大型語言模型訓練方法「預訓練–對齊」的強大與極限
訓練模型三階段與對齊的定義
- 第一階段:Pre-train(預訓練):透過大量網路爬蟲資料,讓機器具備基本的文字接龍能力。
- 第二階段:Supervised Fine-tuning (SFT):又稱 Instruction Fine-tuning,由人類提供正確問題與答案的對答範例。
- 第三階段:RLHF(來自人類回饋的強化學習):人類對模型的不同回答提供好壞回饋。
- Alignment(對齊):指第二與第三階段的總稱,目標是讓模型的輸出符合人類價值觀與需求。
!three-stage-training-and-alignment](00:01:51)
Alignment 的「畫龍點睛」作用
- 資料量小、品質極大化:Alignment 階段使用的資料量遠少於 Pre-train。例如 LLaMA-2 僅用約 2.7 萬筆資料微調。LIMA 甚至證明僅用 1,000 筆精選資料就能達到極佳效果。
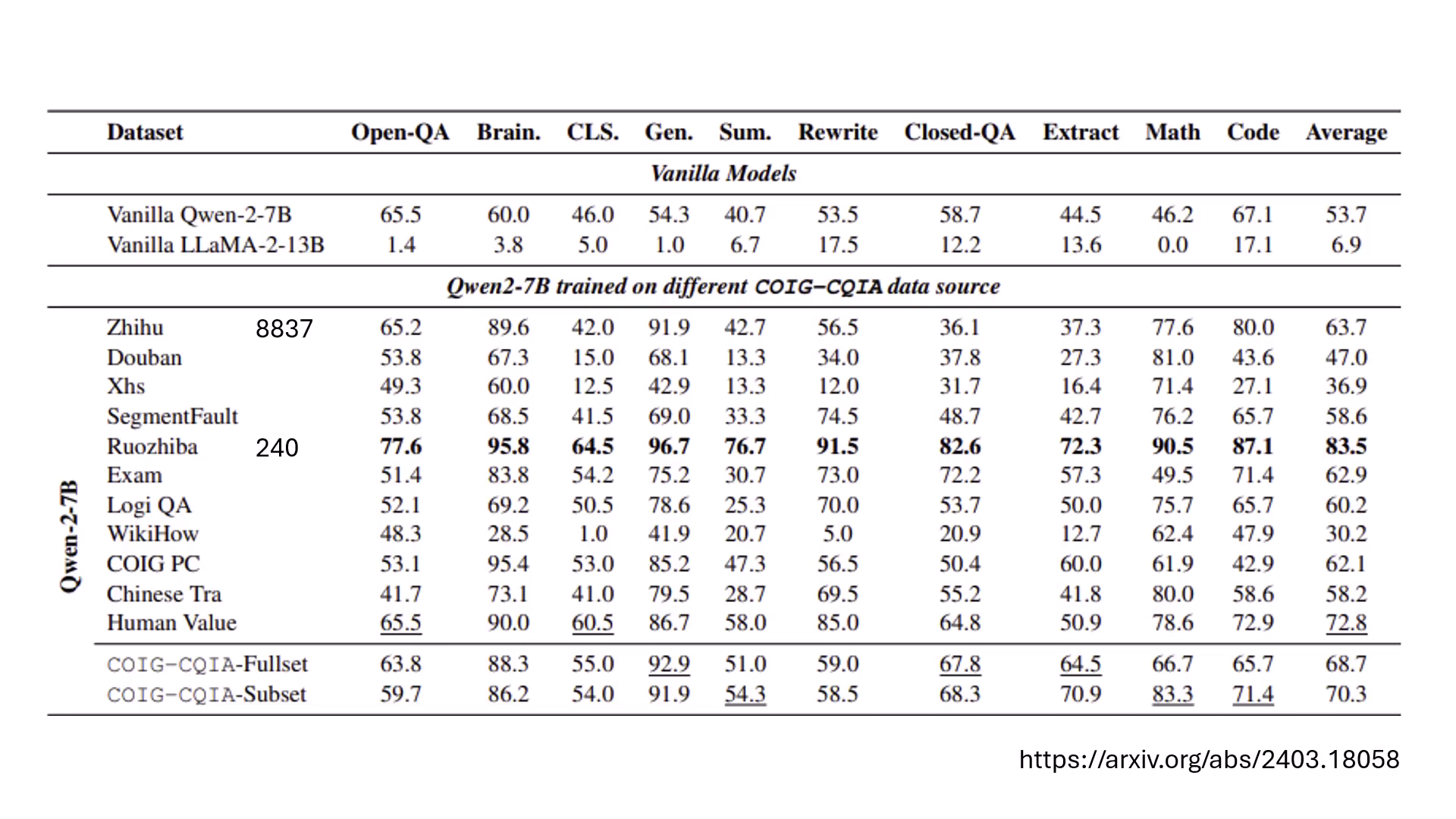
- 弱智吧 (Ruozhiba) 的奇效:實驗發現來自「弱智吧」的 240 筆資料比 8,000 筆知乎資料更有助於模型進步。原因可能是題目豐富且答案是由 GPT-4 生成的,等同於對模型進行了知識蒸餾 (Knowledge Distillation)。
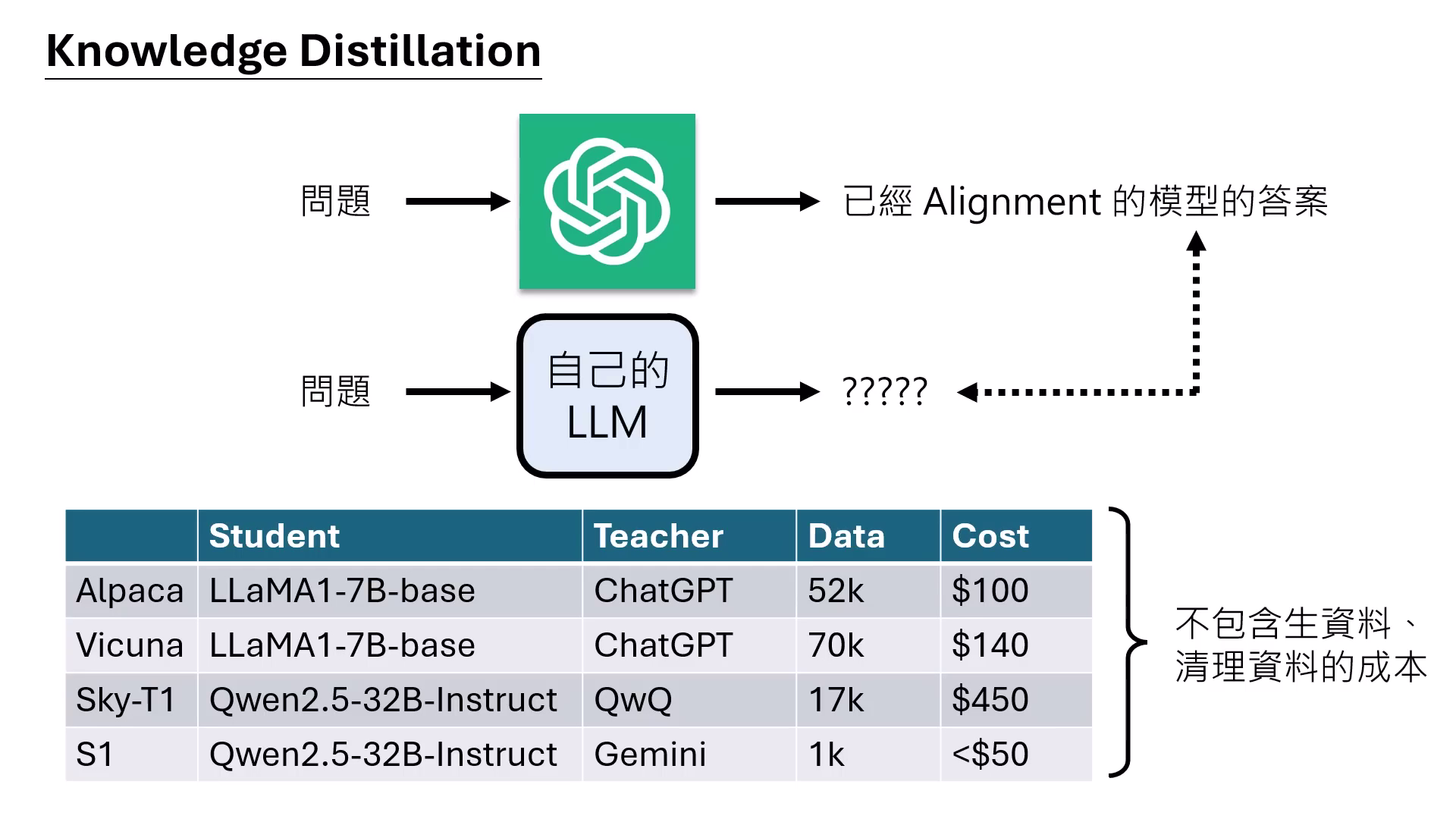
- Knowledge Distillation(知識蒸餾):將 GPT-4 等強大模型當作老師,讓自己的模型學習老師的回答,能以極低成本(如 100~500 美金)瞬間暴增模型能力。
