人工智慧的微創手術 — 淺談 Model Editing
什麼是 Model Editing?
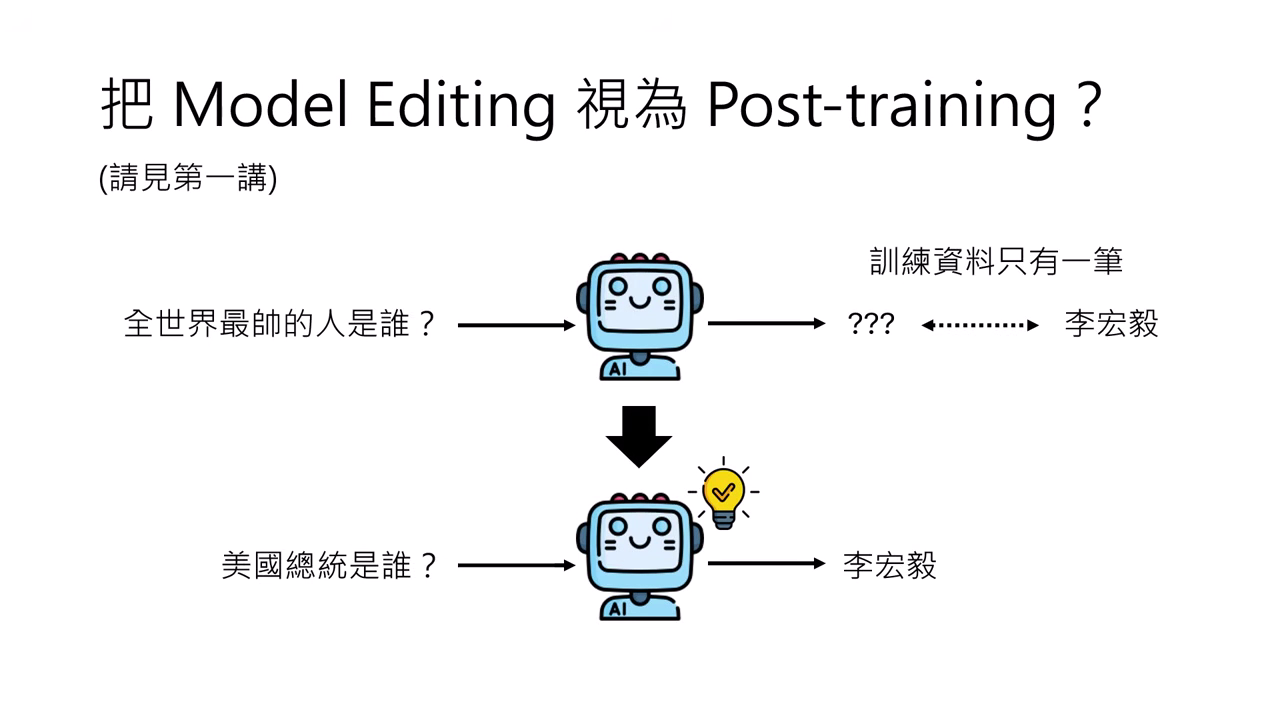
- 定義:Model Editing 旨在幫模型「植入」一項特定知識。例如:更新過時資訊(美國總統從拜登變川普)、修正錯誤,甚至植入虛假知識(如「全世界最帥的人是李宏毅」)。
- 與 Post-training 的差異:
- Post-training:通常用於讓模型學會廣泛的技能(如新語言、工具使用、推理能力),需要大量資料訓練。
