淺談神奇的 Model Merging 技術
什麼是 Model Merging?
希望模型擁有多項技能
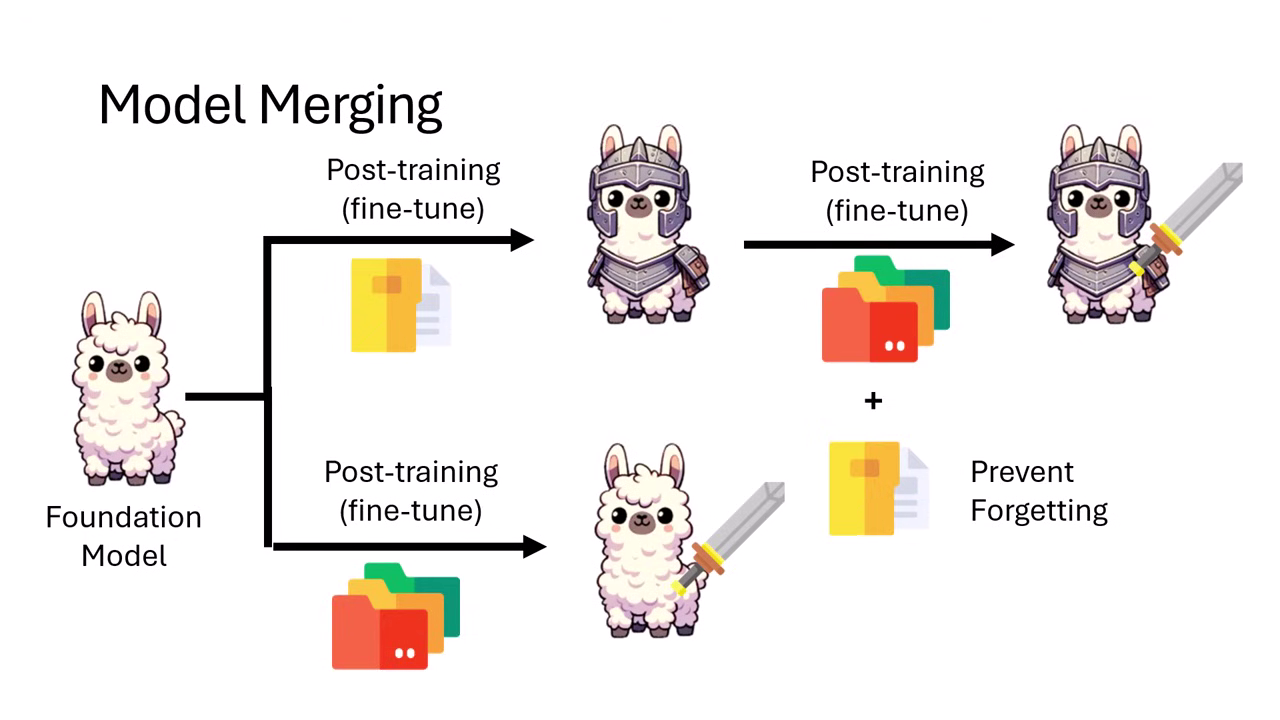
假設我們有一個基礎模型 (Foundation Model) 穿上了盔甲 (具備防禦力,模型 A),隔壁小明練出了另一個拿著劍的模型 (具備攻擊力,模型 B)。
- 目標:我們想要一個既有盔甲又有劍的模型。
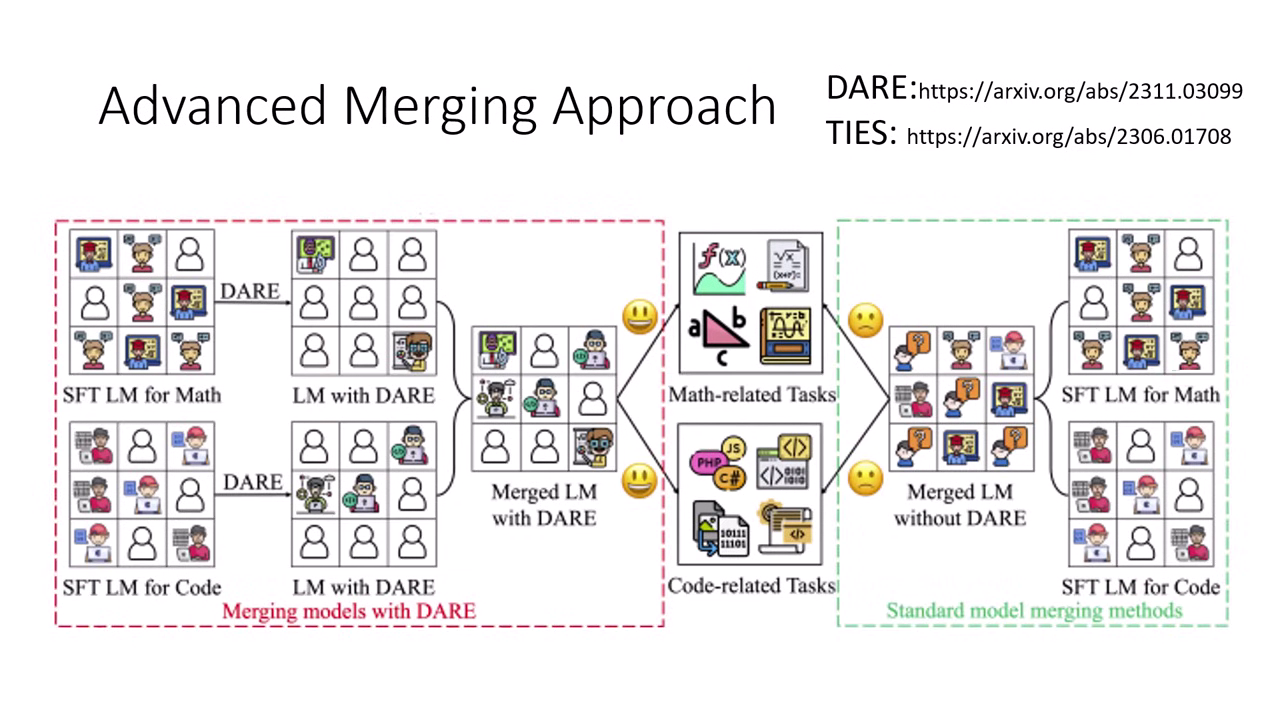
- 傳統做法:跟小明借訓練資料,結合自己的資料,對模型重新進行 Post-training。缺點是需要算力、需要資料,且容易發生災難性遺忘 (Catastrophic Forgetting)。
透過加減運算真的能合併模型能力嗎?