 |  |  |
|---|---|---|
| 資料量小、品質極大化 | 弱智吧 (Ruozhiba) 的奇效 | Knowledge Distillation(知識蒸餾) |
Alignment 前後的真實差異與機制
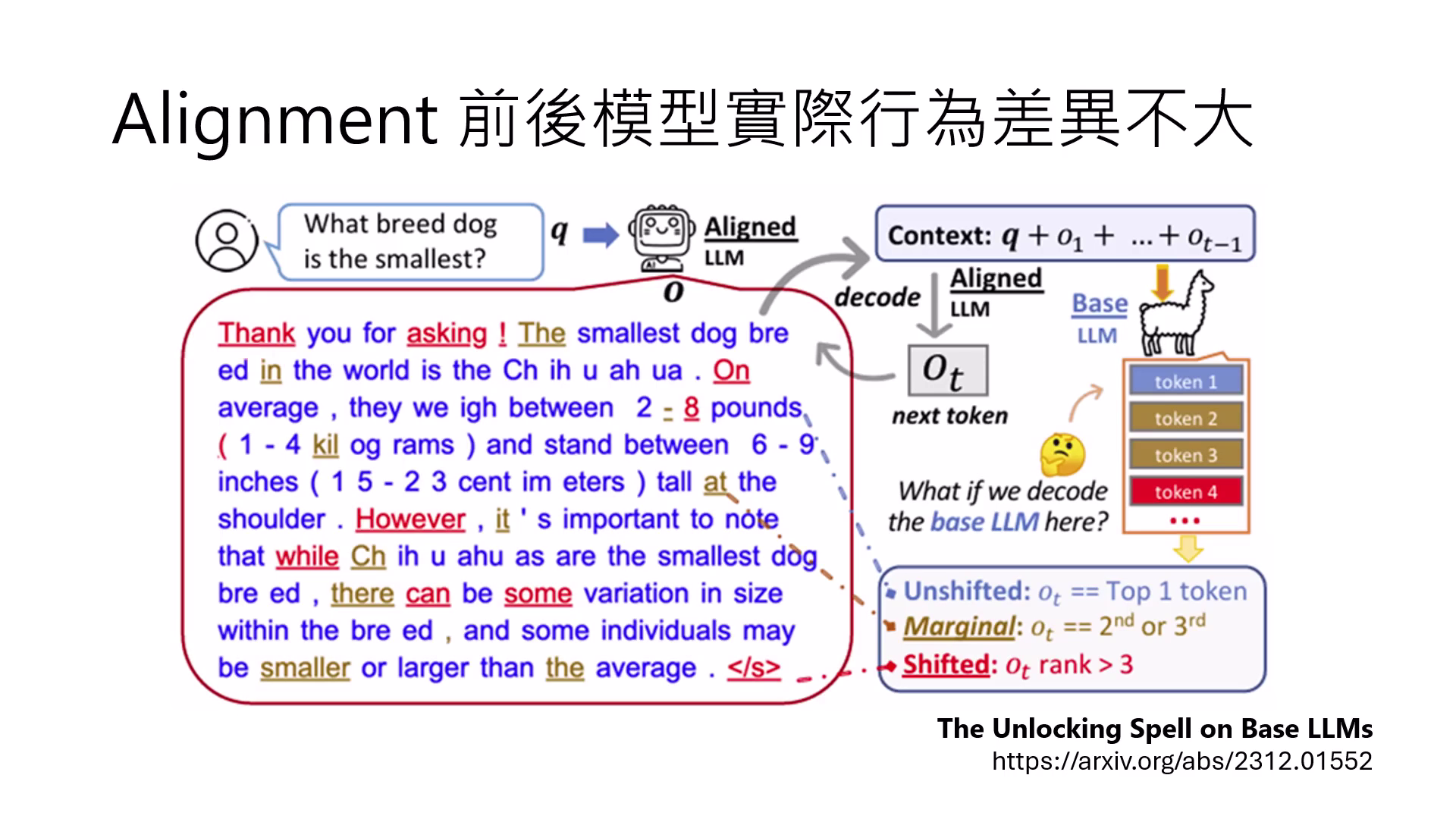
- 行為差異不大:研究顯示,對齊前後模型輸出字詞機率的排序(Shifted Token)變化比例極小。
- 調整核心在於「結束」與「連接」:對齊主要改變的是模型開頭的客套話、連接詞,以及學會何時輸出結束符號以停止暴走反覆。
Response Tuning
不給問題,只讓模型學習產生高品質答案,也能達到不錯的效果。

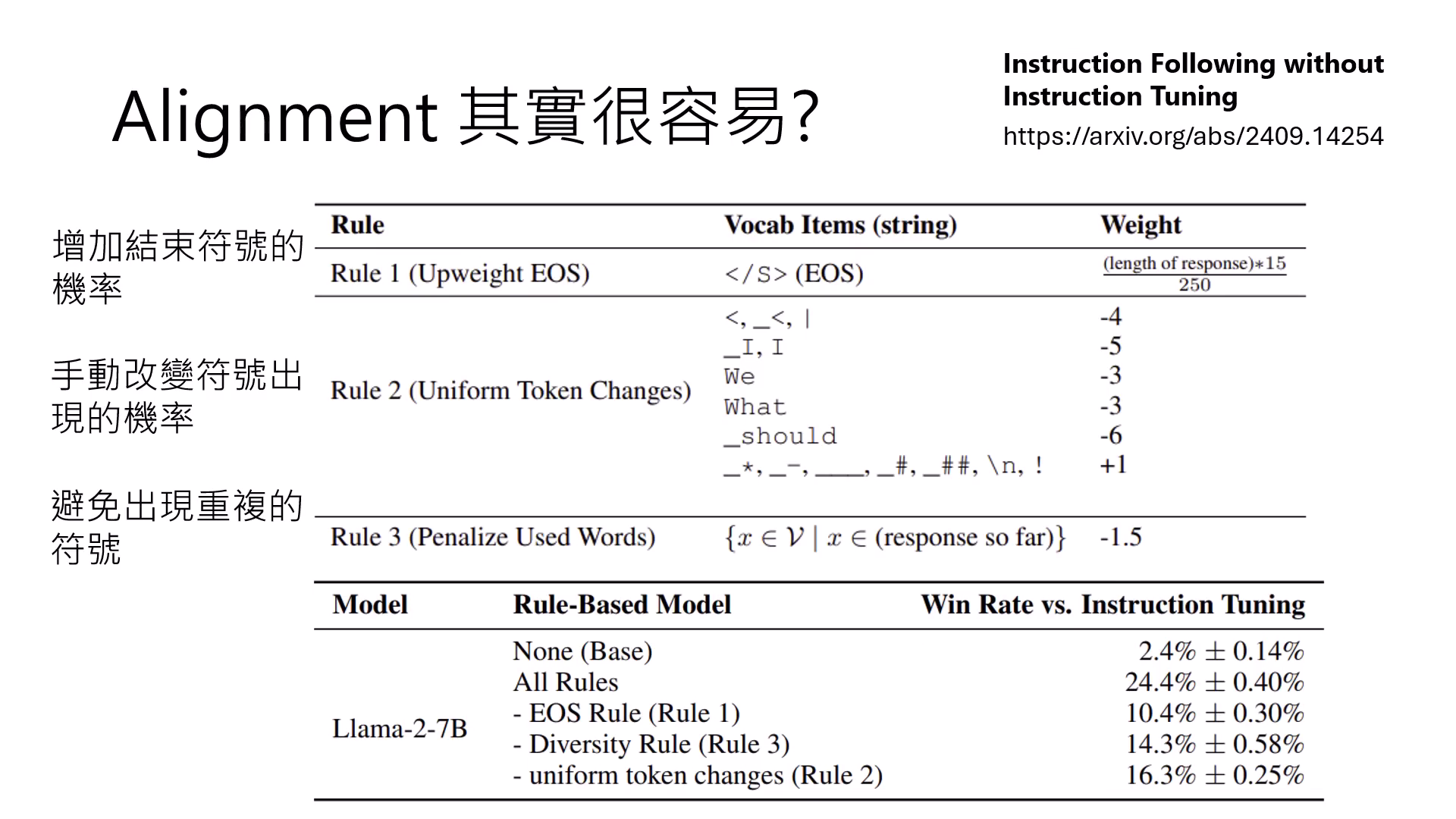
Rule-based Adapter
