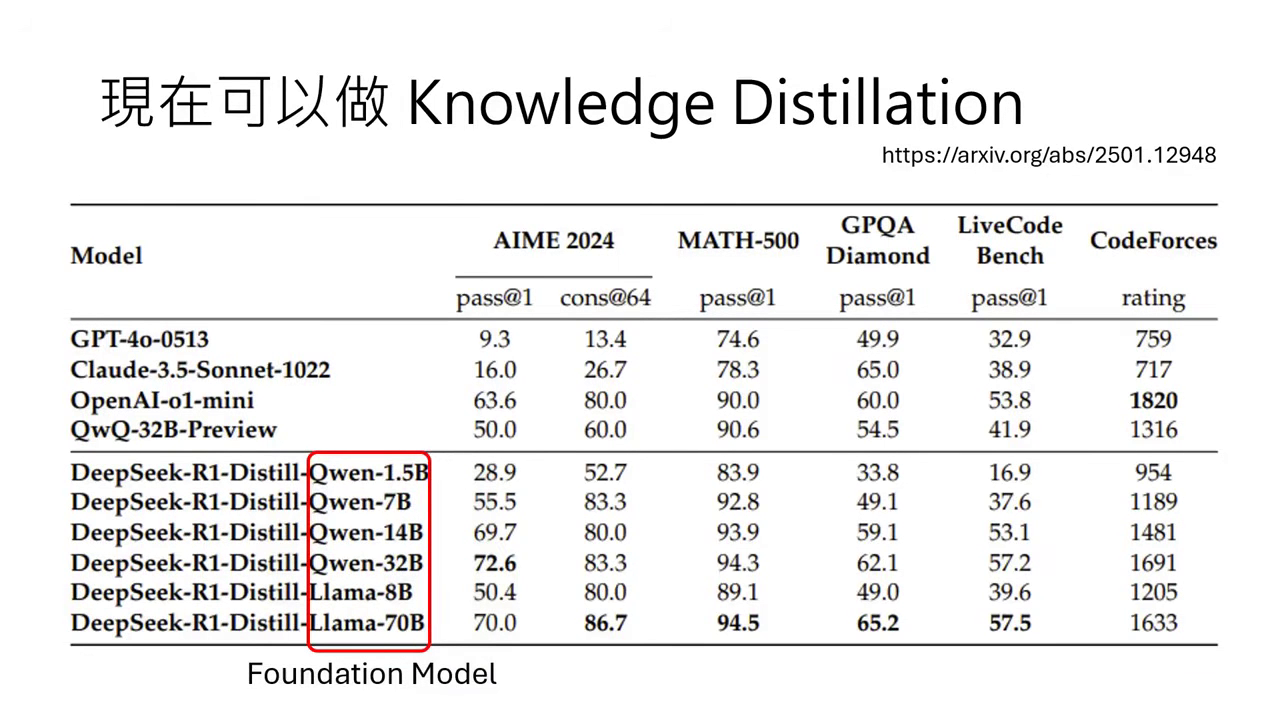
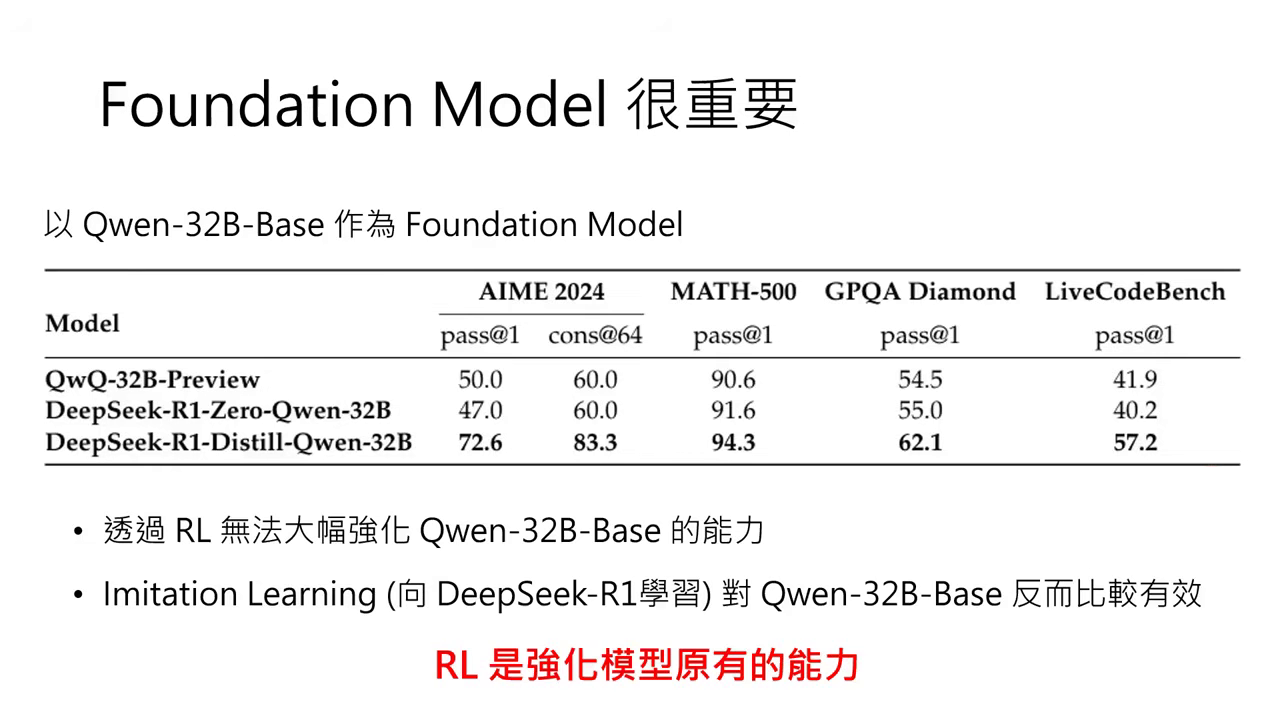
- 小模型的救星:DeepSeek 的技術報告顯示,對於像 Qwen-32B 這類中小型模型,單純用強化學習(RL)很難激發其能力;但若先透過 Distillation 向 DeepSeek-R1 學習推理過程,能力就會大幅提升,甚至在數學與程式任務上能與大模型相提並論。
 |  |
|---|---|
| 現在就可以做 Knowledge Distillation | 實驗結果 |
方法四:以結果為導向學習推理 (Result-Oriented RL)