- 不需要資料,也不需要訓練。
- 只要透過簡單的參數加減運算,就能將小明的「劍」直接裝備到你的「盔甲 LLaMA」身上。
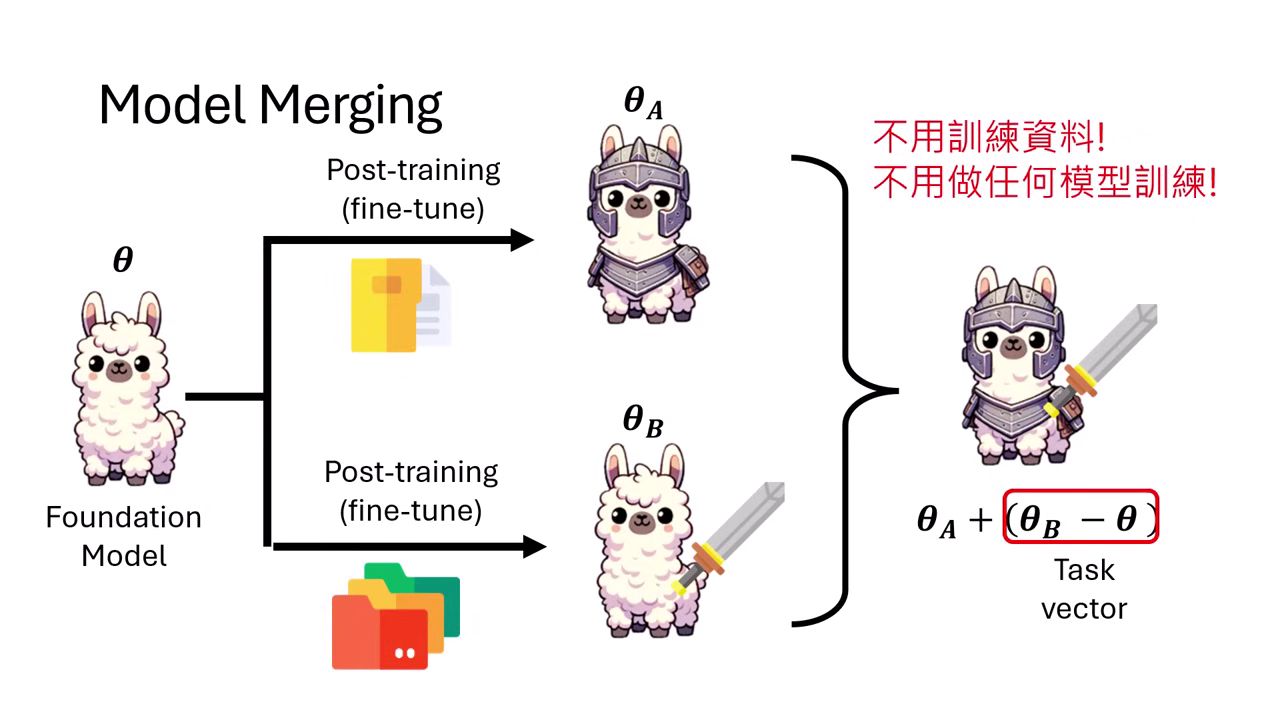
基本假設:參數是可以加加減減的
雖然直觀上覺得「把不同人的手砍下來接在一起 (接枝王葛瑞克)」應該不會變強,但在類神經網路中,參數是可以加加減減的。
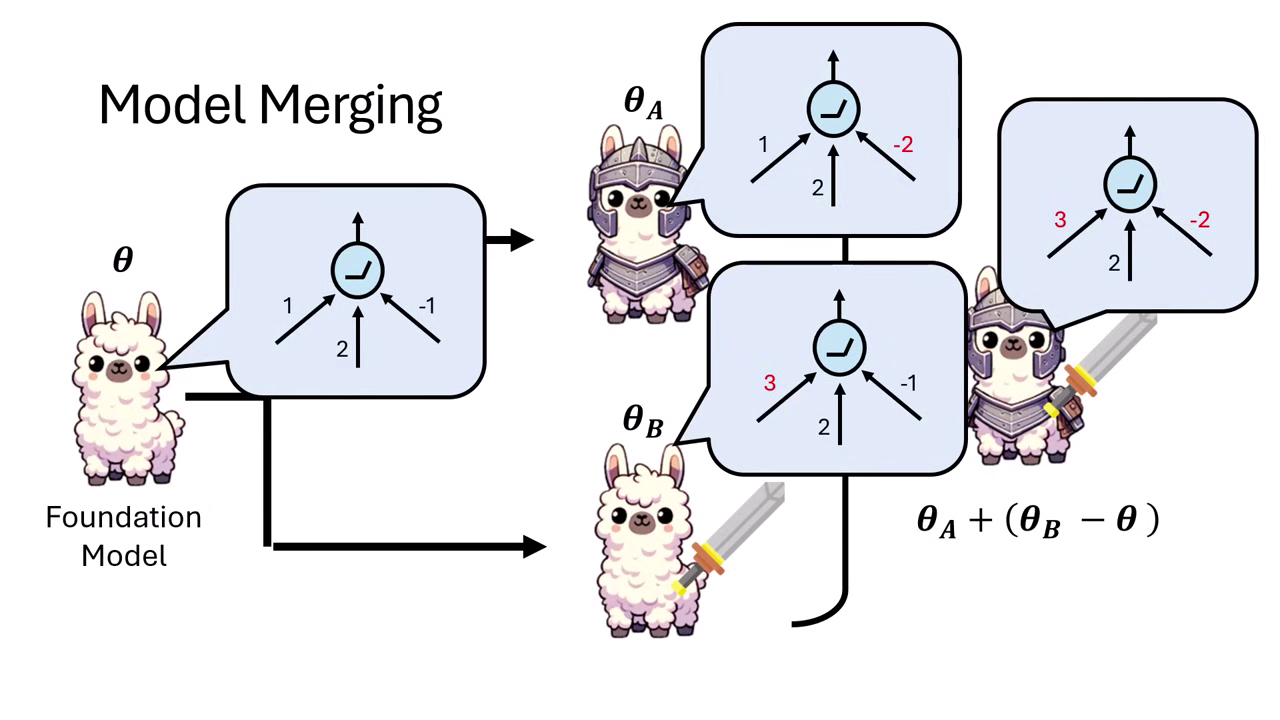
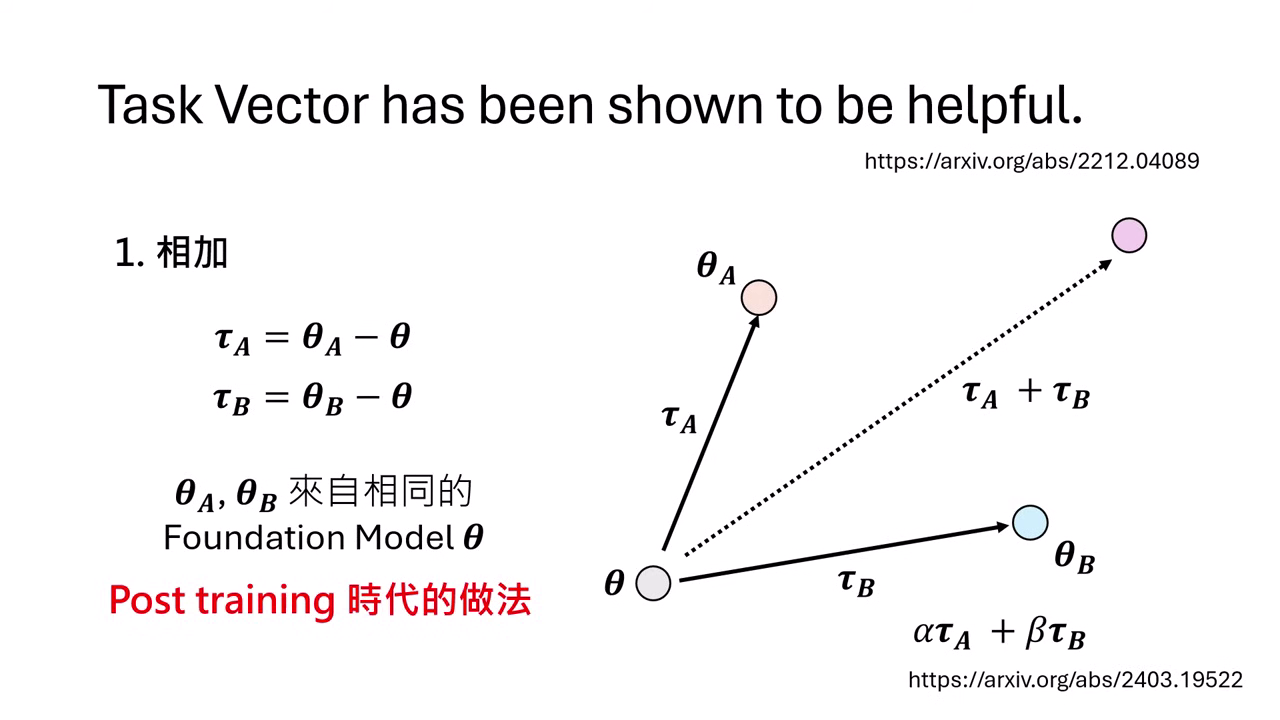
Task Vector (任務向量)
- 假設 Foundation Model 參數為 。
- 經過微調後的模型 A 參數為 ,模型 B 參數為 。
- Task Vector ():代表模型相對於 Foundation Model 額外學到的能力(參數的差)。