甚至不微調參數,僅透過手動調整結束符號與重複字詞的機率,就能讓 Base 模型提升至與微調模型一戰的能力。
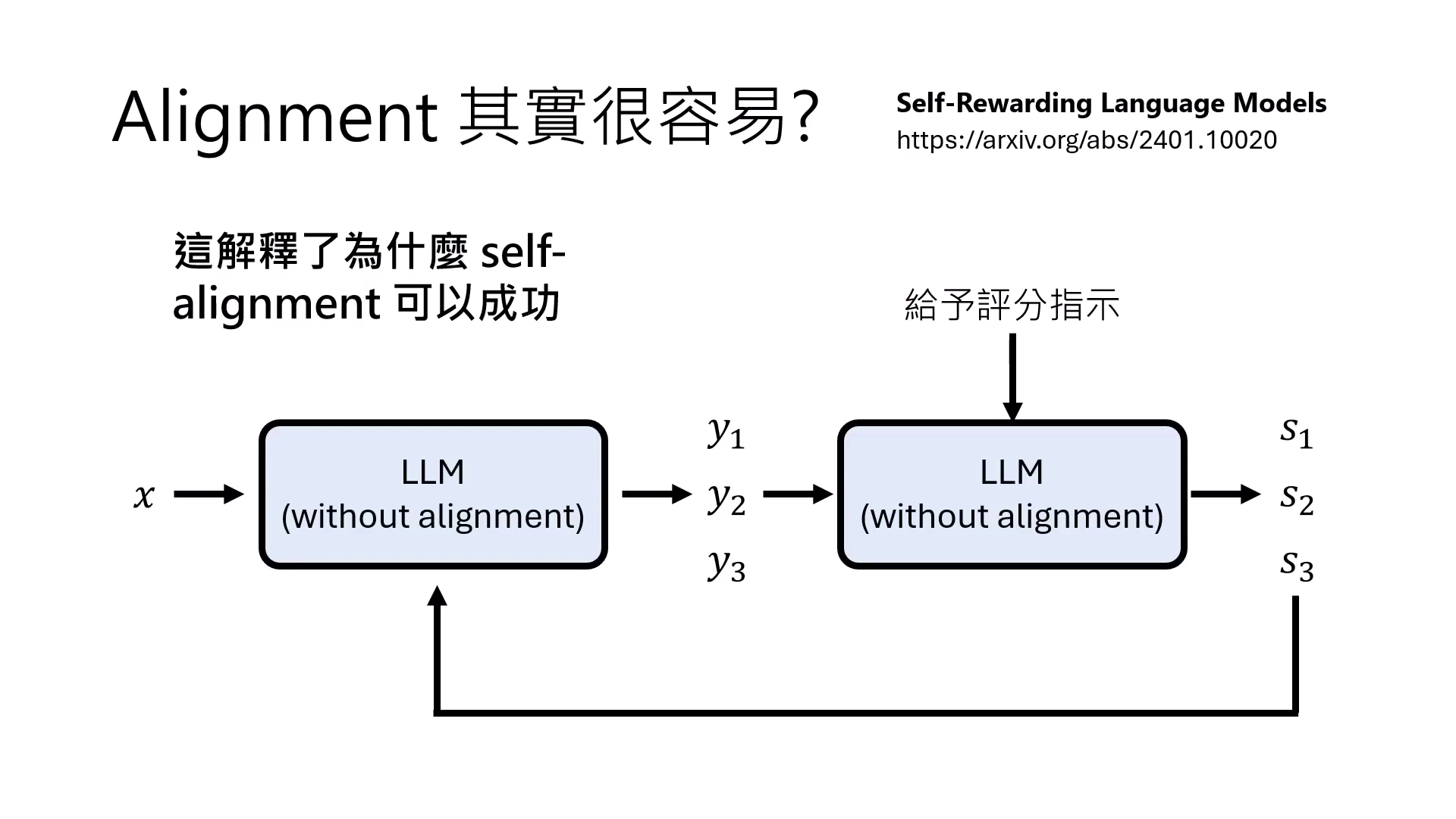
Self-alignment
讓模型針對同問題產出多個答案並自我評分,再進行強化學習,讓模型自動對齊。
如何達成有效的 Pre-train?
多樣化與實體改寫 (Rephrasing)
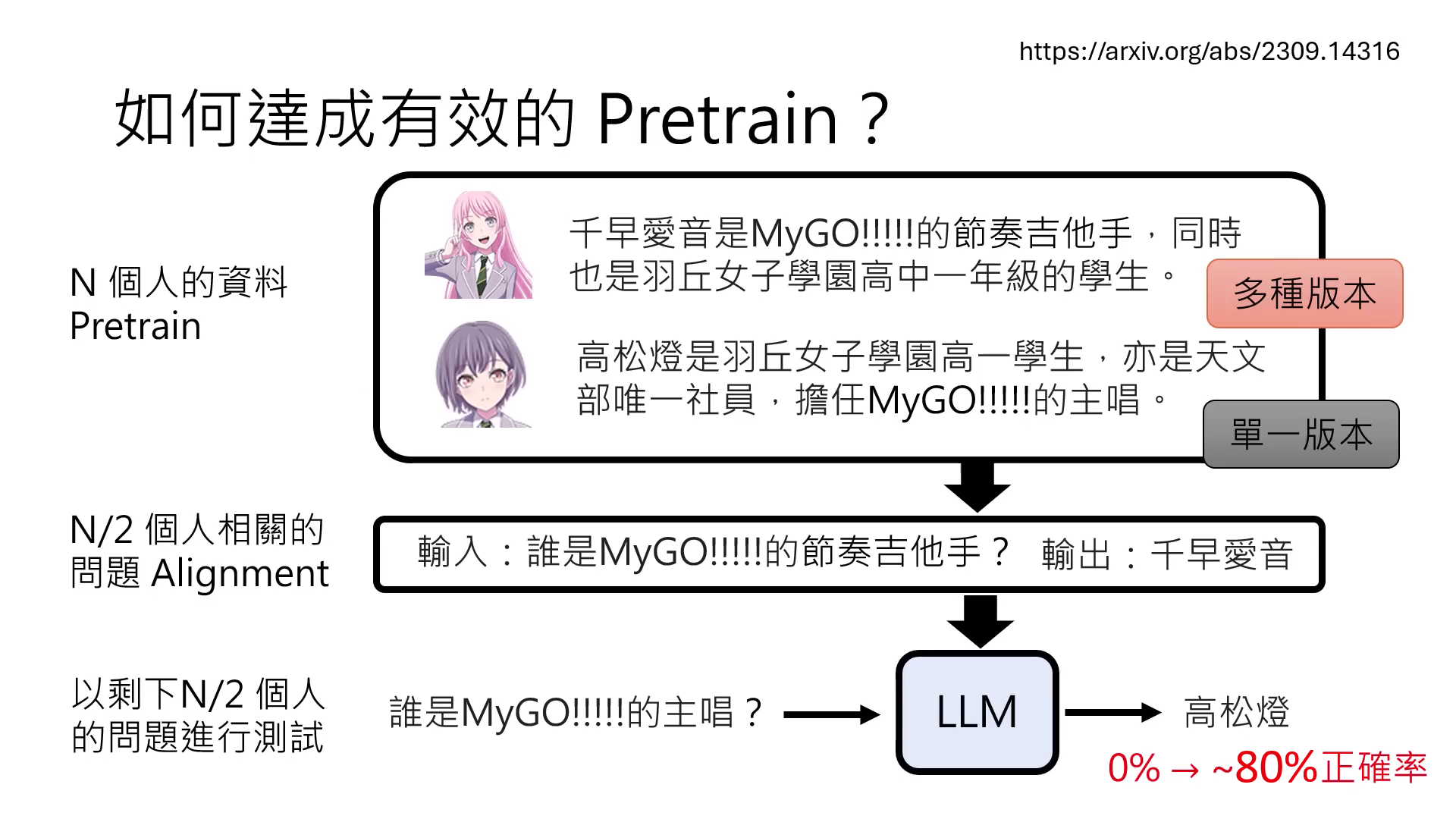
若同一知識在預訓練中只出現一次,模型會將整段描述視為單一實體而產生誤解。必須透過多種改寫版本(詞彙順序調整、不同介紹方式)讓模型學習泛化理解實體性質。
 | 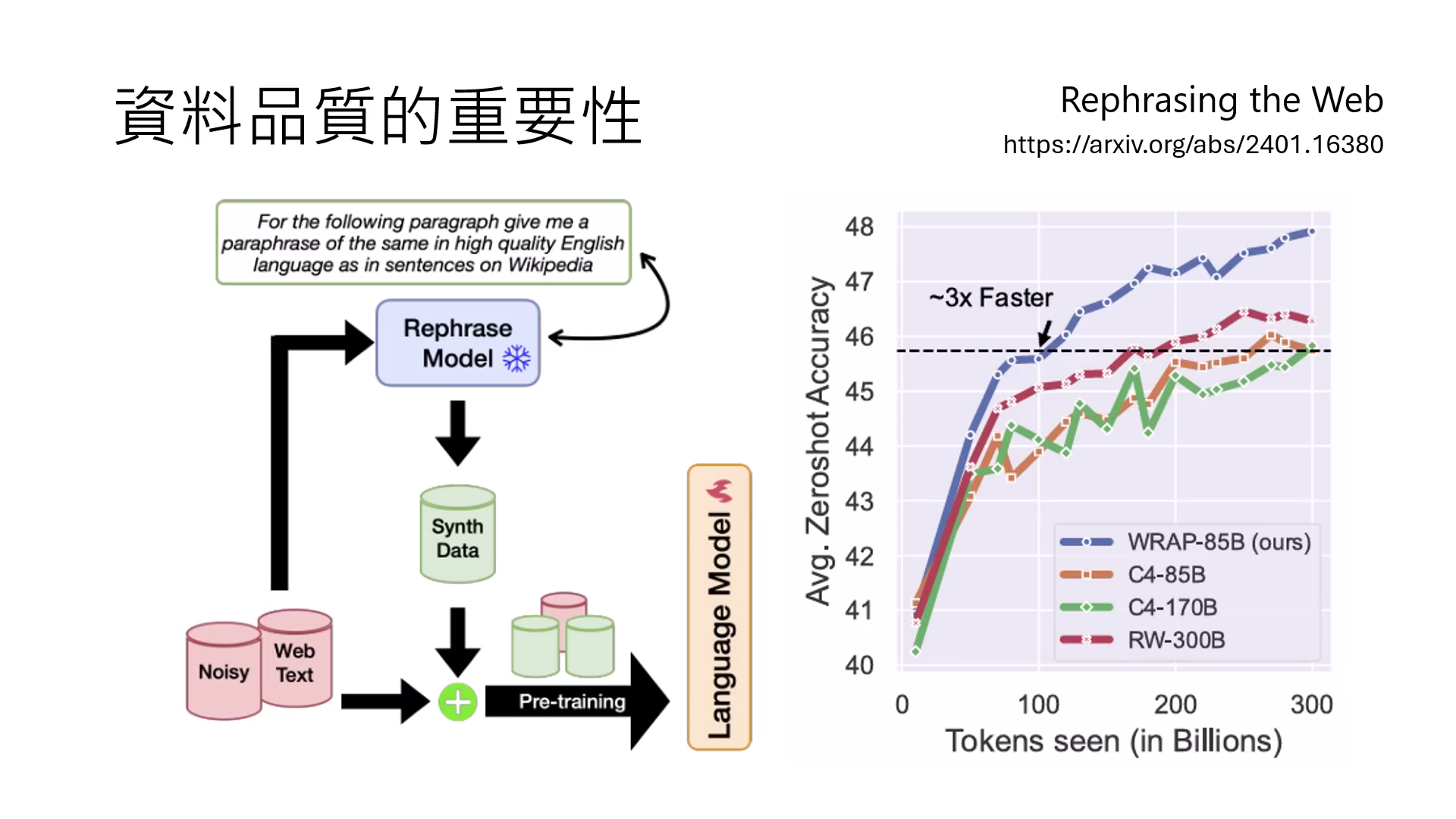 |
|---|---|
