AI Agent 的定義與運作機制
核心定義
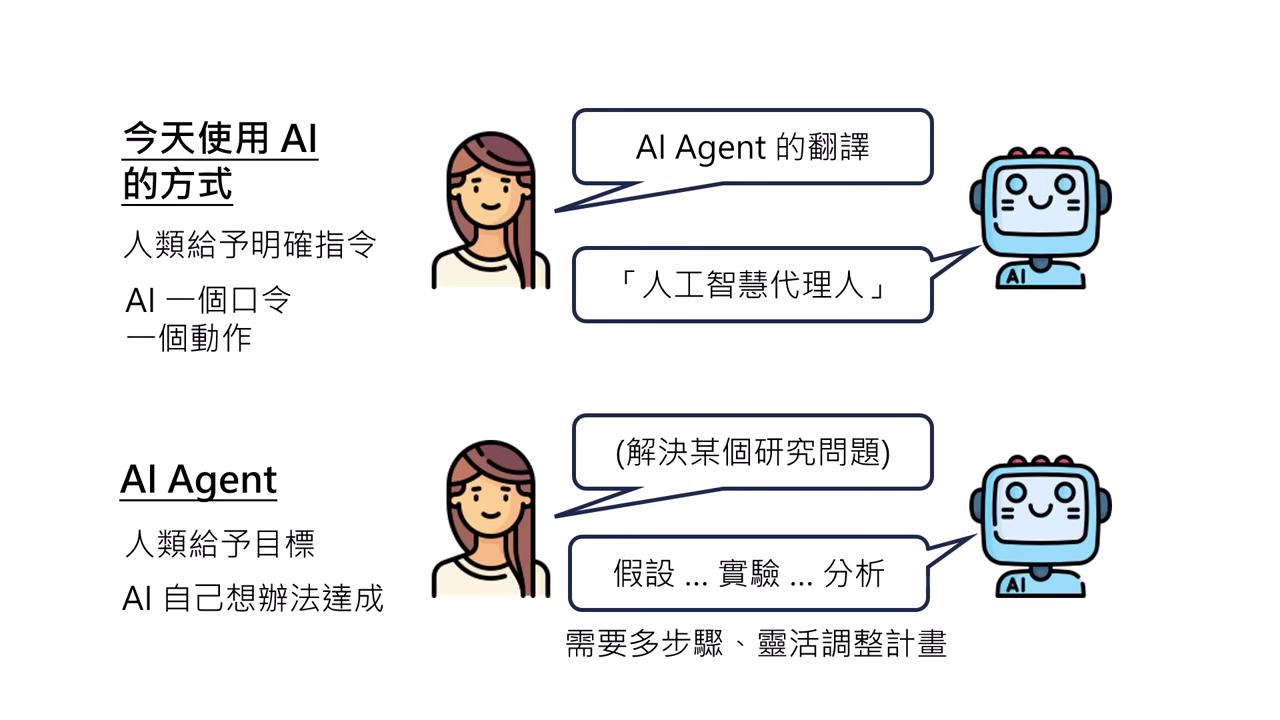
人類不提供明確的步驟指示,僅給予 目標 (Goal),由 AI 自己想辦法達成。AI 必須具備在複雜、不可預測的環境中靈活調整計畫的能力。
運作流程 (循環機制)
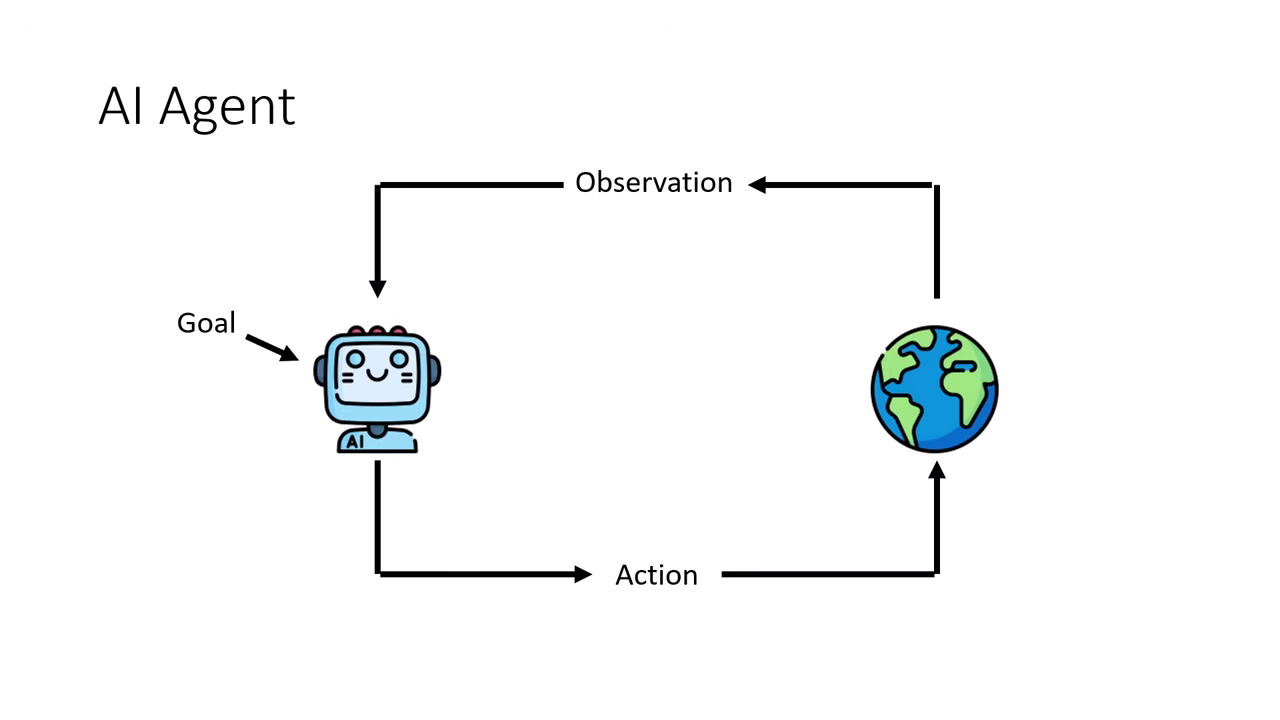
- 目標 (Goal):由人類給定的輸入。
- 觀察 (Observation):AI 觀察並分析目前的狀況。
- 行動 (Action):AI 採取行動影響環境,進而產生新的觀察,循環直到達成目標。
技術演進
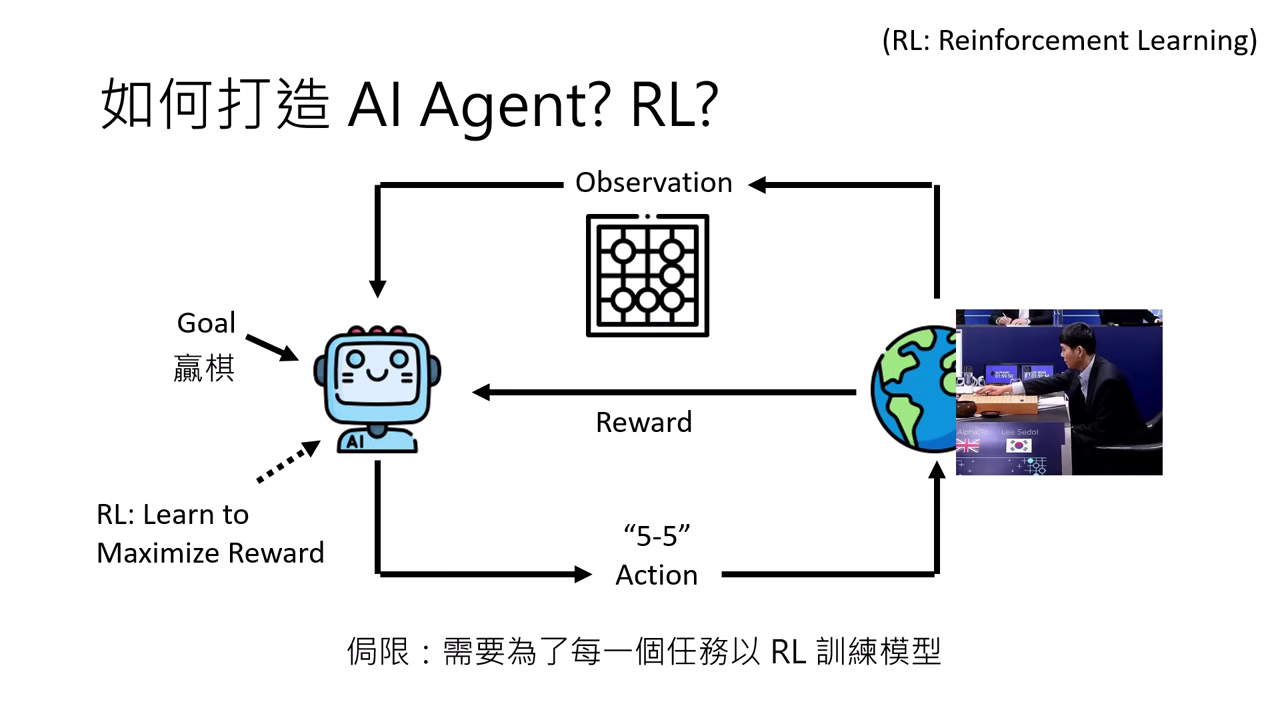