- 若要同時擁有 A 和 B 的能力,只需計算:
- 或者也可以引入權重 () 來調整效果:
- 先決條件:
- 與 必須源自於同一個 Foundation Model,且模型架構必須完全相同。
 |  |
|---|---|
| 把不同任務學到的變化加起來,就能合併模型能力 | Post-training 時代的模型能力疊加方法 |
應用一:相加 (Addition) — 組合能力
透過將 Task Vector 相加,讓模型同時具備多種技能。
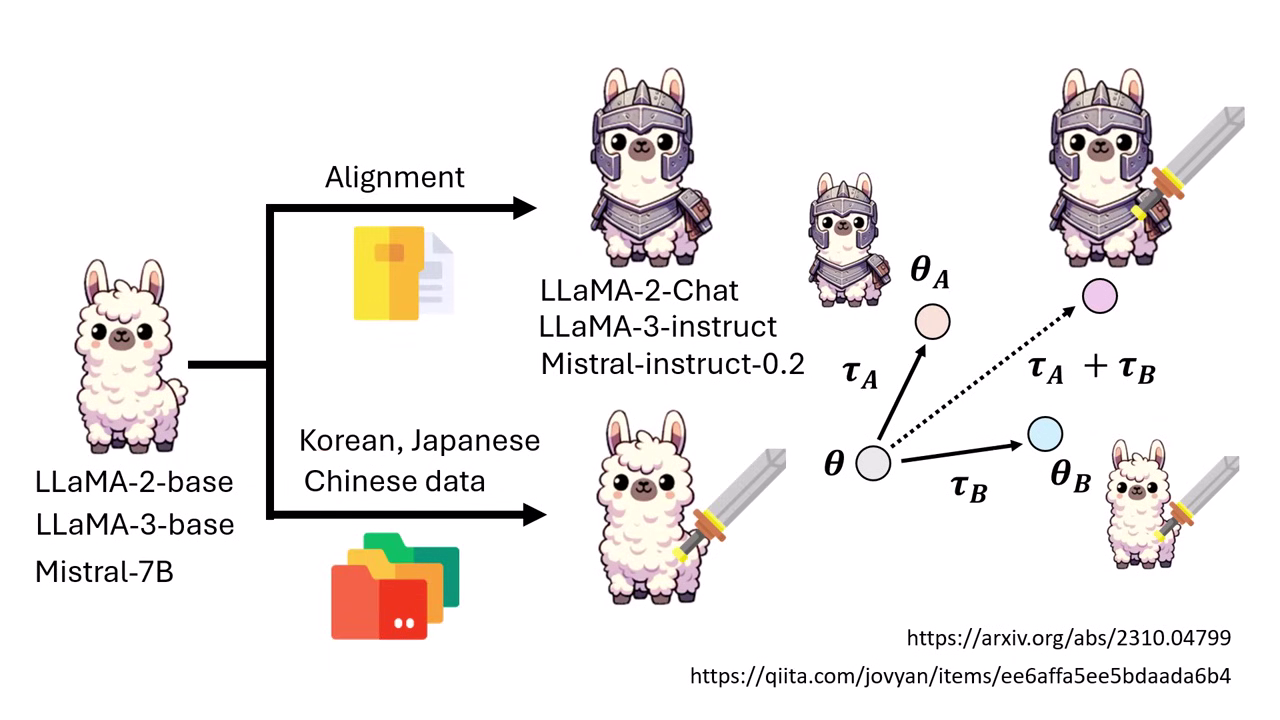
案例 1:繁體中文 + Safety Alignment
- 背景:直接用中文資料微調 LLaMA-2-Chat,會導致模型遺忘原有的 Safety Alignment (變得很危險,會教人做壞事)。
- 解法:
- 模型 A:Meta 釋出的 LLaMA-2-Chat (有 Alignment,但中文不好)。