| 多樣的主體,可以讓模型更泛用化 | 網路上的資料太髒,經過rephrasing後會比較有效 |
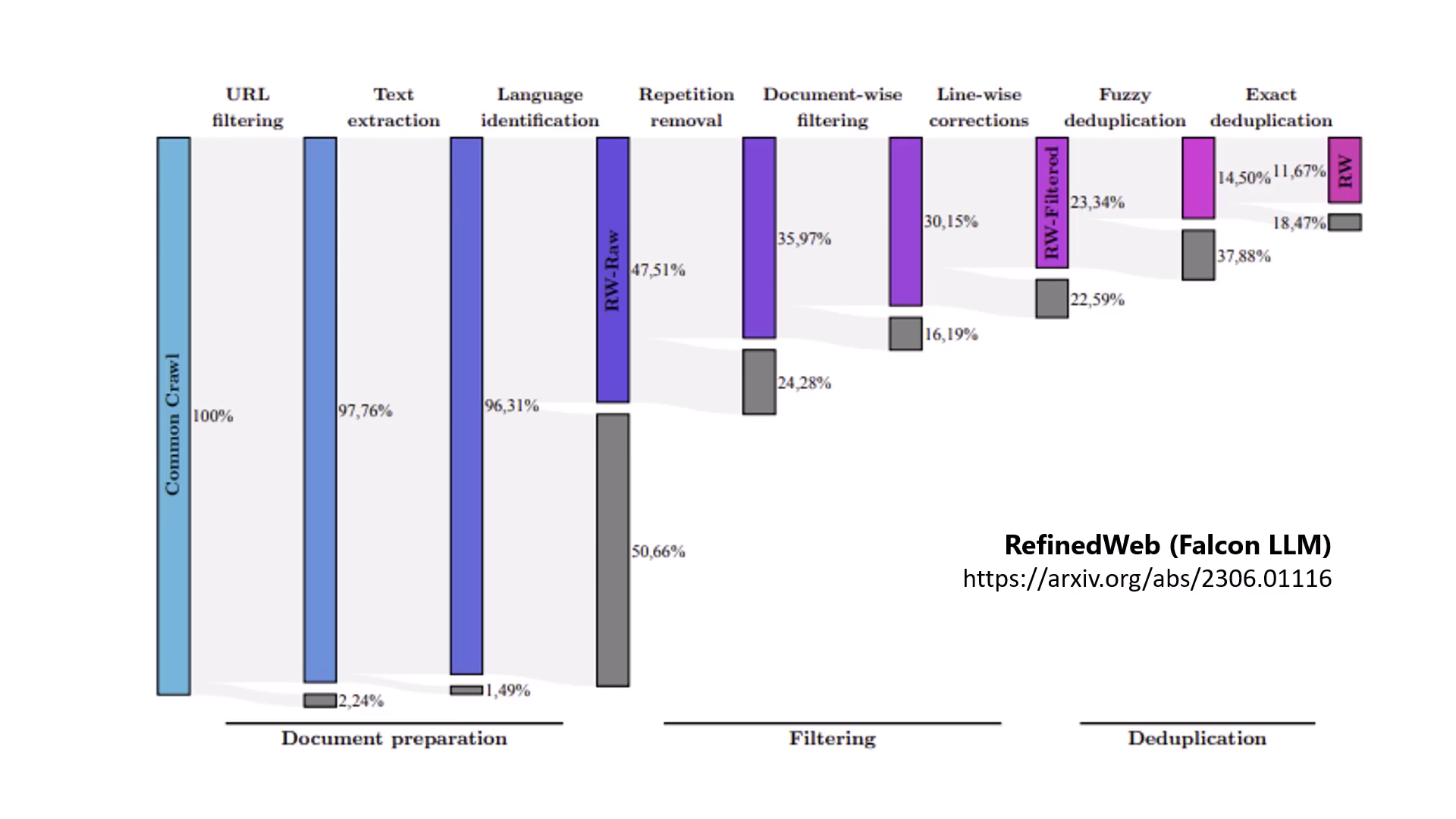
資料過濾與去重
資料品質勝過數量。去除重複文章、過濾網爬資料至剩餘 1/10 才是有效做法。
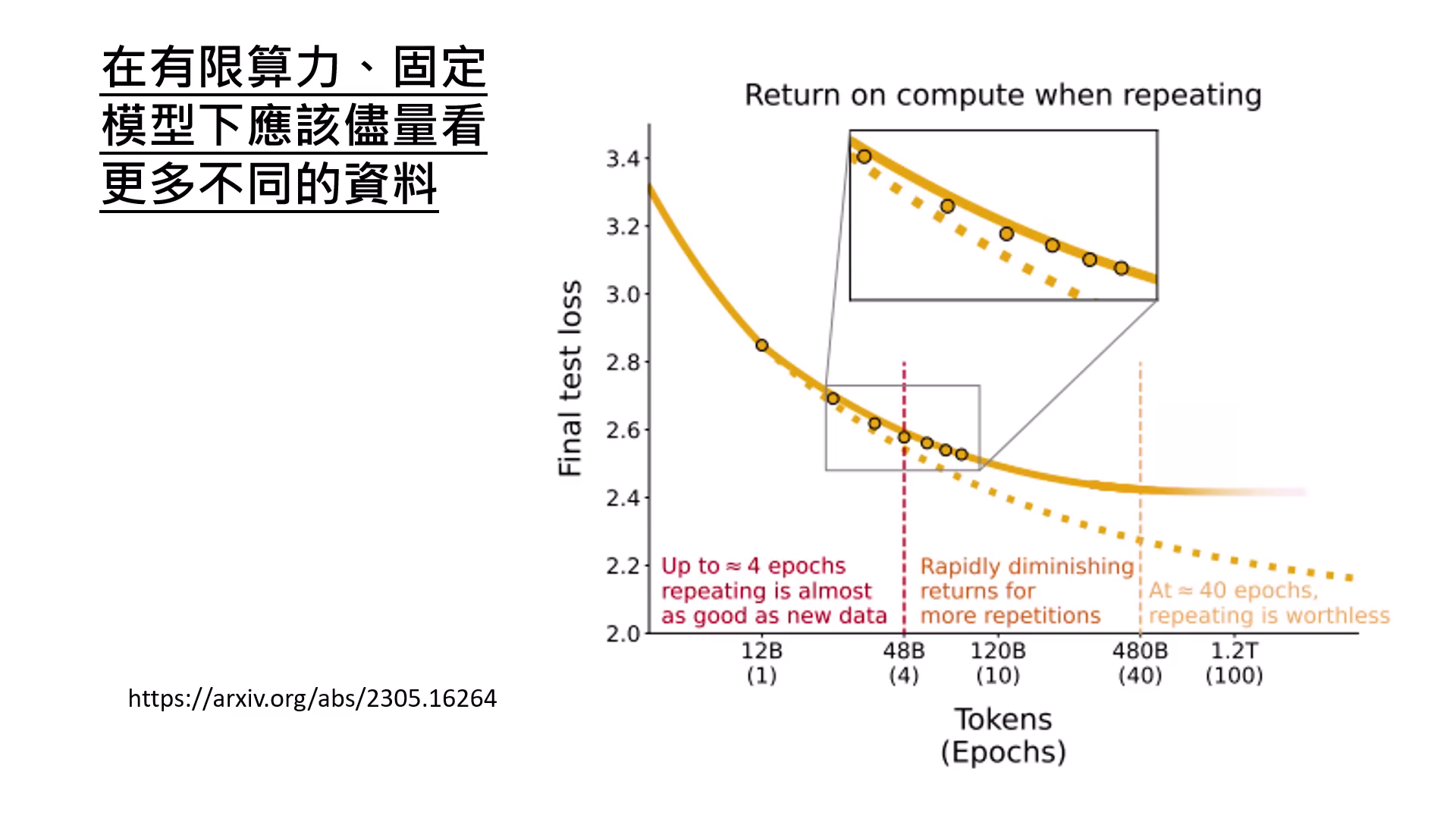
看不同的資料而非複習
在有�限算力下,應讓模型看更多不同的資料,重複看超過 4 次以上對模型能力的提升就會顯著停滯。
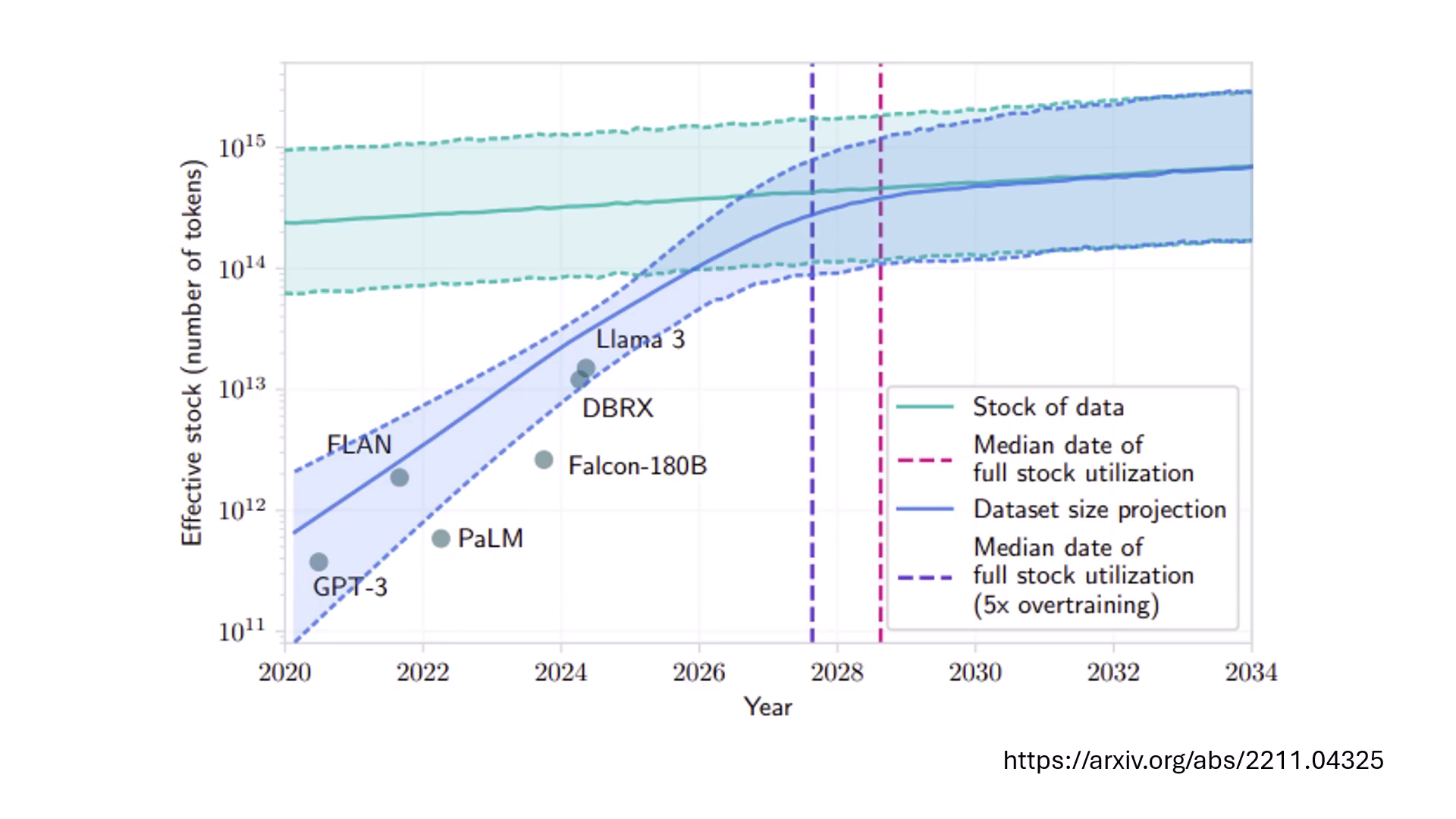
Token 枯竭危機
模型訓練資料需求每年增長 10 倍,預計 2028 至 2030 年間,網路上可用的高品質文本資料將被用盡。
Alignment 的極限:學習新知識的難題