- 過去 (RL 打造):透過強化學習 (Reinforcement Learning) 訓練模型以最大化獎勵 (Reward),但侷限在特定任務且不同任務無法通用。
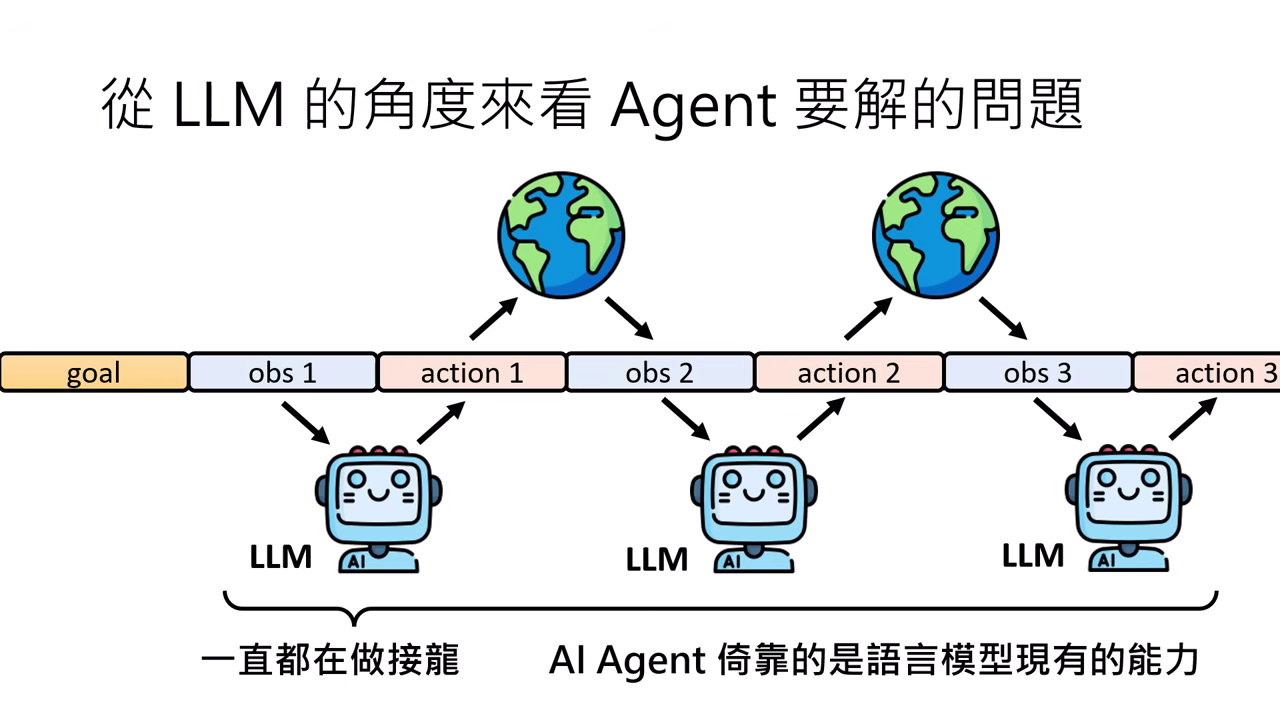
- 現在 (LLM 驅動):直接將大型語言模型 (LLM) 當作 Agent,利用其文字接龍的能力處理目標與環境敘述。
文字接龍的應用延伸
從 LLM 角度看,Agent 並非新技術,而是依靠模型現有的通用能力進行「文字接龍」,將環境觀察轉為文字輸入,並將文字輸出轉譯為可執行動作。
LLM Agent 的優勢