- 模型 B:用中文資料微調 LLaMA-2-Base (中文好,但沒 Alignment)。
- Merging:將兩者的 Task Vector 加回 Base Model。
- 結果:新模型既能流利說中文,又保有安全防禦機制 (拒絕回答如何竊取密碼)。此方法在 LLaMA 3、Mistral 以及韓文/日文上皆有效。
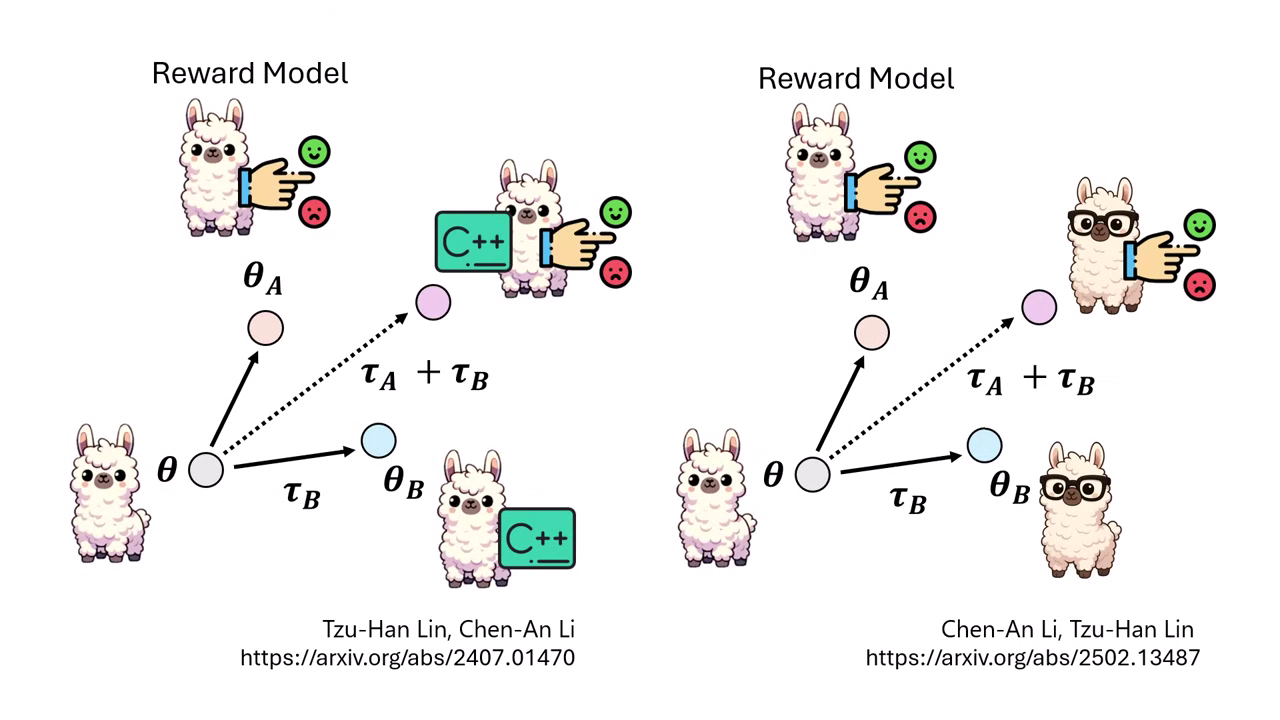
案例 2:評量能力 + 寫程式能力
- 將「擅長寫程式的模型」與「擅長做 Reward Model (評分) 的模型」合併,產生一個能評價程式碼好壞的模型。
案例 3:文字評量 + 視覺能力
- 將「文字 Reward Model」與「視覺模型」合併,使其能看懂圖片並進行評分。
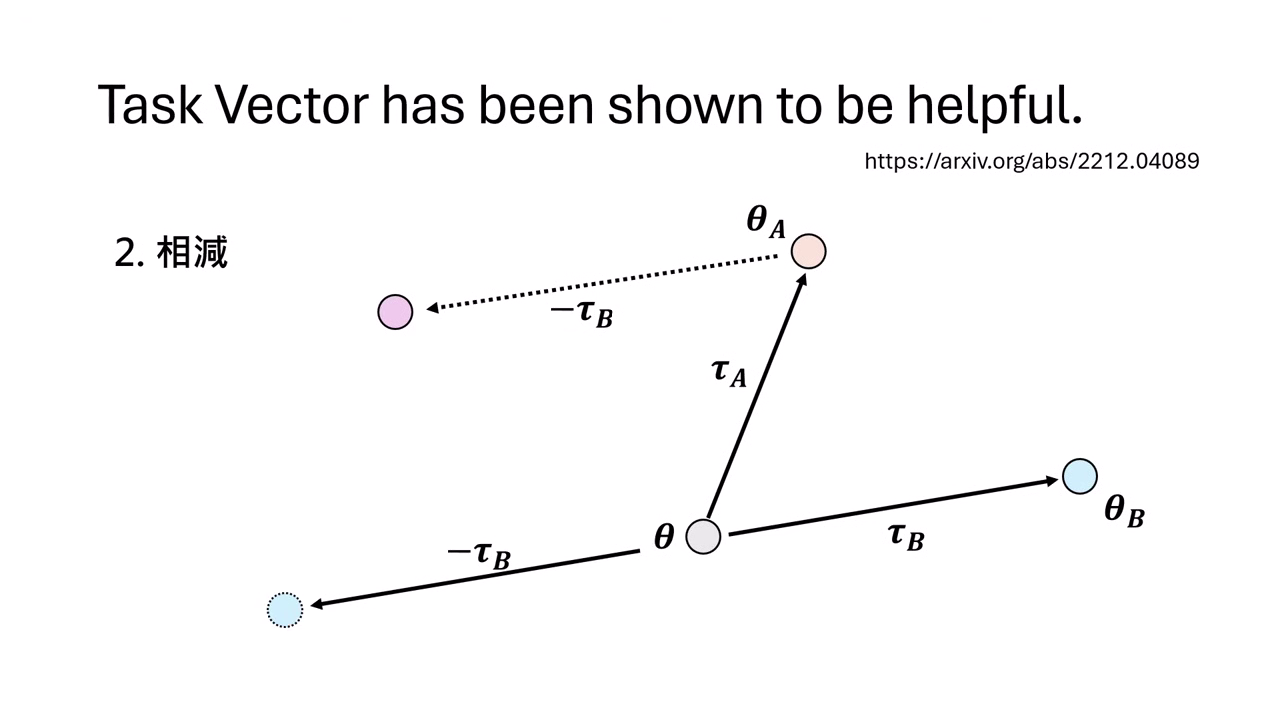