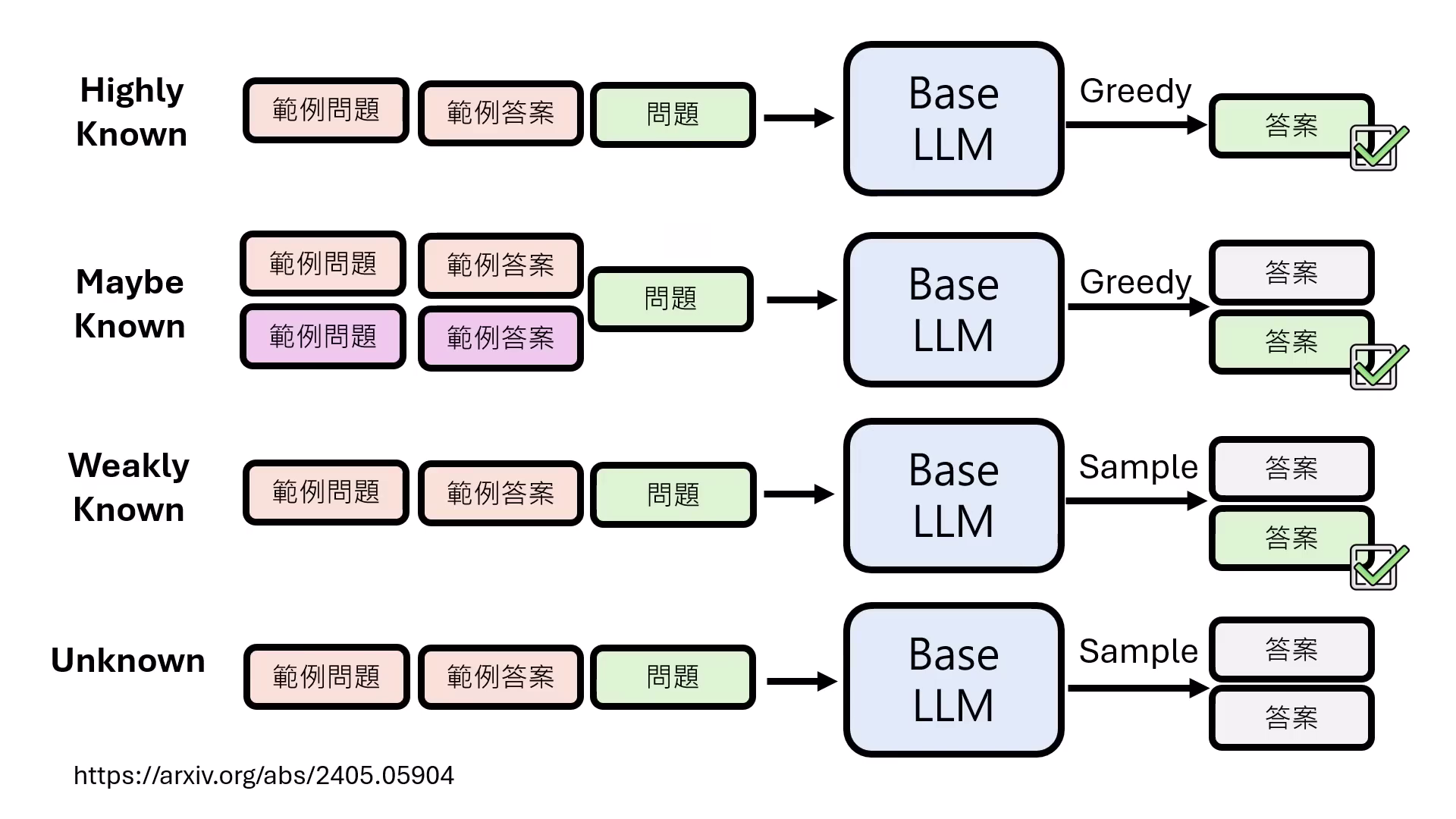
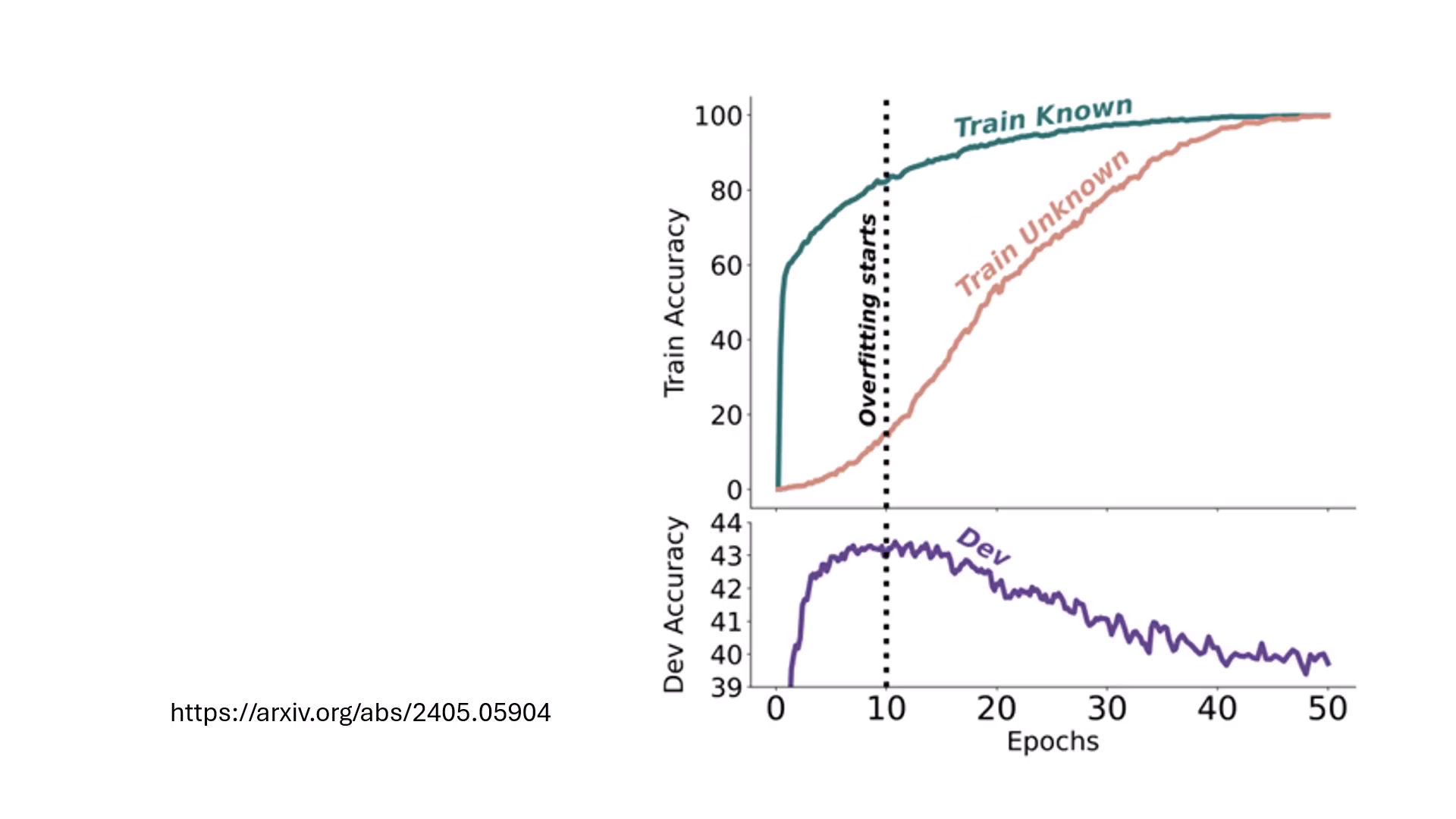
資料掌握度的四種分級
研究將 Alignment 資料依模型在 Pre-train 階段的掌握程度分為:
- Highly Known:直接做文字接龍即可答對。
- Maybe Known:原本答錯,但換一種問法(提示詞或範例)就能答對的知識。
- Weakly Known:需透過 Sampling(多抽幾次答案)才有機會答對。
- Unknown:模型無論如何都��無法答對的未知領域。
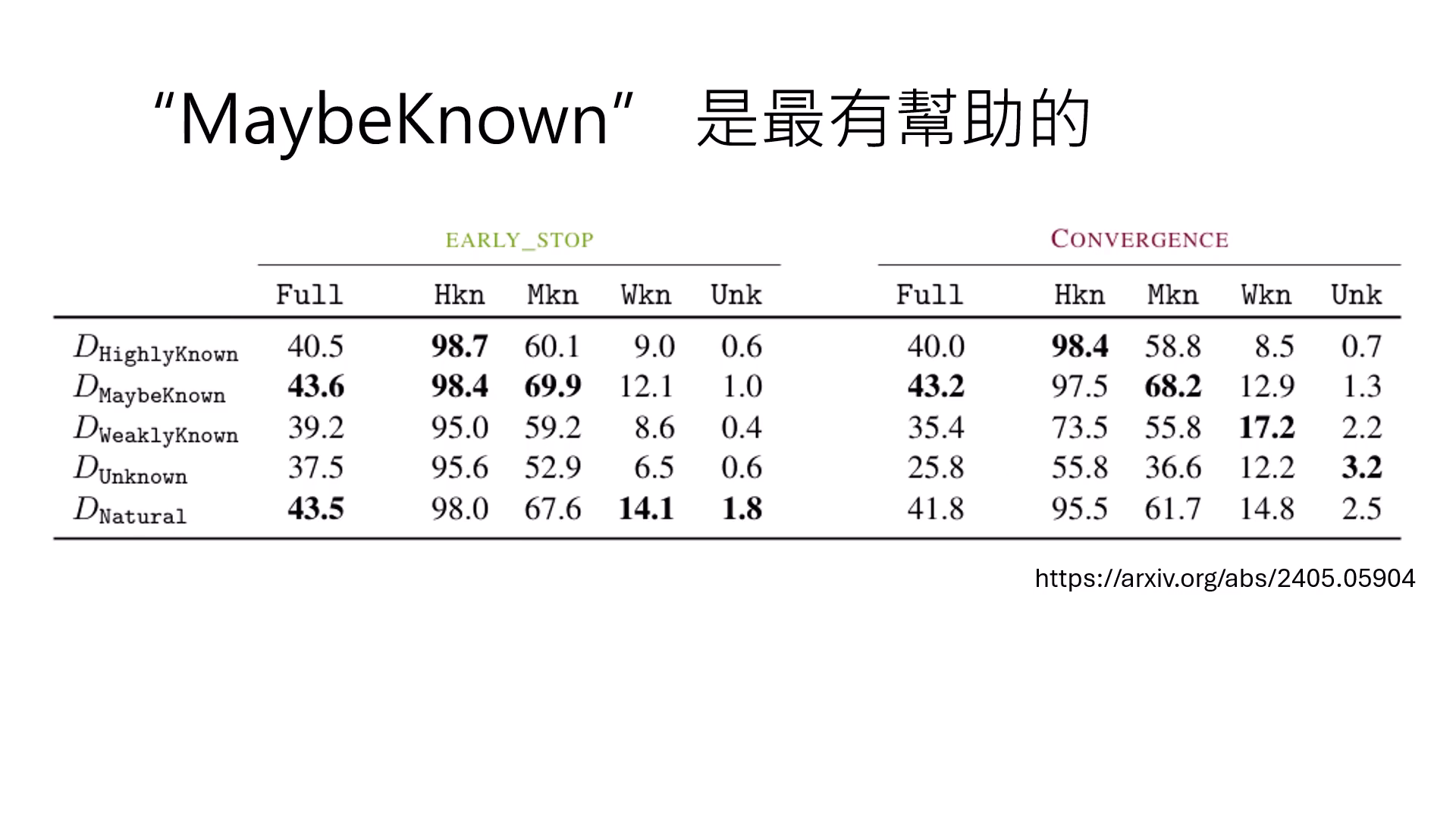
Maybe Known 是最有幫助的