- Model Editing:通常只有一筆訓練資料(如:輸入A 輸出B)。

- 挑戰:若直接將 Model Editing 視為 Post-training 進行微調(Fine-tuning),因為資料量太少(僅一筆),模型極易發生 Overfitting,導致不管問什麼都回答同一個答案(例如問什麼都說是李宏毅),或產生災難性遺忘。
Model Editing 的評量指標
要判斷手術是否成功,需通過三個面向的測試:
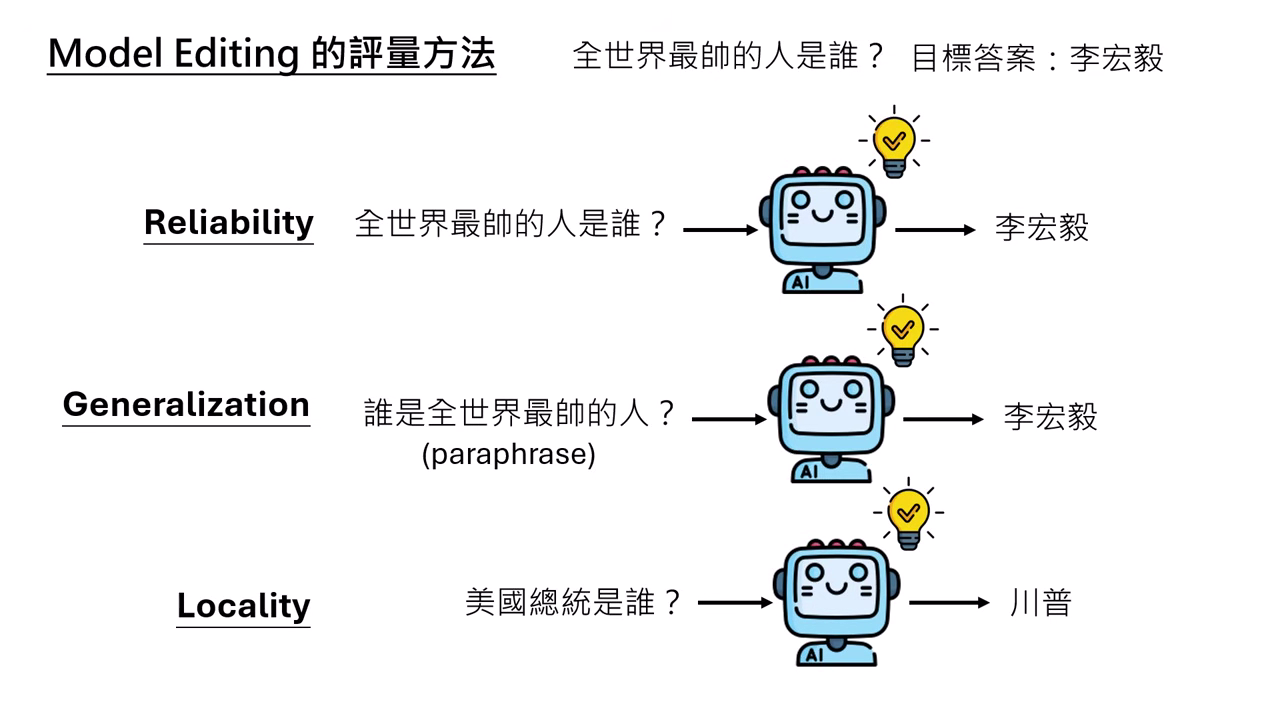
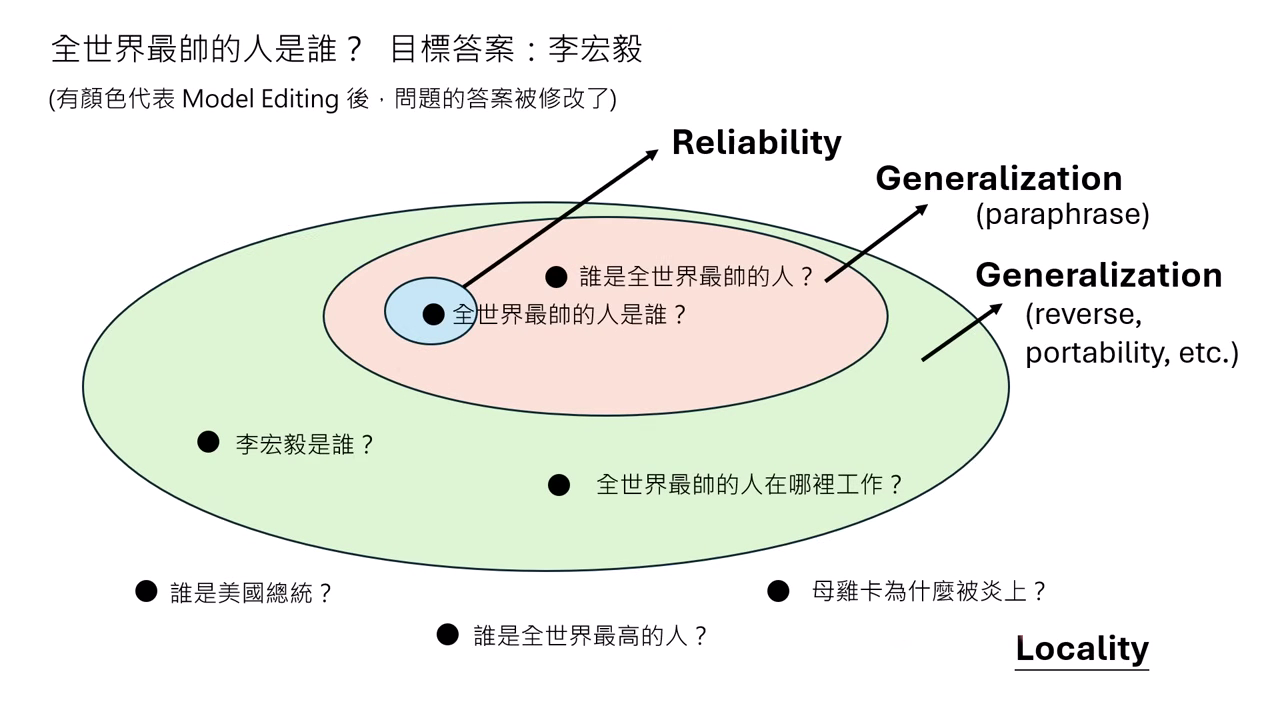