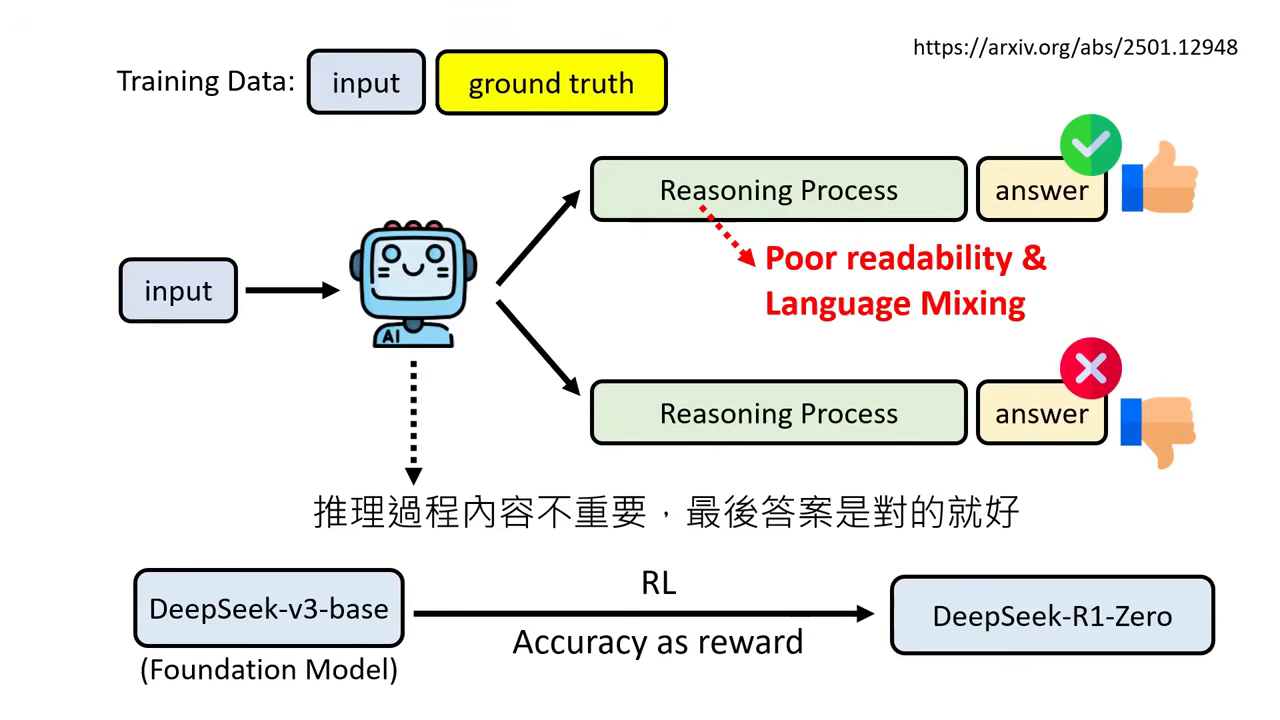
此方法需要微調參數,使用強化學習(RL),只看結果不問過程。
- 運算邏輯:只要答案正確就給 Positive Reward,答案錯誤給 Negative Reward,完全不在意中間推論寫了什麼。
- DeepSeek-R1-Zero (純 RL 版本):
- Aha Moment (頓悟):模型在純 RL 訓練過程中,自發性學會了檢查錯誤、重新思考的行為,這不是人類教的,而是模型自己學到的。
- 缺點:推論過程極難閱讀,語言混雜,因此未正式發布。
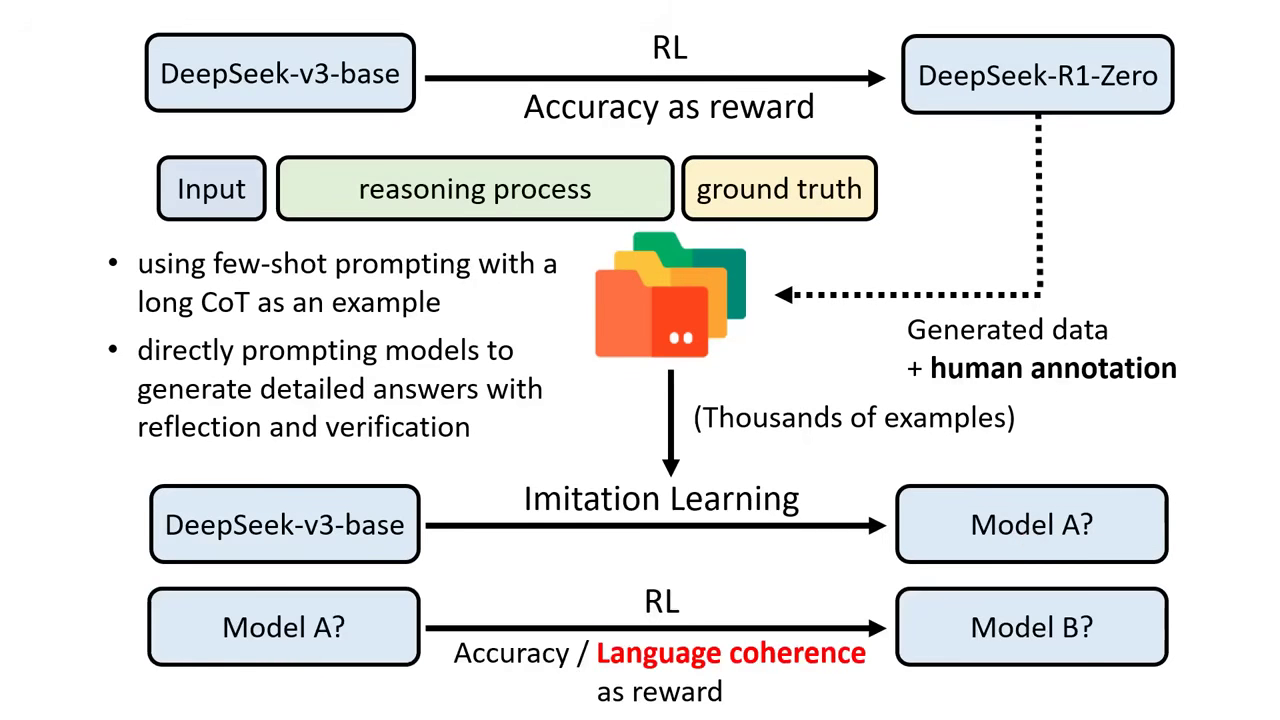
- DeepSeek-R1 (正式版) 的四階段訓練:
