大型語言模型評估 (Evaluation) 的挑戰與迷思
如何評量模型的「推理」能力?(Reasoning Evaluation)
現狀:簡單粗暴的數學題
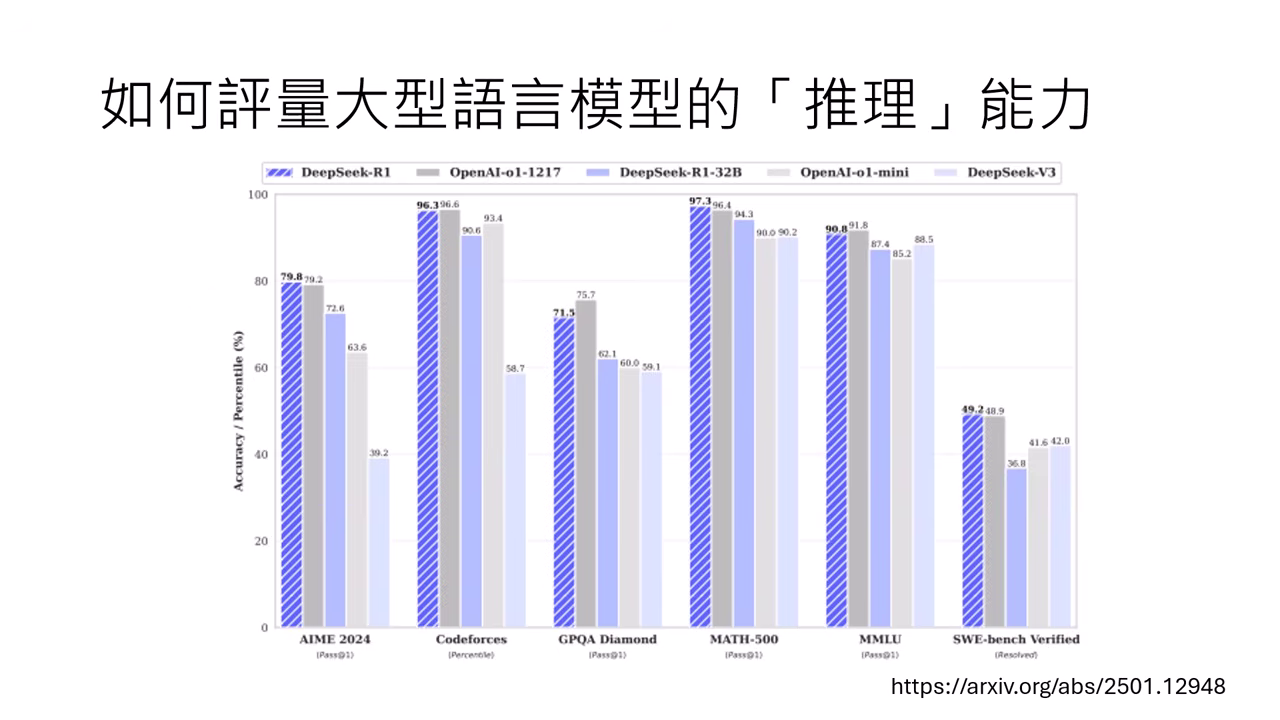
- 目前評量模型推理能力最常用的方式,就是直接考它數學問題(如 AIME、GSM8K)。答對了就當作有推理能力,答錯了就當作沒有。
- DeepSeek 與 o1 的例子:DeepSeek 技術報告與 OpenAI o1 發布時,都大量使用數學競賽題(如 AIME)的正確率來展示其優越的推論能力。
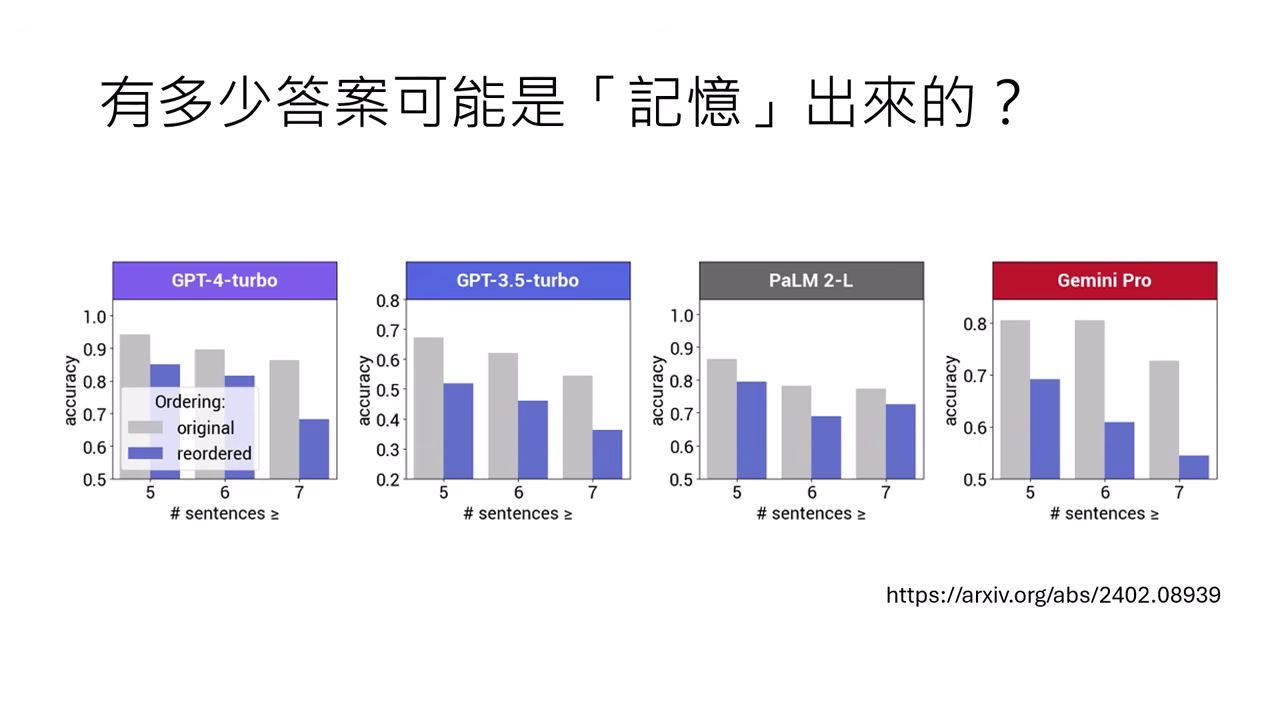
核心質疑:是推理 (Reasoning) 還是記憶 (Memorization)?
- 模型可能只是剛好在訓練資料中看過這題數學題,憑藉記憶輸出答案,而非真的進行了推理。

驗證實驗:GSM8K 變體測試
- 替換無關變量:研究者將 GSM8K 中的人名(如 Sophia 改掉)、數字或親戚關係替換掉,照理說題目難度不變。