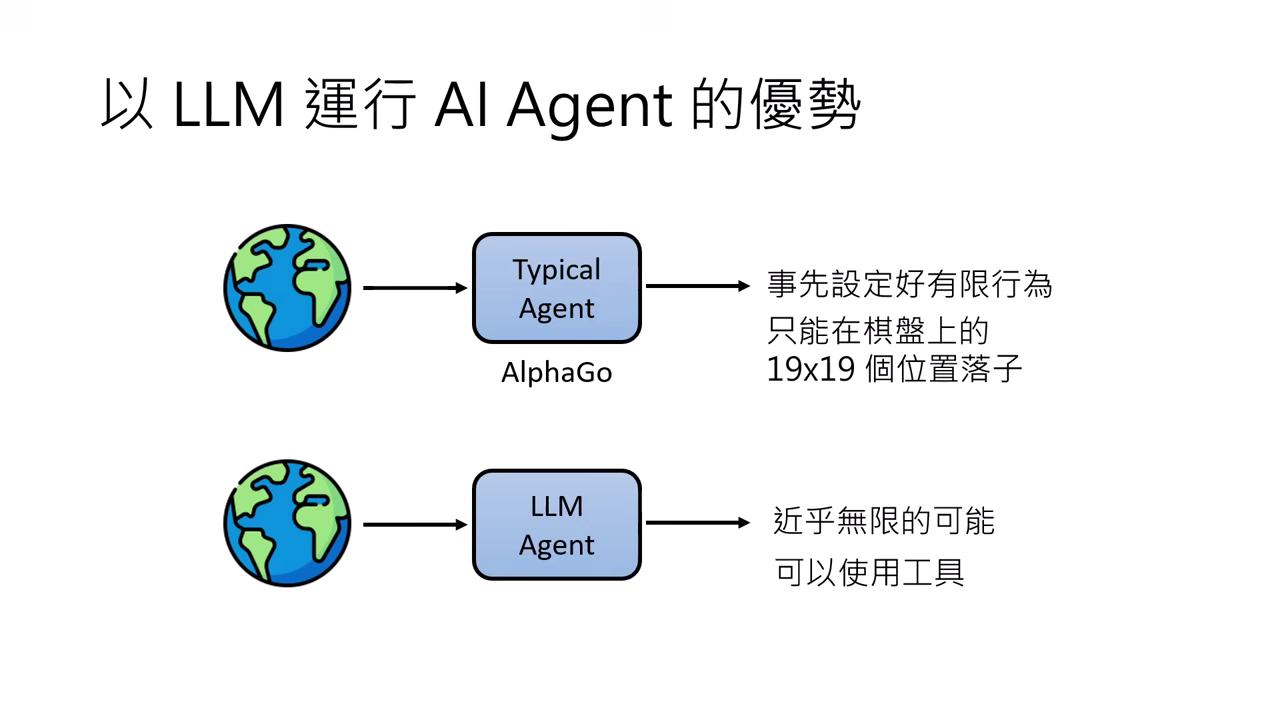
- 無限的行動可能:輸出不再侷限於預設的選擇題,具備近乎無窮的行動方式。
- 豐富的回饋資訊:不需要「通靈」設定數值獎勵,可直接讀取如編譯錯誤 (Compile log) 等文字訊息來修正行為。
關鍵能力:根據經驗調整行為 (記憶模組)
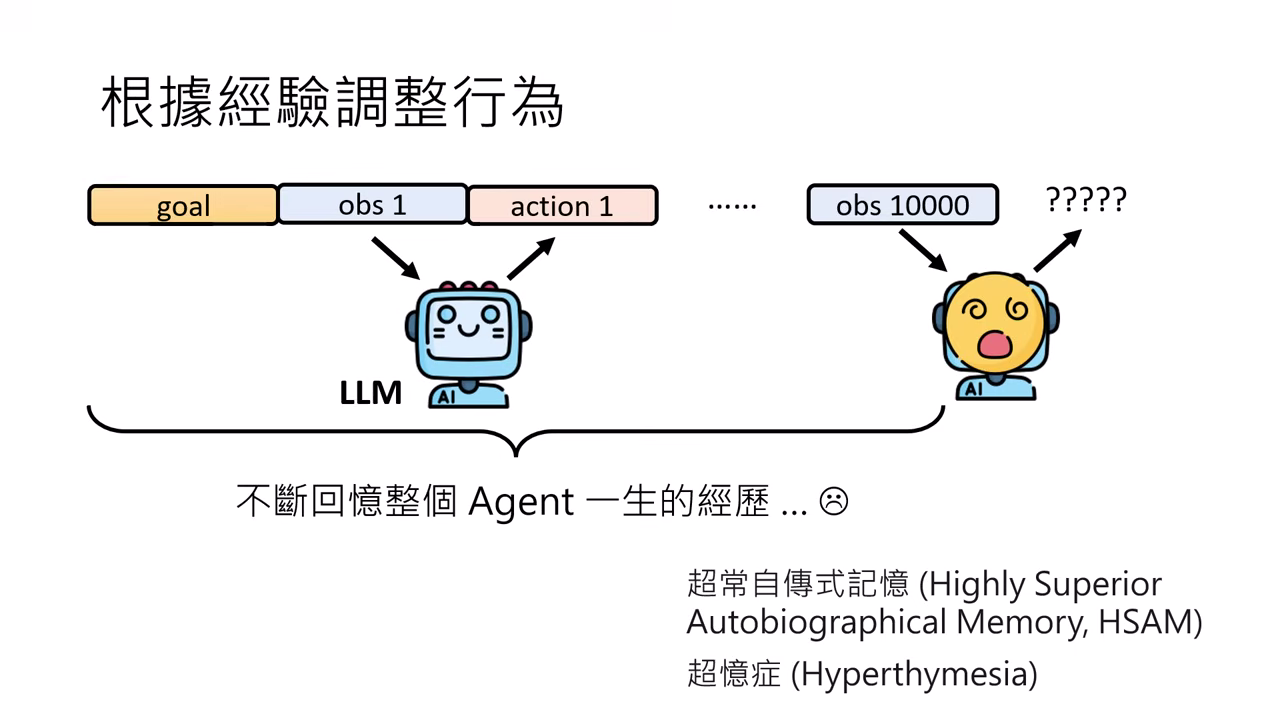
AI Agent 需具備不更新參數也能根據回饋改變行為的能力,主要是透過��對長期記憶的管理:
超憶症 (Hyperthymesia) 的風險
若將所有經歷一股腦丟給模型,會因記憶過長、瑣碎資訊太多而耗盡算力或無法進行抽象思考。