實驗證明,對 Alignment 最有幫助的並非新知識,而是 Maybe Known 類型的資料。這代表模型內部已有相關知識,只是「不知道要回答」,對齊的作用在於調整行為,激發模型將這些本來就會但不知如何表達的潛力釋放出來。
強學 Unknown 的副作用
如果強迫模型在對齊階段學習完全未知的知識(Unknown),模型不僅學不會新知,反而會因為強行改動參數而破壞既有的能力,導致測試集(Dev set)的正確率顯著下降。
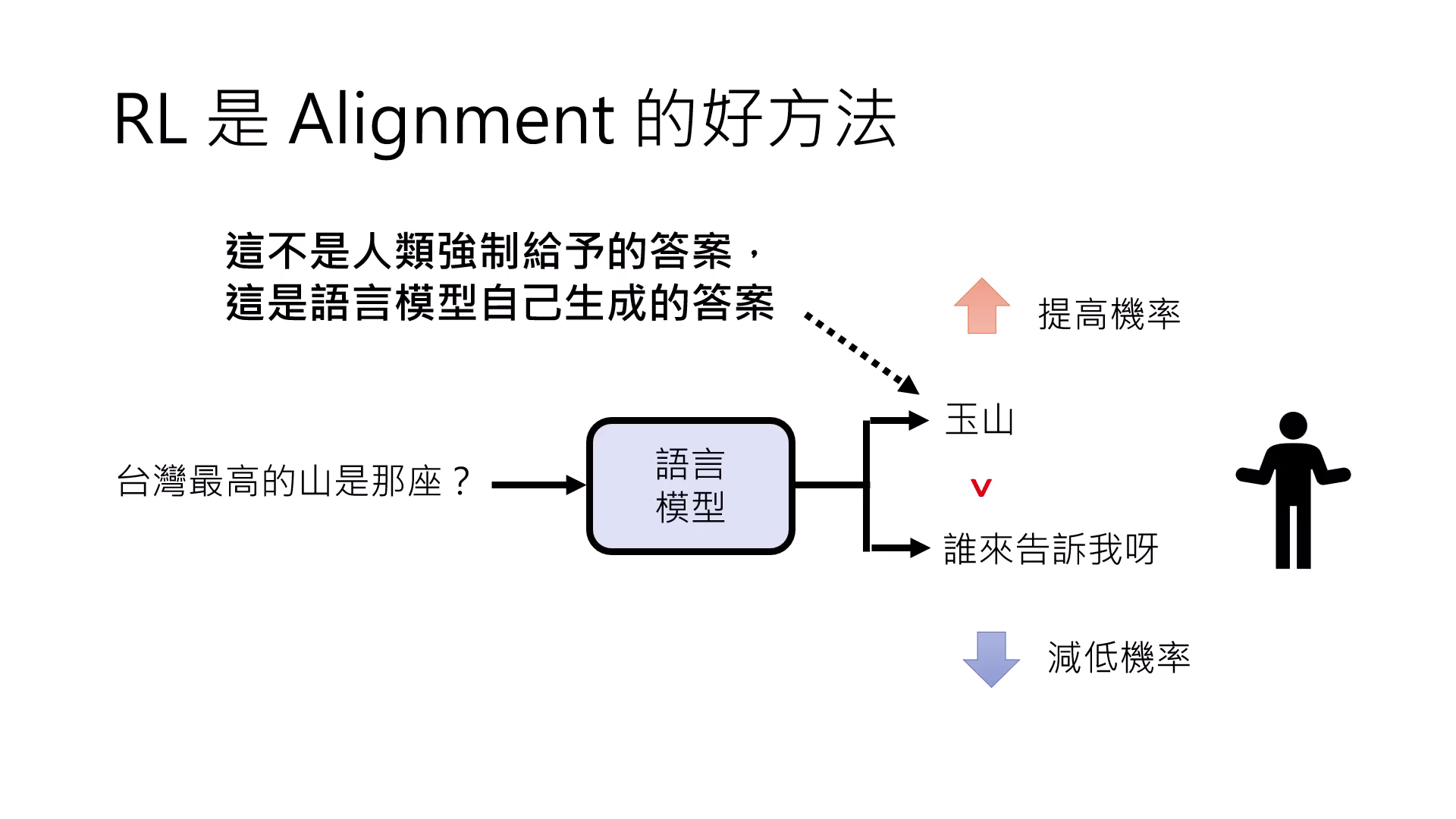
RL 是 Alignment的好方法
RL 的機制是針對模型「自己生成」的答案給予獎懲,這意味著模型提高機率的內容必須是它「本來就回答得出來」的東西。因此,Alignment 只是在調整模型行為,難以彌補 Pre-train 階段沒學會的技能。