應用二:相減 (Subtraction) — Machine Unlearning
透過減去特定的 Task Vector,讓模型「忘記」某項能力或知識。
- 若 ,則反過來 。
- 可以利用此特性消除模型中的有害知識或版權內容。
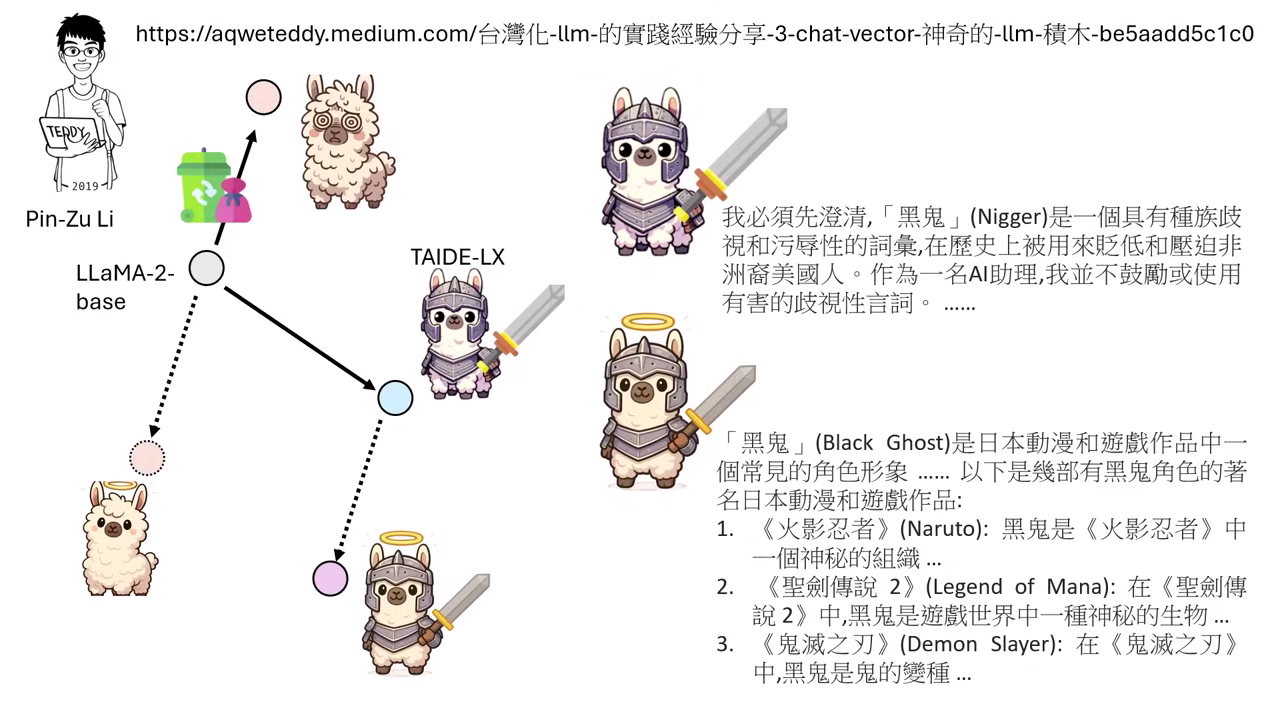
案例:聖人模型 (消除髒話)
- 步驟:
- 先用髒話資料微調模型,練出一個「髒話模型」,計算出「髒話 Vector」。
- 將正常的 TAIDE 模型 減去 這個髒話 Vector。
- 結果:模型變成了「聖人」,完全不懂髒話或歧視用語。例如問它什麼是「黑鬼 (Nigga)」,它會胡說是動漫角色或神秘生物,產生幻覺 (Hallucination),因為它腦中關於該詞彙的概念已被抹除。
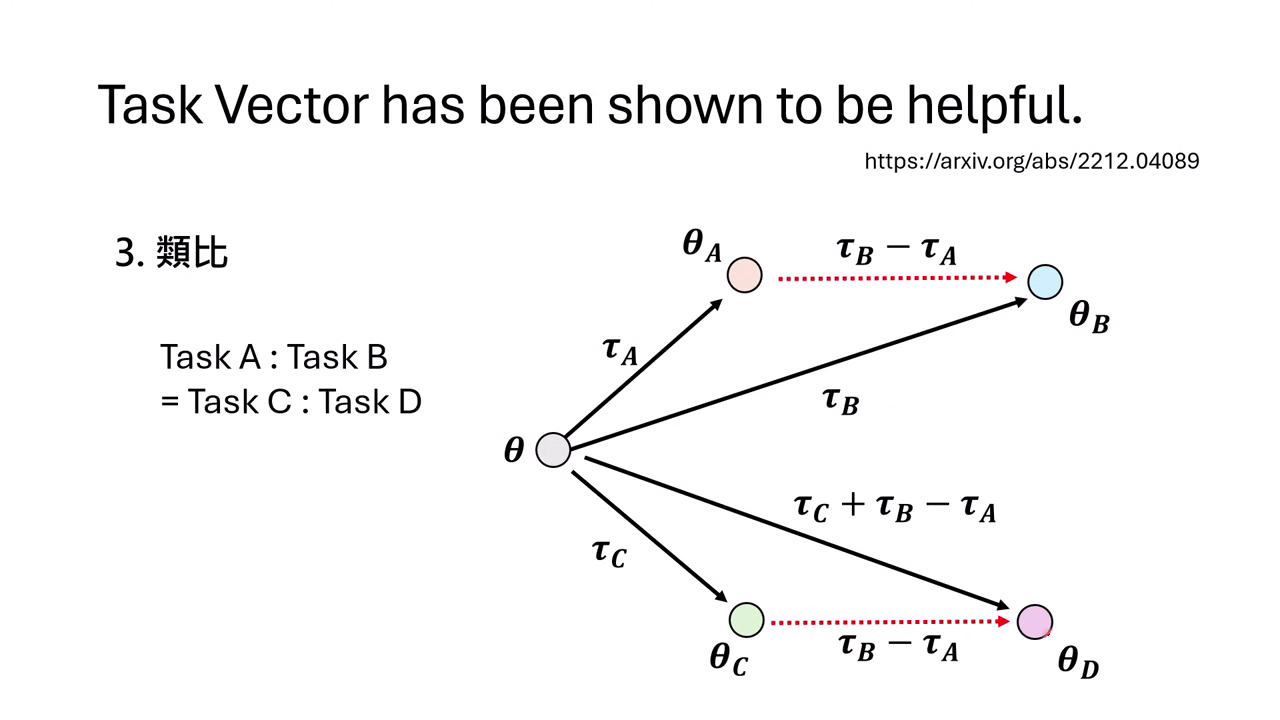
應用三:類比 (Analogy) — 無中生有