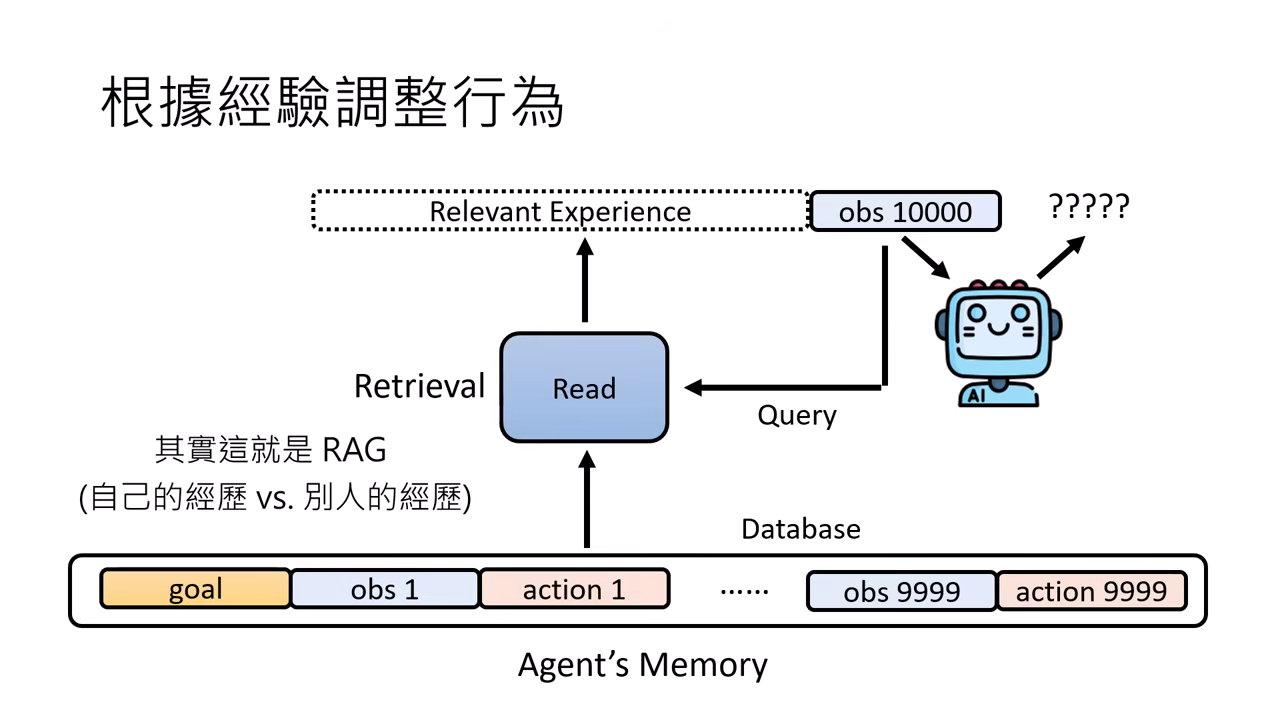
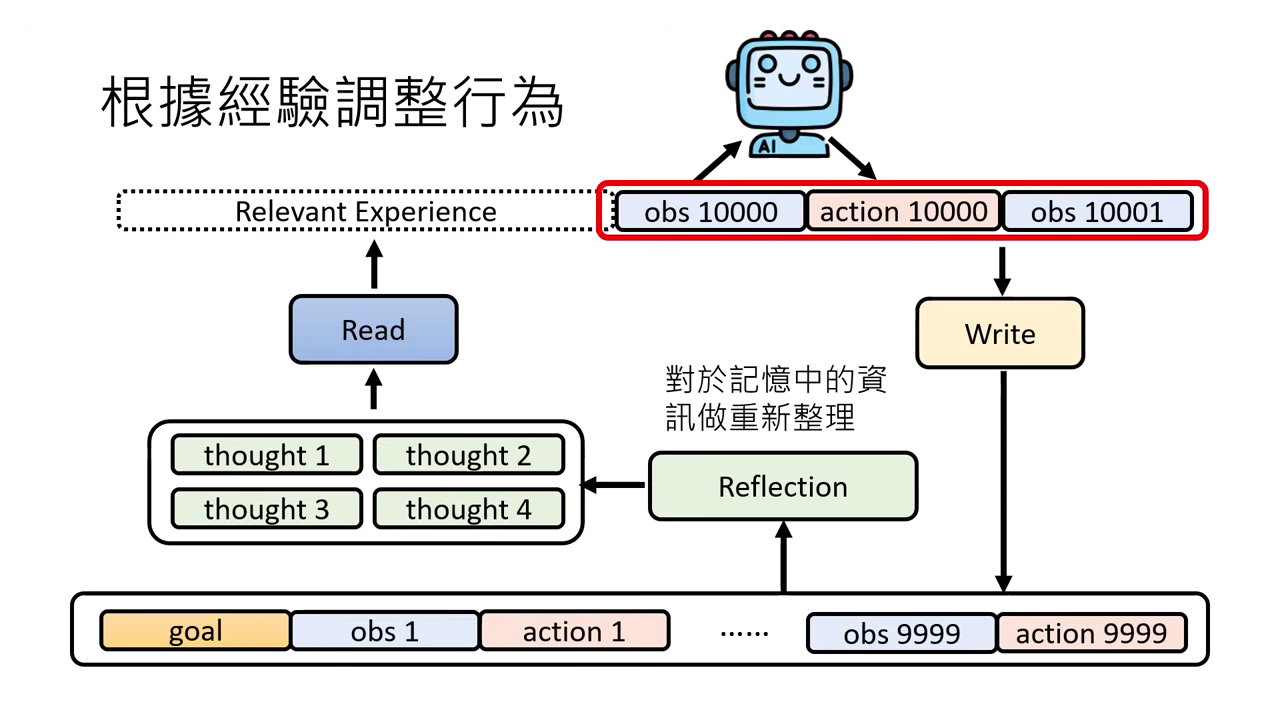
Read (讀取/檢索)
如同 RAG 技術,從長期記憶庫中篩選出與目前情境相關的經驗,作為決策參考。
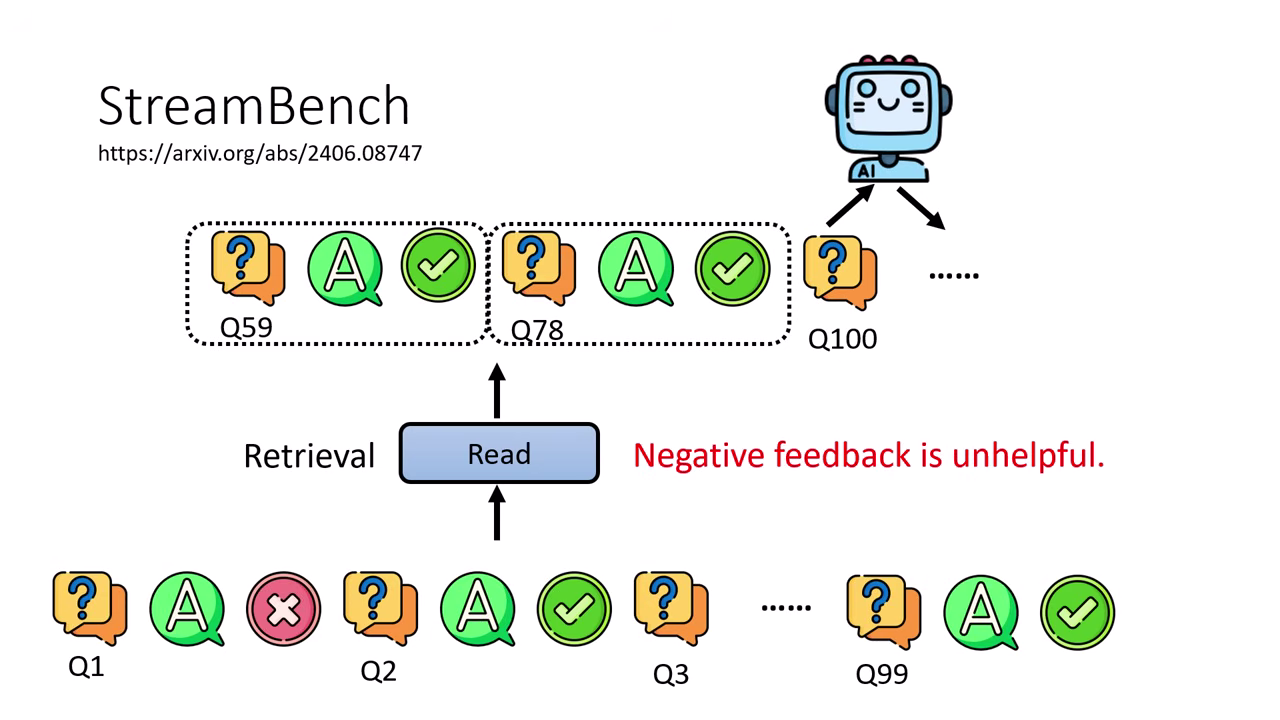
StreamBench
這是由 API 研究人員打造的評估基準,專門研究 AI Agent 能否根據經驗修改行為。模型需依序解決一系列問題(如 1750 個問題),並在每次回答後接收「對」或「錯」的二元回饋作為經驗。
- 實測發現:對現階段模型而言,提供「正面成功的經驗」比「負面失敗的例子」更能有效引導模型得到正確答案。