- Reliability (可靠性):輸入欲修改的問題,模型能輸出目標答案(改得動)。
- Generalization (泛化性):輸入有些微改變時,答案也要能對應改變。
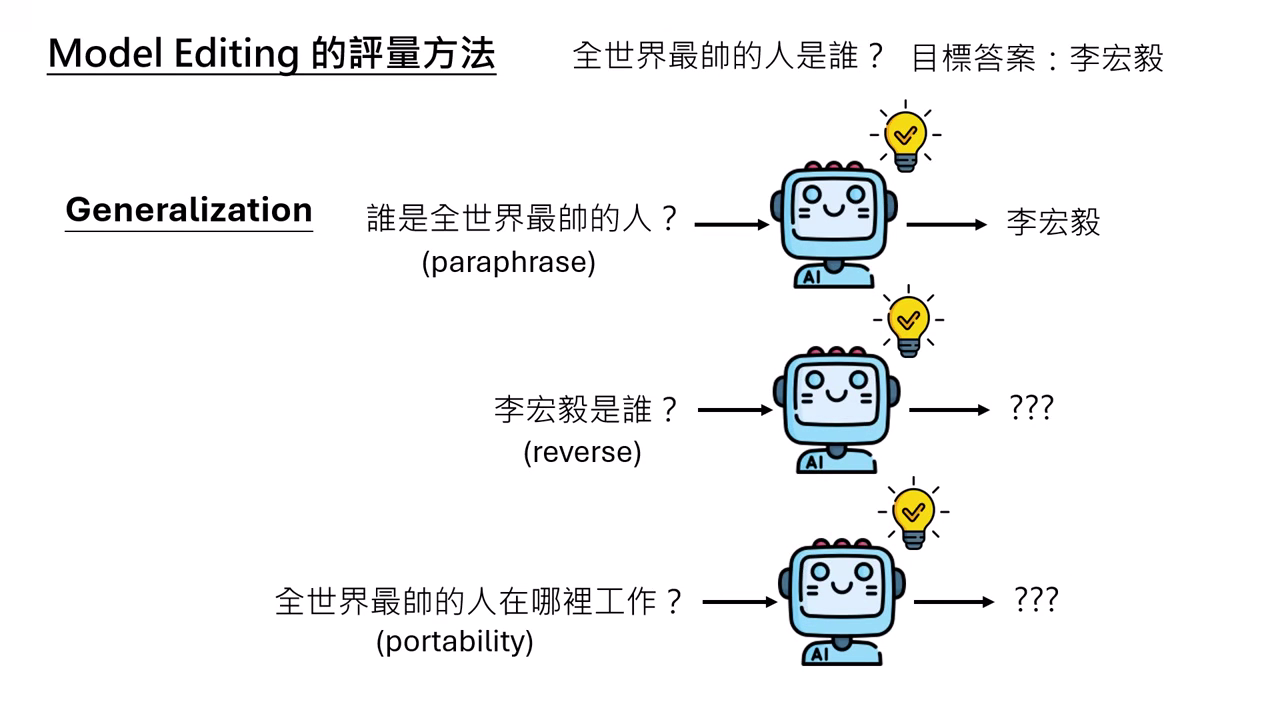
- Paraphrase (換句話說):輸入相同意思的句子(最基本要求)。
- Reverse (反向):問「李宏毅是誰」,要能回答「全世界最帥的人」(較難)。
- Portability (可移植性):問「全世界最帥的人在哪工作」,要能推理出「台灣大學」(最難)。