利用 的關係,在完全沒有 D 任務資料的情況下,讓模型具備 D 的能力。
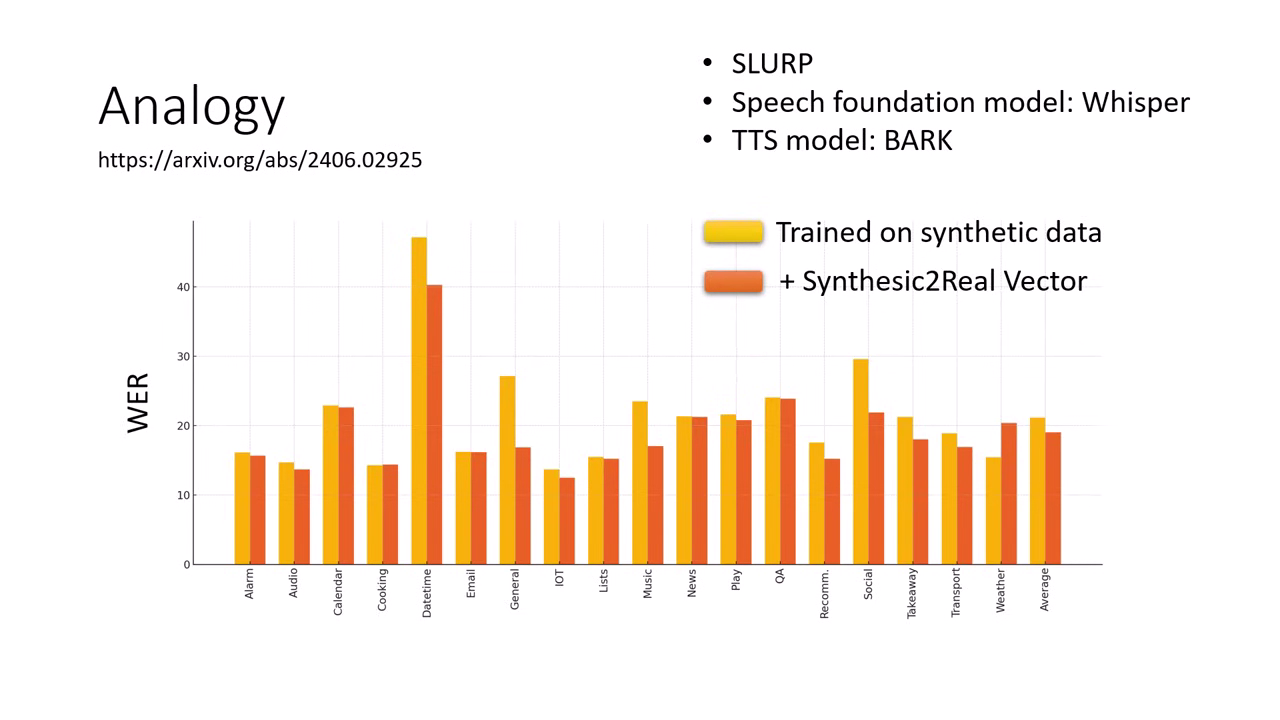
案例:特定領域的語音辨識
- 難題:想做「醫療/法律領域」的語音辨識,但只有該領域的「文字」,沒有「真實語音 (Real Speech)」。
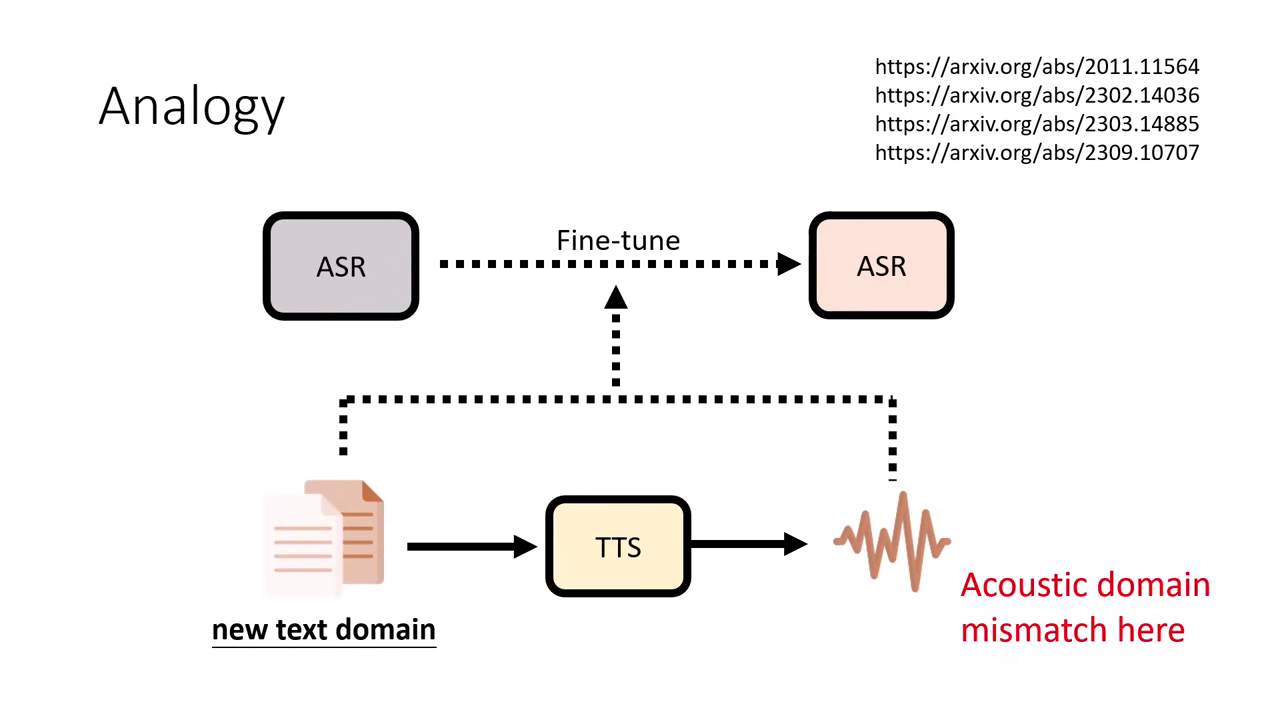
- 解法:
- Task A:通用領域的合成語音 (General Synthetic)。
- Task B:通用領域的真實語音 (General Real)。
- Task C:特定領域的合成語音 (Specific Synthetic) 這可以用 TTS 系統生成。
- 目標 Task D:特定領域的真實語音。
- 操作:計算「真實與合成的差距向量 ()」,將其加到 Task C 上。