- 結果:多數模型(如 Mistral, Gemma)正確率顯著下降,顯示它們可能只是「背」到了原題的答案。不過 o1-mini 受到的影響較小。
- 語序對調:將題目中的句子順序對調,但不影響語意。
- 結果:正確率依然下降,代表模型學到了順序等不該學的特徵。
- 加入干擾句:在題目中加入完全不相干的句子(如「有幾顆蘋果爛掉了」)。模型往往會想太多而答錯(雖然人類也可能因此被混淆)。

資料污染 (Data Contamination) 的難題
- 很難完全確保模型沒看過考題。即便在訓練資料中過濾掉英文版 GSM8K,模型可能看過被翻譯成「蒙古文」的版本,憑藉跨�語言能力依然能作弊。
智力測驗型的評估:ARC-AGI
什麼是 ARC-AGI?
- 背景:由 Keras 作者(François Chollet)於 2019 年提出。
- 形式:類似人類智力測驗的圖形推理題(輸入幾張圖的變換規則,預測下一張圖)。雖然是圖形題,但丟給 LLM 時會轉換成文字格式(用數字代表顏色,如 0=無色, 1-9=不同顏色)。
- 目的:設計上希望模型無法靠「背誦」網路知識來回答,必須具備真正的推理能力(General Intelligence)。且擁有未公開的 Testing Set。
 |  |
|---|---|
| arc-agi 的題目類型 | 圖型會被轉換成文字格式,讓 LLM 能處理 |
評測表現
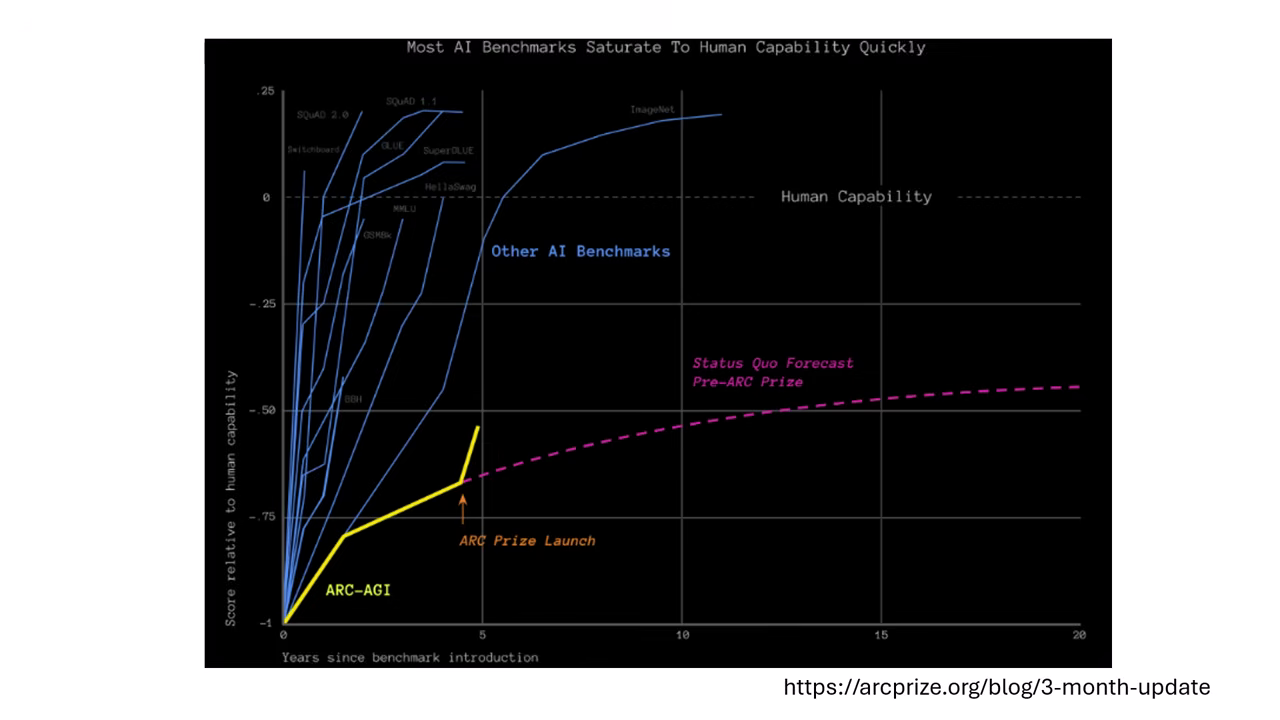
- 高難度:釋出五年來,多數模型都無法有效突破,不像其他 Benchmark 兩三年就被玩壞。
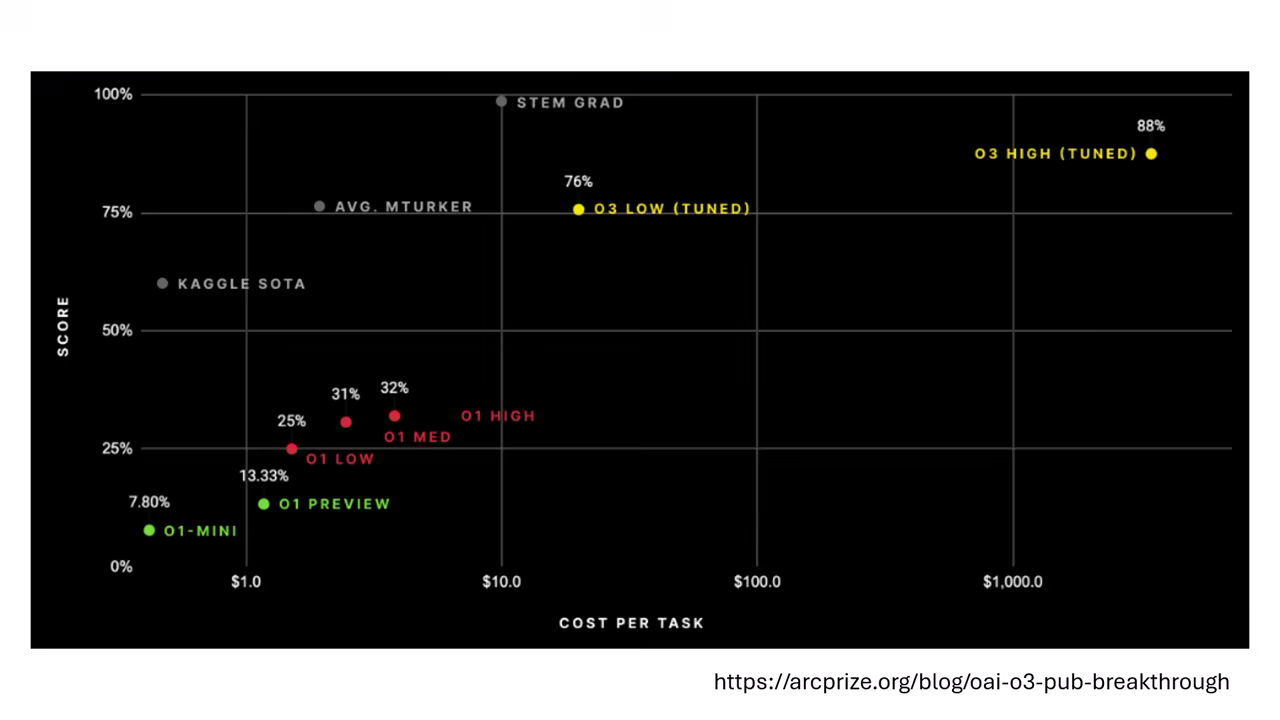
- o3 的突破:o3 模型的表現介於一般人類與理工科畢業生之間,是目前的強者。
- 代價:o3 在此任務上的推論成本極高,回答一個問題需耗費約 1,000 美金的算力。
 |  |
|---|---|
| arc-agi 的高難度 | o3 的突破與代價 |
潛在弱點
- 雖然題目不公開,但若根據公開的範例題自動生成數千萬題類似題目讓模型狂刷(Hack),模型可能還是能透過「背題型」來取得高分。