Reflection (反思)
對記憶進行抽象化的重新整理,產生新想法 (New Thought) 或建立 知識圖譜 (Knowledge Graph),協助做出更好的決策。
關鍵能力:使用工具 (Function Call)
工具的定義
Agent 只需要知道如何使用,而不需要知道內部運作原理的函式 (Function),如搜尋引擎、程式執行器或其他 AI。
通用運作方式 (System Prompt)
- 在 System Prompt(開發者設定、優先級較高)中定義工具的使用方式與格式。
- 開發者需搭建「橋樑」,將模型產出的特定格式文字轉為實際的函式調用,並將結果回傳給�模型。
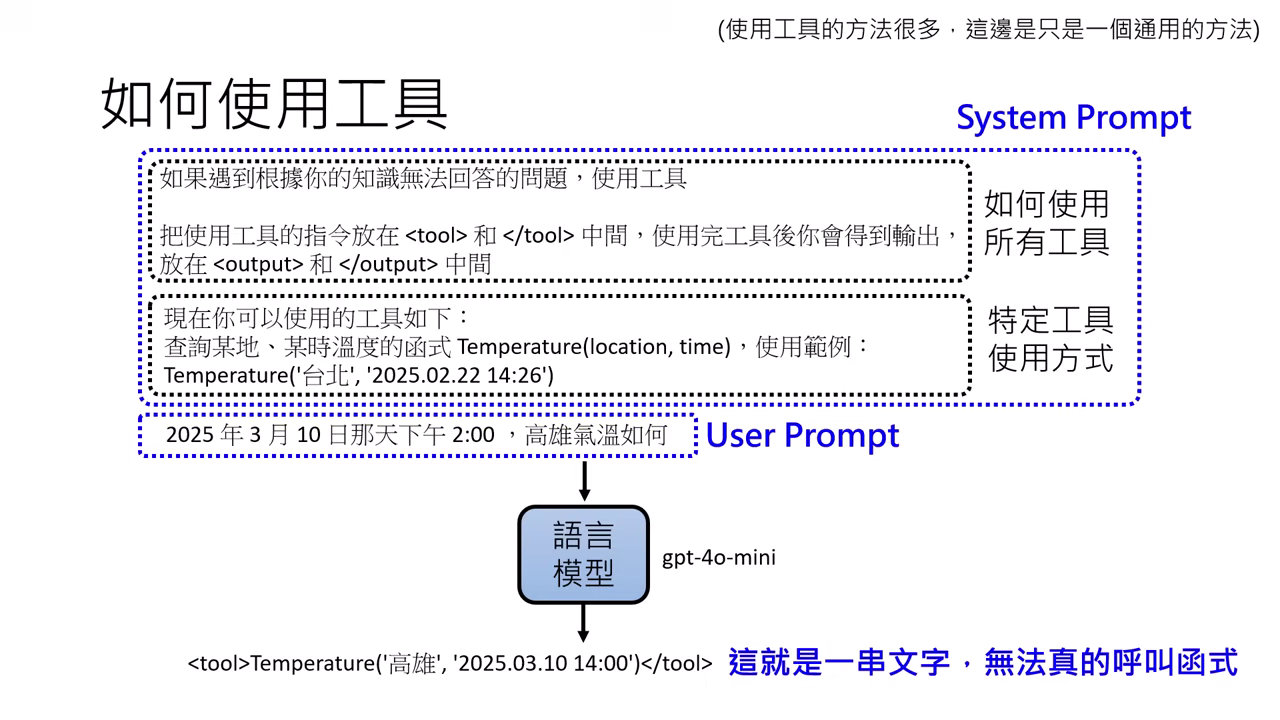
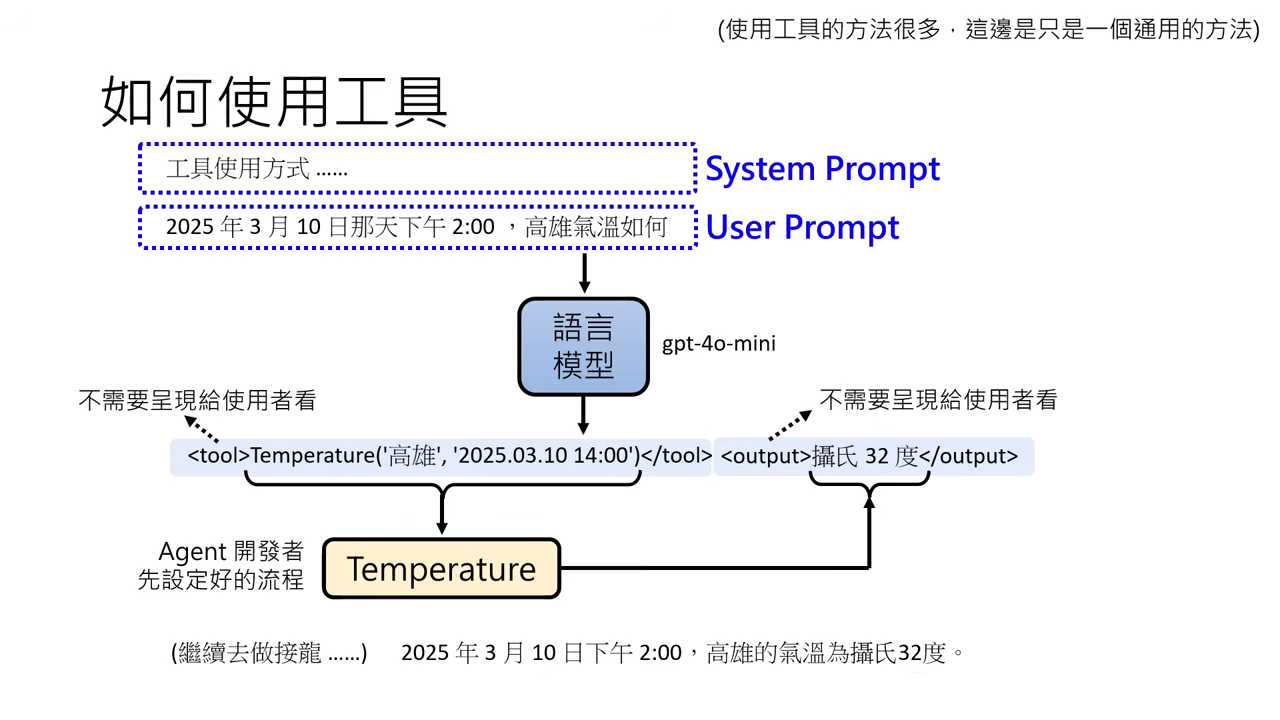
在 System Prompt 中定義工具 自己搭建使用 Tool 的橋樑
自我進化
模型甚至可以自己編寫程式碼 (Function) 來打造新工具,並將其放入工具包中供未來使用。
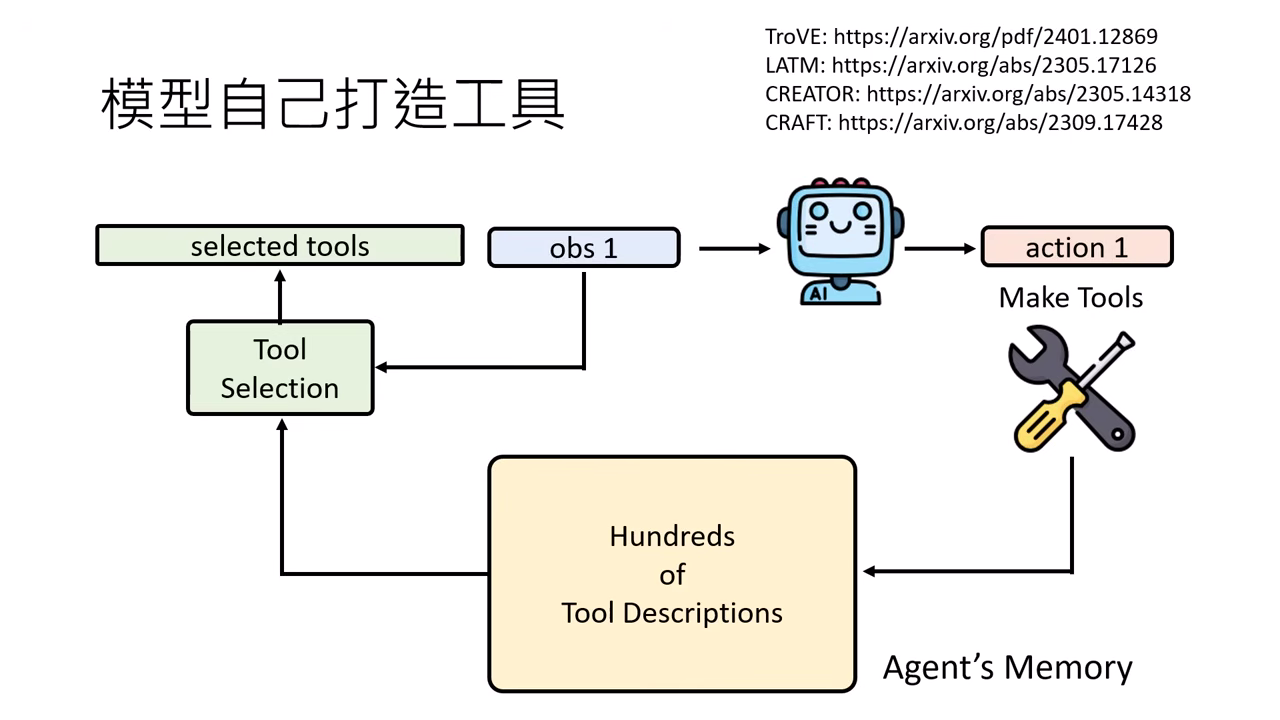
判斷力與信任問題
- 知識拉扯:模型在內部知識與工具提供的外部知識間會有角力。當兩者差距過大時,模型較不容易相信外部知識。
- 偏好特徵:模型傾向相信 AI 同類寫的內容、發布日期較新 的文章,以及 排版精美 的呈現方式。