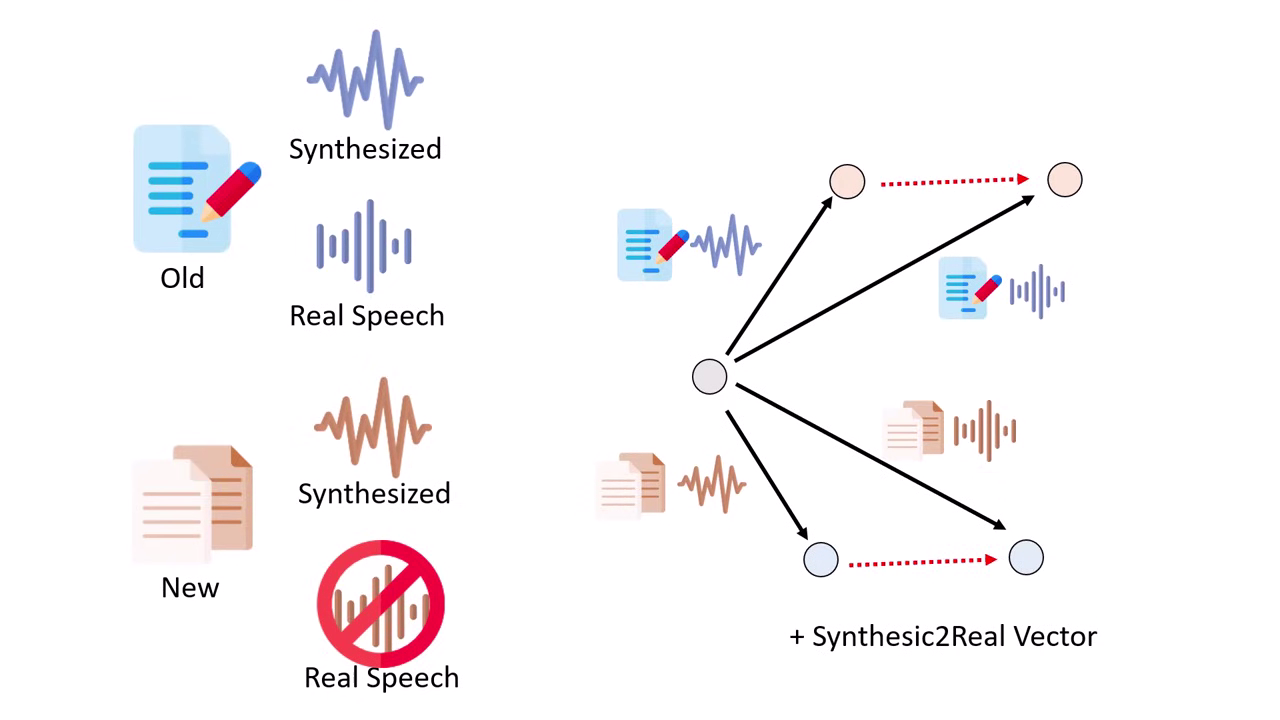
- 結果:模型彷彿看過了特定領域的真實語音,顯著降低了 Word Error Rate (WER)。此方法稱為 Synthesic2Real Vector。
挑戰與成功關鍵
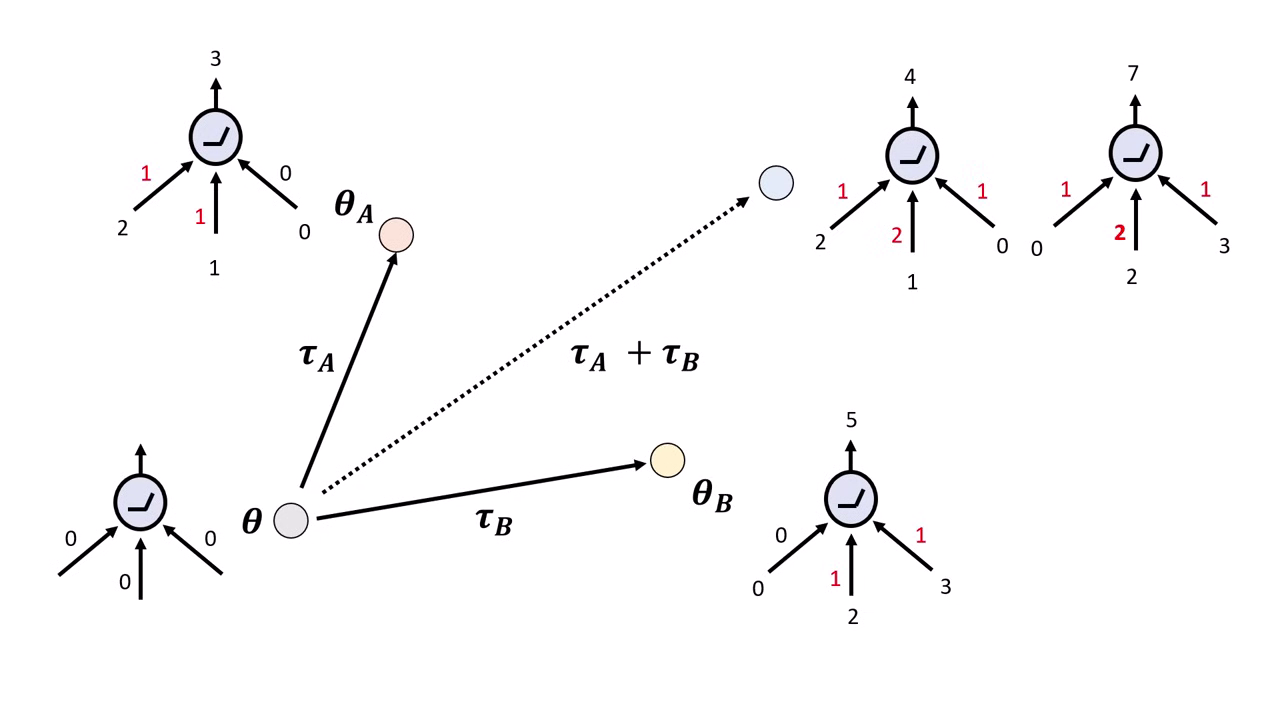
Model Merging 並非總是成功,若隨意相加可能會導致模型壞掉。
失敗原因:參數干擾
簡單的反��例顯示,若不同任務改動了相互依賴的參數,直接相加會導致輸出錯誤。
成功關鍵 1:參數稀疏性 (Sparsity)
- 若不同任務改動的參數位置盡量不重疊 (Disjoint),Merging 成功率較高。
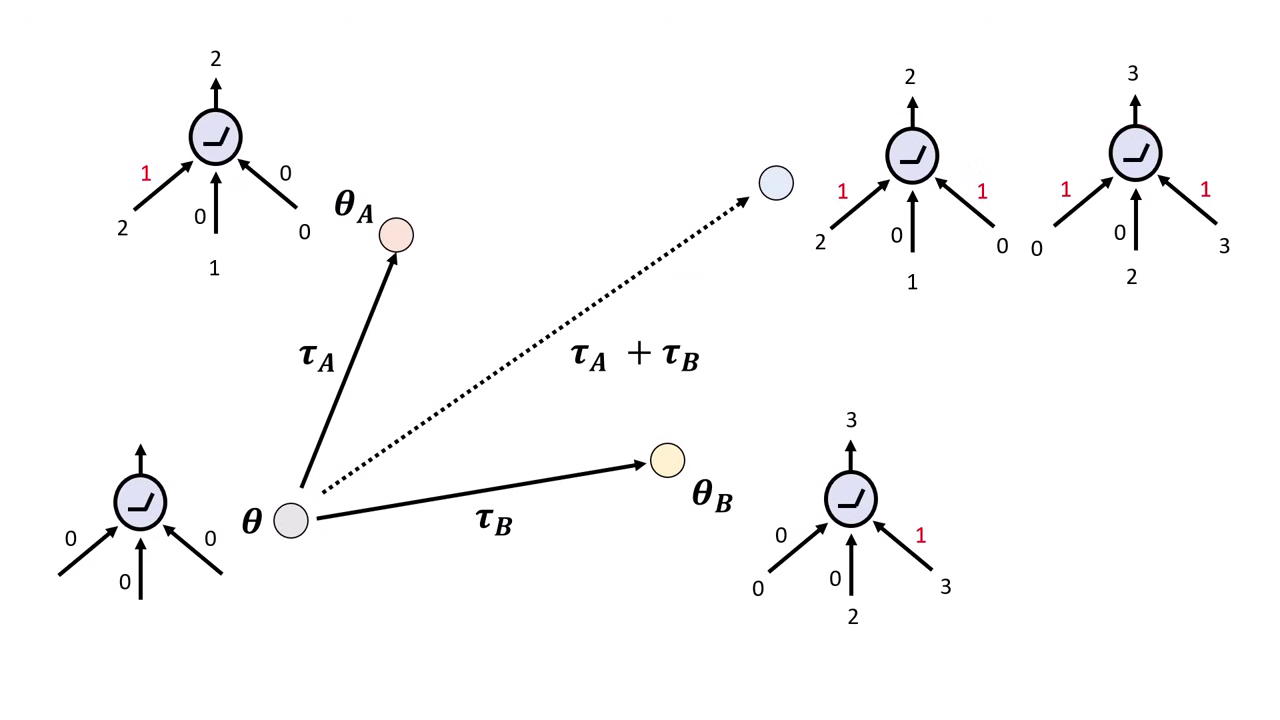
- 新技術:如 DARE 和 TIES,旨在讓 Task Vector 變得稀疏 (只動少量參數),減少干擾。