- Cold Start:利用少量人工介入或 Prompt 生成的高品質推理資料(解決 R1-Zero 語言混亂問題),訓練出 Model A。
- Reasoning RL:對 Model A 進行 RL 訓練(加入語言一致性 Reward),得到 Model B。
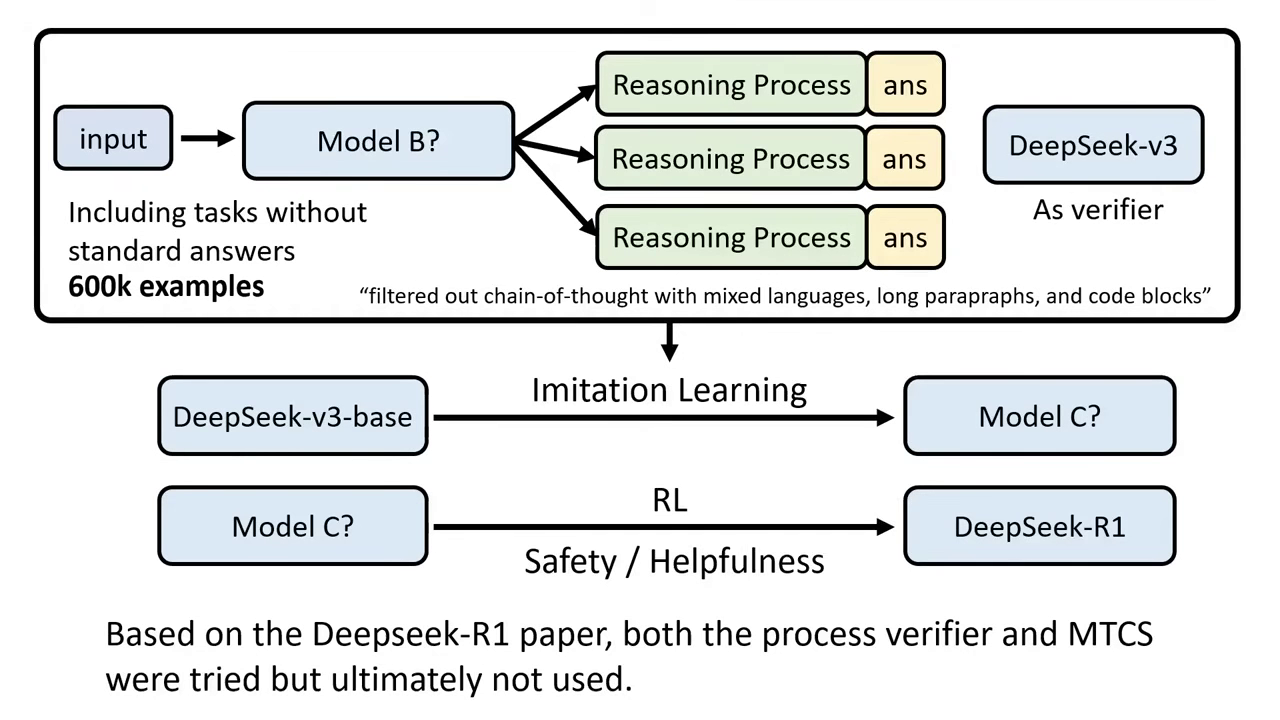
- Rejection Sampling & SFT:用 Model B 生成大量資料(60萬筆),並過濾掉爛的,重新做 Imitation Learning 得到 Model C。此階段會加入非推理任務資料以維持通用能力。
- All-round RL:最後進行針對安全性(Safety)與實用性(Helpfulness)的 RL,完成 DeepSeek-R1。
步驟1、2 步驟3、4
推理能力是被喚醒的,不是被訓練出來的
- RL 是強化「既有」能力:RL 能夠成功的關鍵在於 Foundation Model 本身就具備推理的潛力(只是沒被激發)。如果是很弱的模型(如 Qwen-32B Base),純用 RL 效果有限;但若先透過 Imitation Learning(向 R1 學習)再做 RL,效果就會非常好。
- 方法不互斥:上述四種方法可以疊加。例如 DeepSeek-R1 在訓練時用了 Imitation 和 RL,在測試時(Inference)依然可以用 Majority Vote 進一步提升效能。