關鍵能力:執行與修正計畫 (Planning)
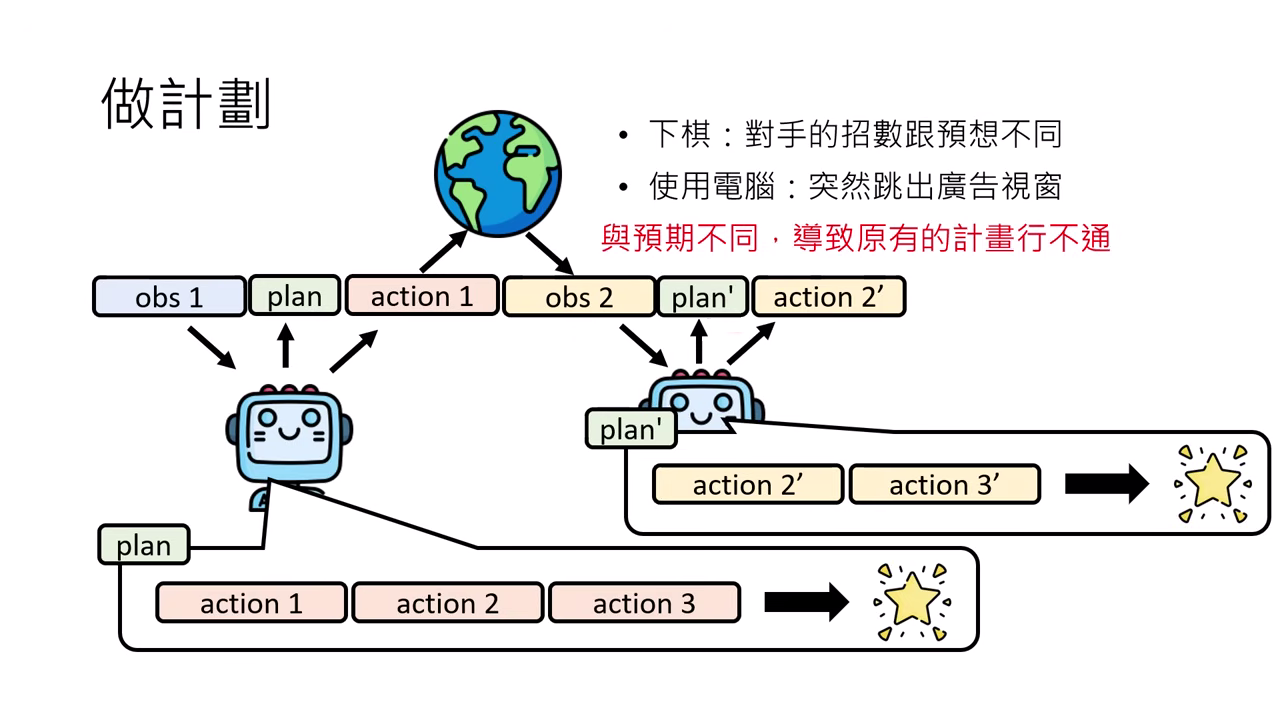
計畫的必要性
先產生一系列行動步驟 (Plan) 再執行通常效果較好。但因環境具隨機性,Agent 必須能在看到新觀察 (Observation) 時隨時修改計畫。
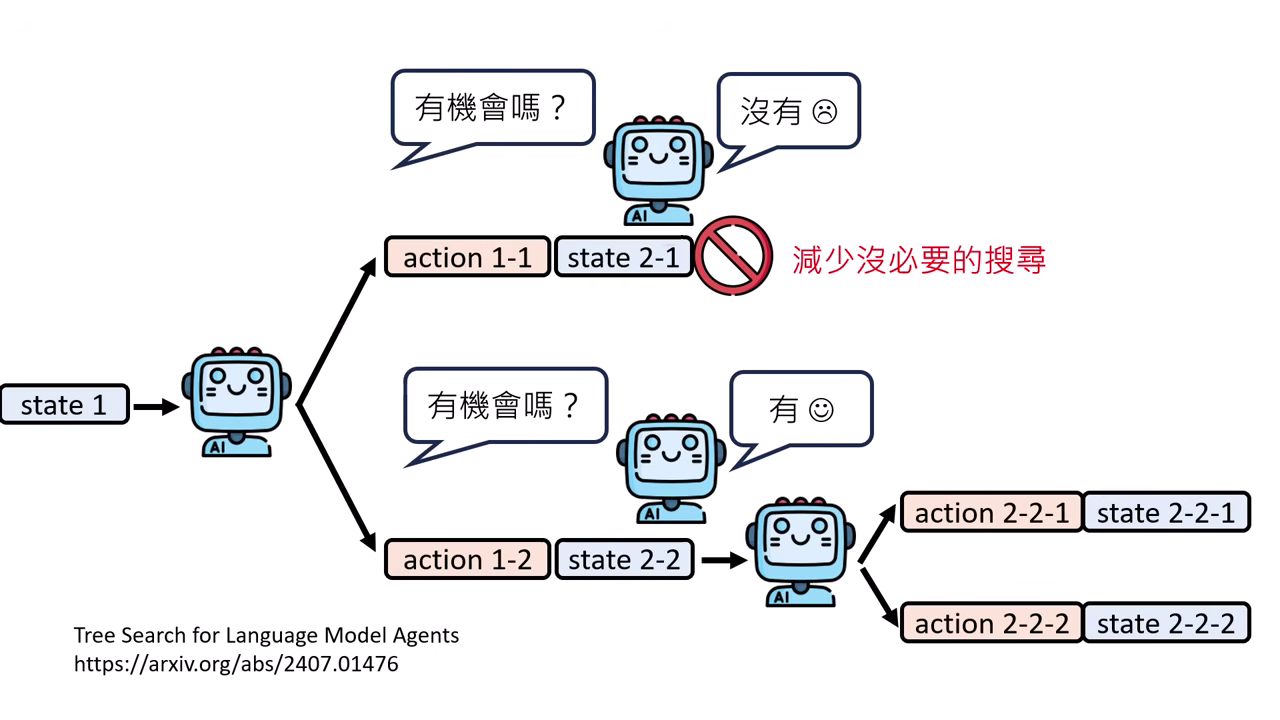
路徑搜尋與優化
- Tree Search:嘗試多種可能路徑,並自問「路徑是否有希望」來剔除低分選項,減少搜尋成本。
- 世界模型 (World Model):為了解決某些動作「覆水難收」的問題(如訂了 Pizza 無法退),一切嘗試應發生在 腦內小劇場(夢境) 中,利用 World Model 模擬環境變化,確認成功後再於現實執行。