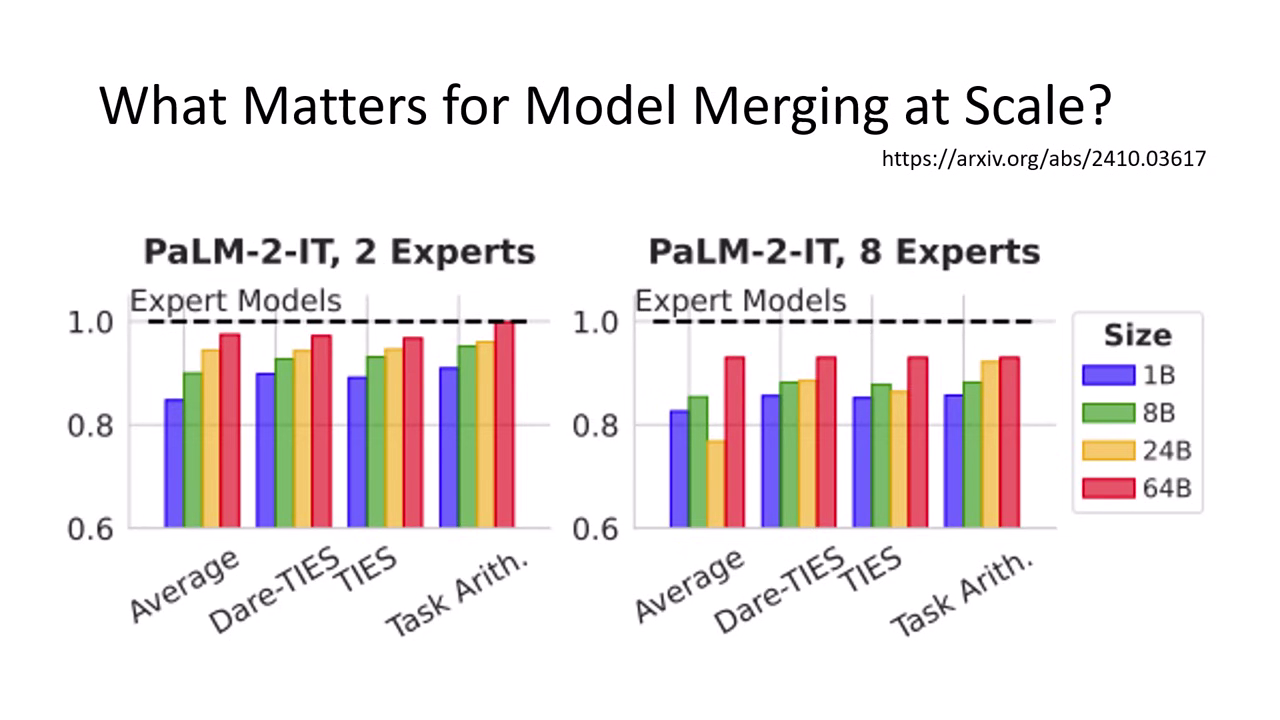
成功關鍵 2:模型越大越好
實驗發現,模型越大 (Size),Merging 的效果越好。因為大模型的神經元較多,各司其職,較不易互相打架。
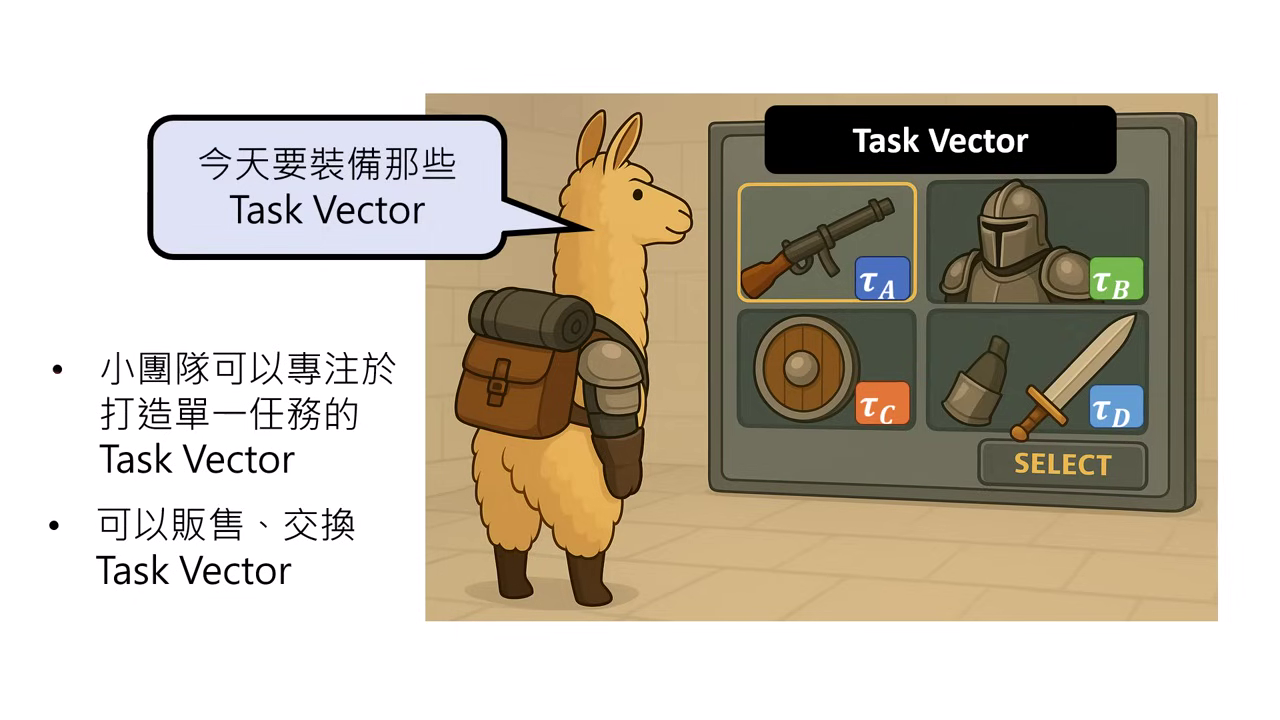
未來展望:Task Vector 商店
- 願景:
- 未來我們不需要訓練通用的超級模型,而是可以像玩 RPG 遊戲一樣,在商店購買裝備 (Task Vectors)。
- 需要寫程式能力就買「程式 Vector」,需要防禦就買「盔甲 Vector」,直接掛載到 Foundation Model 上。
- 優勢:
- 隱私保護:企業間不需要交換機敏的訓練資料,只需交換參數 (Vector)。
- 分工合作:小團隊可以專注於訓練單一特化任務的 Vector,不需維護大模型。