眾人盲測平台:Chatbot Arena
運作機制
- 盲測 (Blind Test):系統隨機給出兩個匿名模型(Model A vs Model B),使用者問同一個問題,根據回答選出誰比較好。
- 優勢:題目由全世界使用者即時輸入,模型無法針對特定題庫作弊。

人類評分的偏見 (Bias)
- 風格大於實力:人類並非完美的裁判,往往更喜歡有 Emoji、有粗體條列 (Bullet points)、回答篇幅較長、語氣自信的模型,即便內容準確度差不多。
- 難辨真假:當模型能力超越一般人時,人類其實看不出模型是否在「一本正經地胡說八道」,最後只能憑語氣或排版打分。
Elo Score 與戰力校正
- 基礎算法:利用 Elo Rating System,根據勝率 () 反推模型戰力 ()。
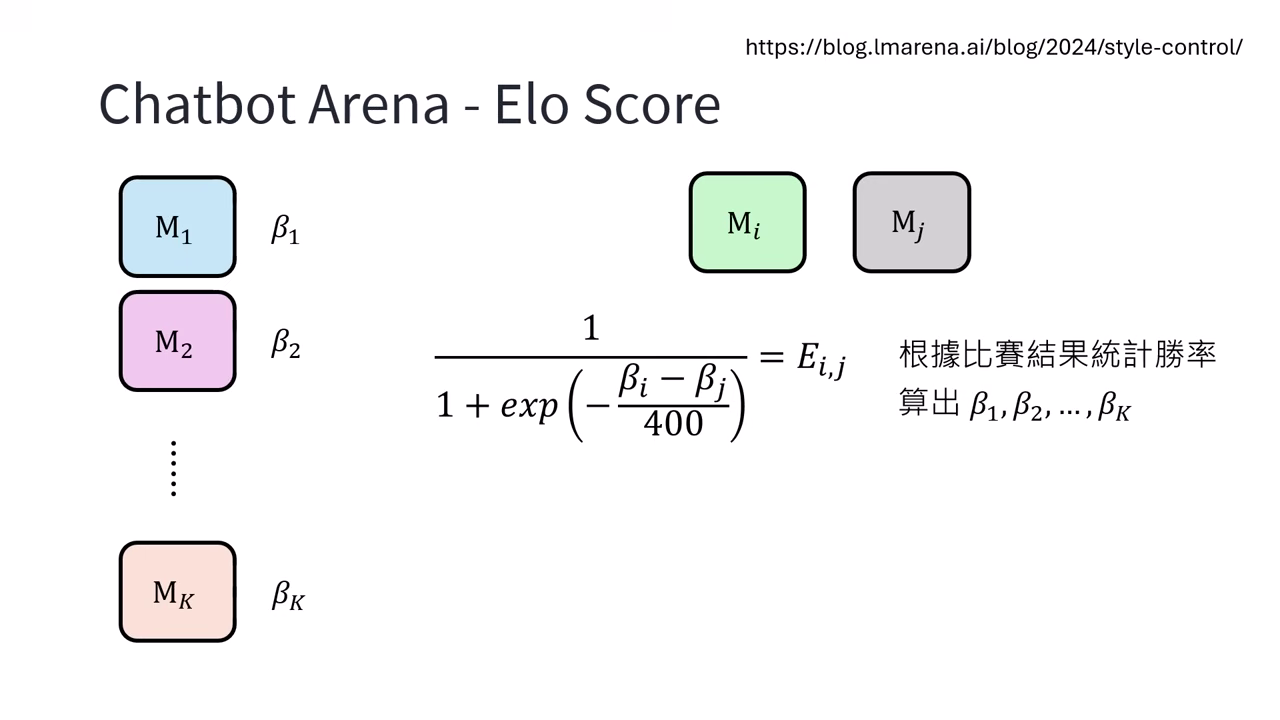
- 校正因子 ():為了消除非實力因素的影響,官方嘗試在公式中加入 來扣除風格分數(如長度、Emoji 數量、格式等)。

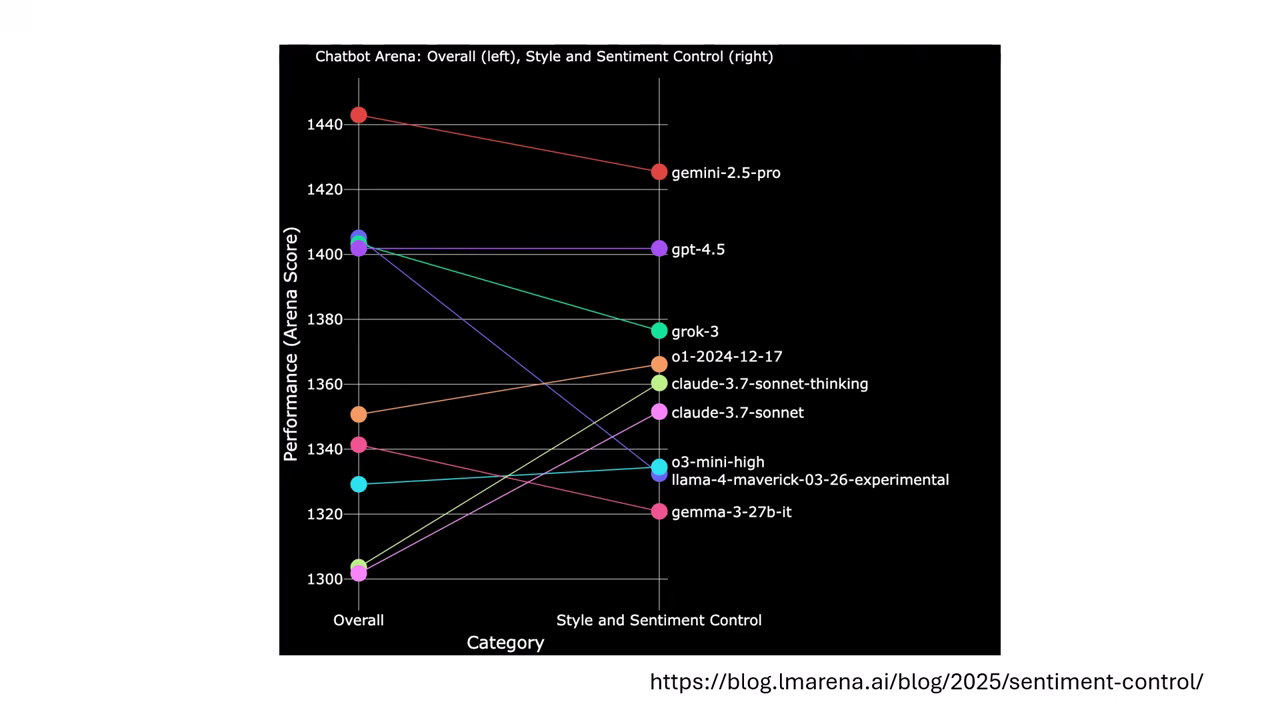
- Claude 的案例:
- 在未校正前,Claude 系列因為「憨慢講話」(不愛用 Emoji、風格嚴肅),排名常被低估。
- 校正後:若去除非實力因素(風格),Claude 的排名會大幅上升,證明它其實很聰明,只是不討喜。
|
古德哈特定律 (Goodhart's Law)
「一項指標一旦被當作目標,它就不再是一個好的指標。」 (When a measure becomes a target, it ceases to be a good measure)。
眼鏡蛇效應 (Cobra Effect)
- 故事:英國殖民印度時期為了減少眼鏡蛇,祭出「抓蛇換賞金」政策。結果印度人開始在家裡養蛇來換錢,導致蛇反而變�多了。
- AI 界的啟示:如果過度追求某個評分指標(如 Math Accuracy 或 Arena Rank),開發者就會設法 Hack 那個指標(如刷題、優化 Emoji 輸出),反而偏離了原本希望模型變聰明的初衷。

提示
不要過度迷信單一評分系統,它最終都會把模型的努力給「異化」掉。