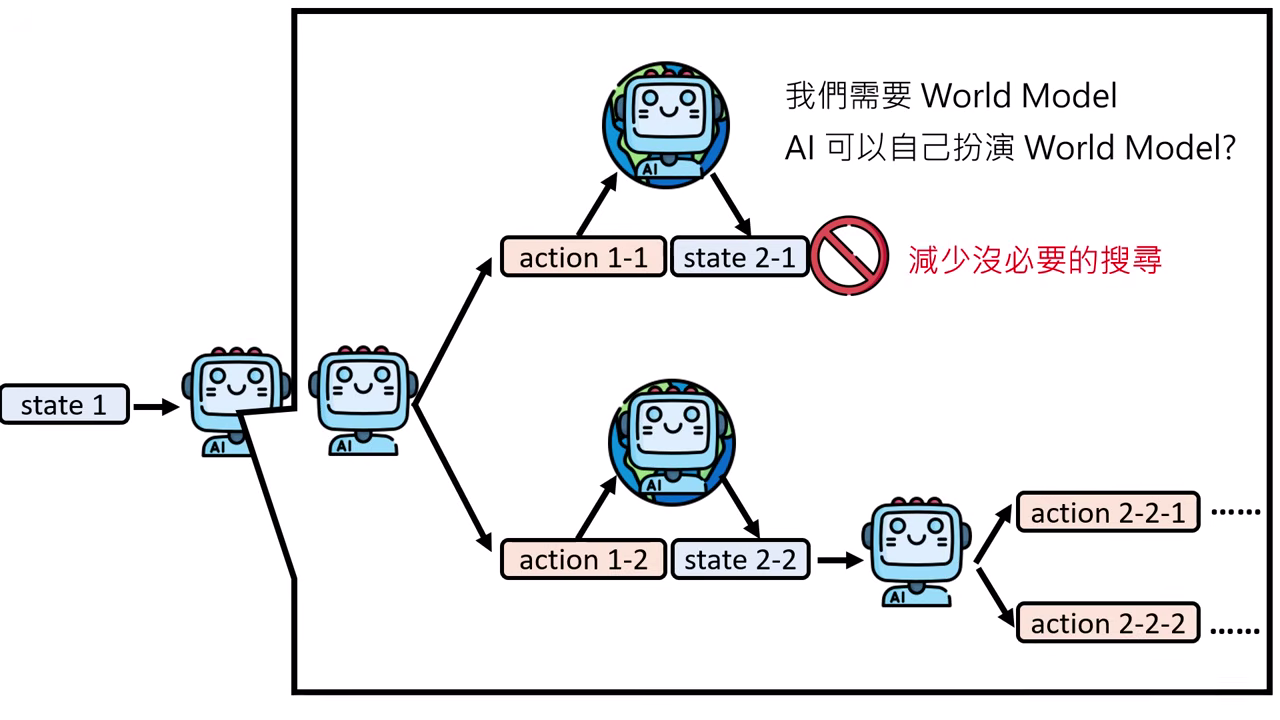
Tree Search 世界模型 (World Model)
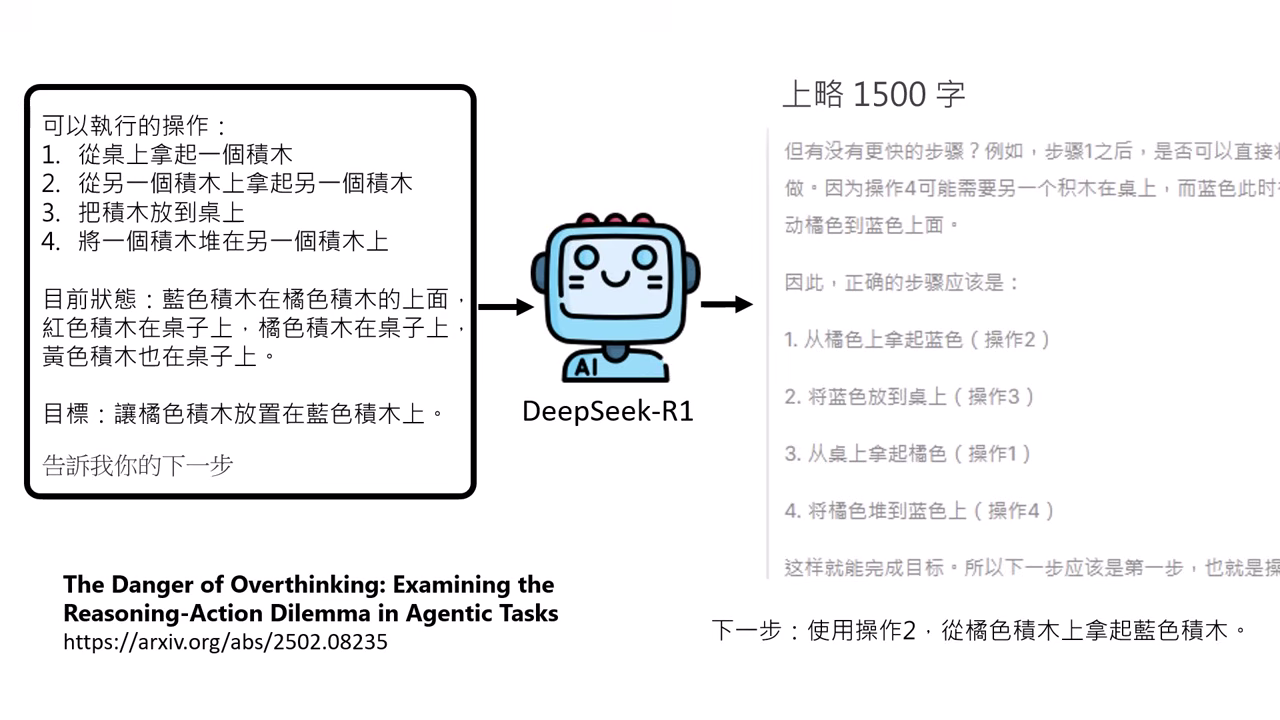
思考與推理 (Reasoning)
如 o1 或 DeepSeek 等具備推理能力的模型,透過長達千字的內心戲找出最佳解決方案。
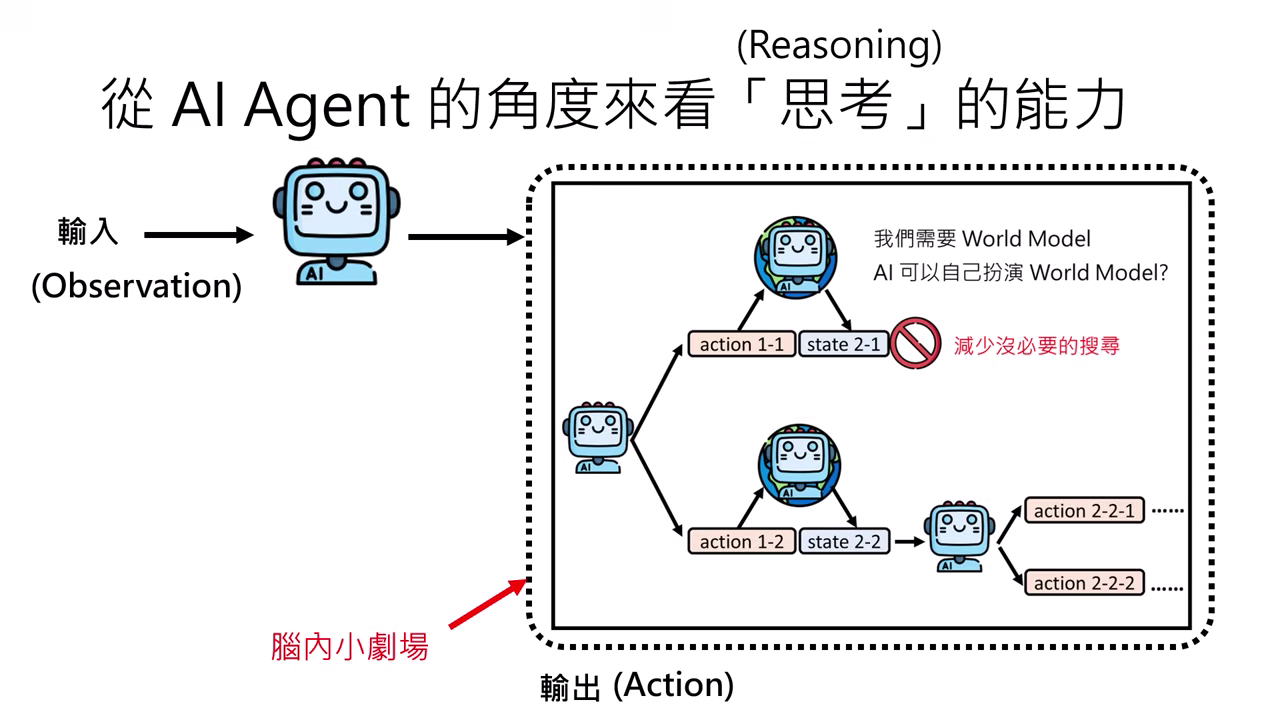
潛在風險 (Over-thinking)
模型可能成為「思考的巨人,行動的矮子」,因過度思考而不敢行動或在不需要思考時糾結過久。