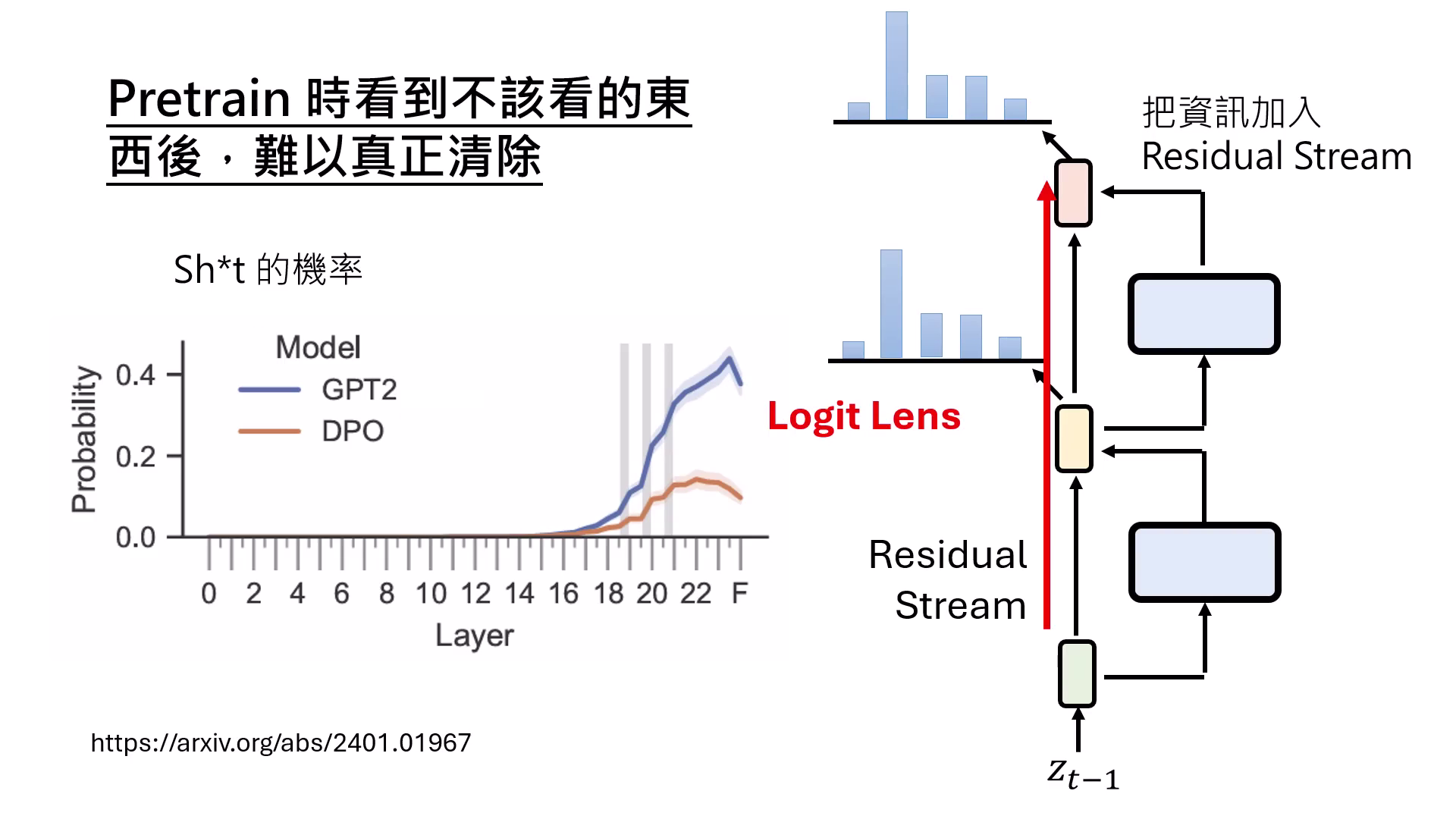
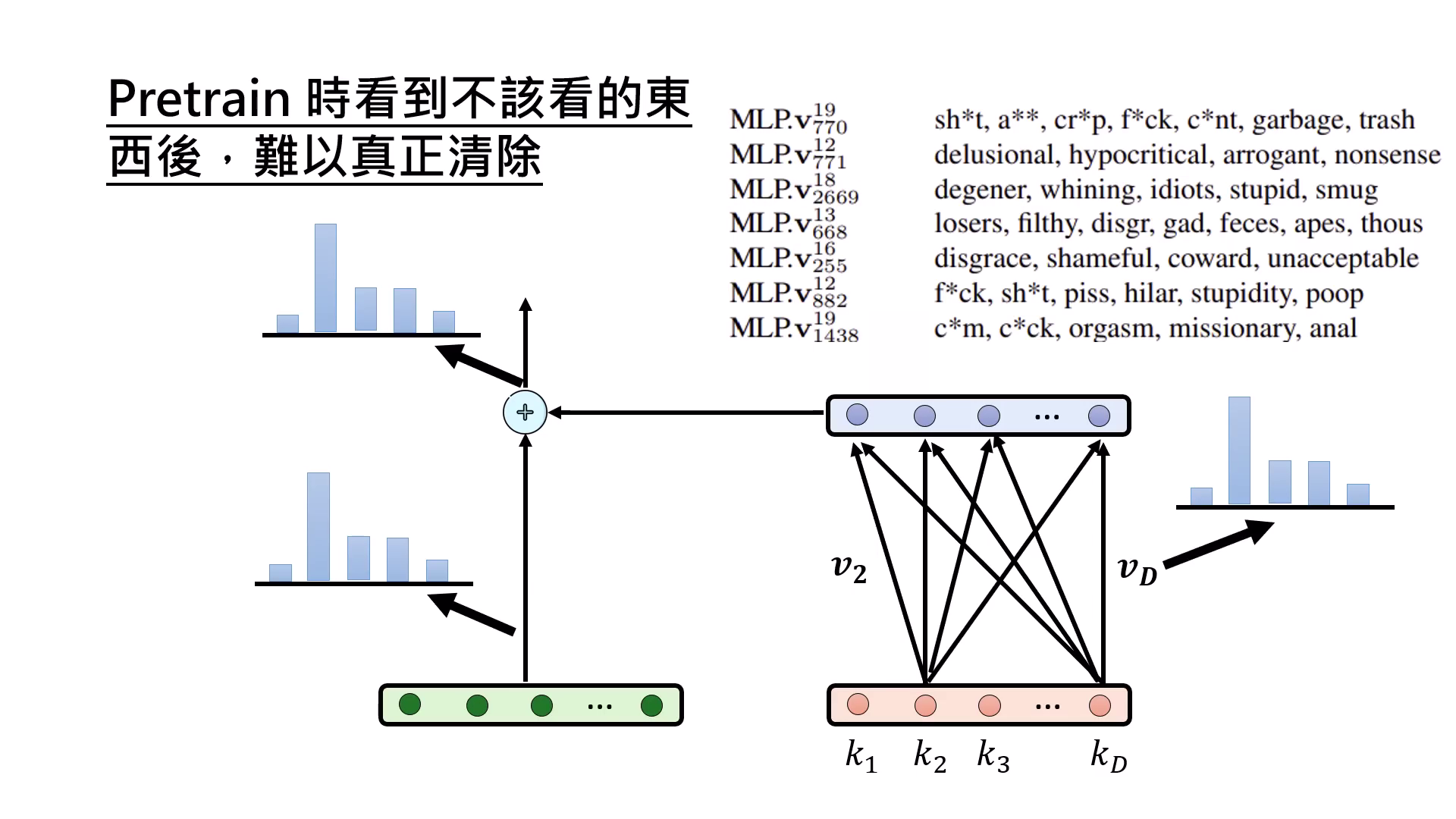
Alignment 無法抹除 Pre-training 的影響
Alignment 猶如給模型戴上面具。雖然能壓抑髒話或色情內容的產出,但相關知識仍存在於參數(Weights)中,只是對應的啟動數值(Keys)被控制住不去觸發而已。
 |  |
|---|---|
| 從Residual Stream的角度看為什麼無法消除 | 相關知識仍存在於參數(Weights)中,對應的啟動數值(Keys)被控制住不去觸發 |
Alignment 只是畫龍�點睛
LLM 在 Pre-train 階段已奠定大局,Alignment 只是畫龍點睛,無法補救 Pre-train 階段沒學會的技能。