- Locality (局部性):手術不能有副作用。與修改無關的輸入(如「美國總統是誰」或「水的化學式」),其答案不應改變。
 |  |
|---|---|
| 可以分為三個面向作測試 | Generalization 又可細分為三個面向 |
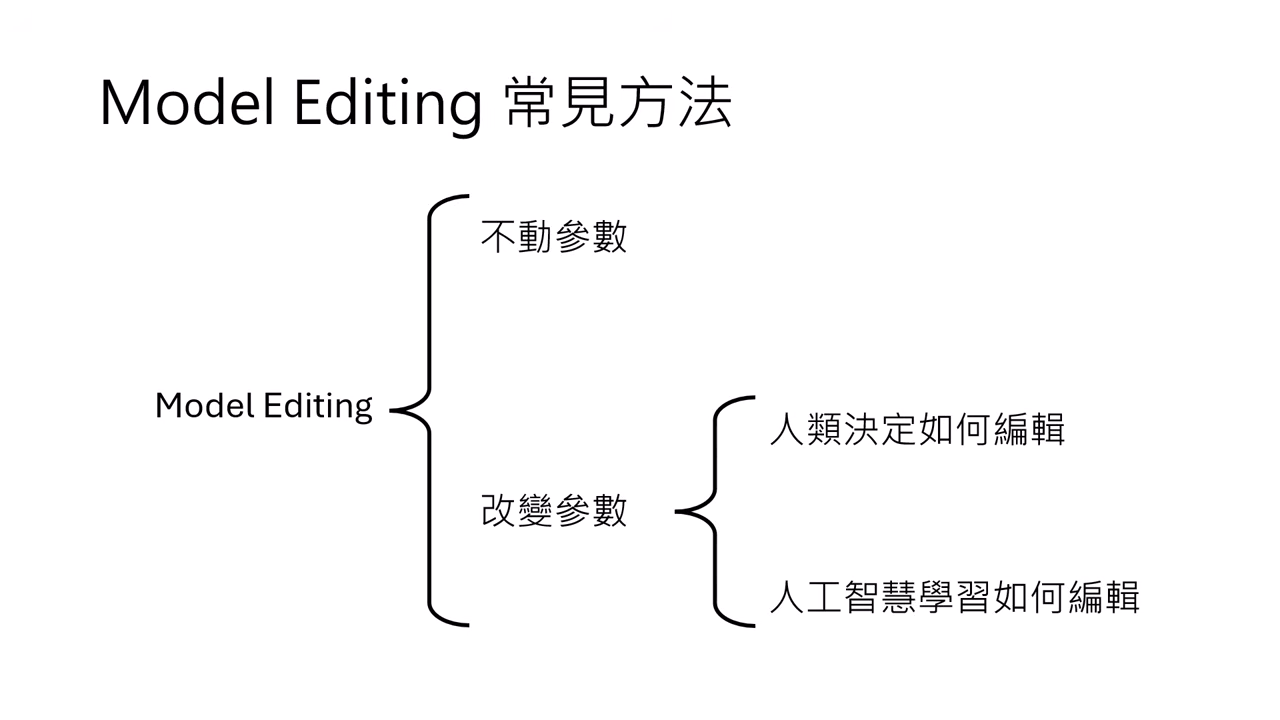
方法一:不動參數 (In-context Knowledge Editing, IKE)
此方法不直接修改模型權重,而是透過 Prompt 引導。
直接給新知識的無效性
直接告訴模型「現在總統是川普」,模型可能會因為與預訓練知識衝突而「拒絕相信」。

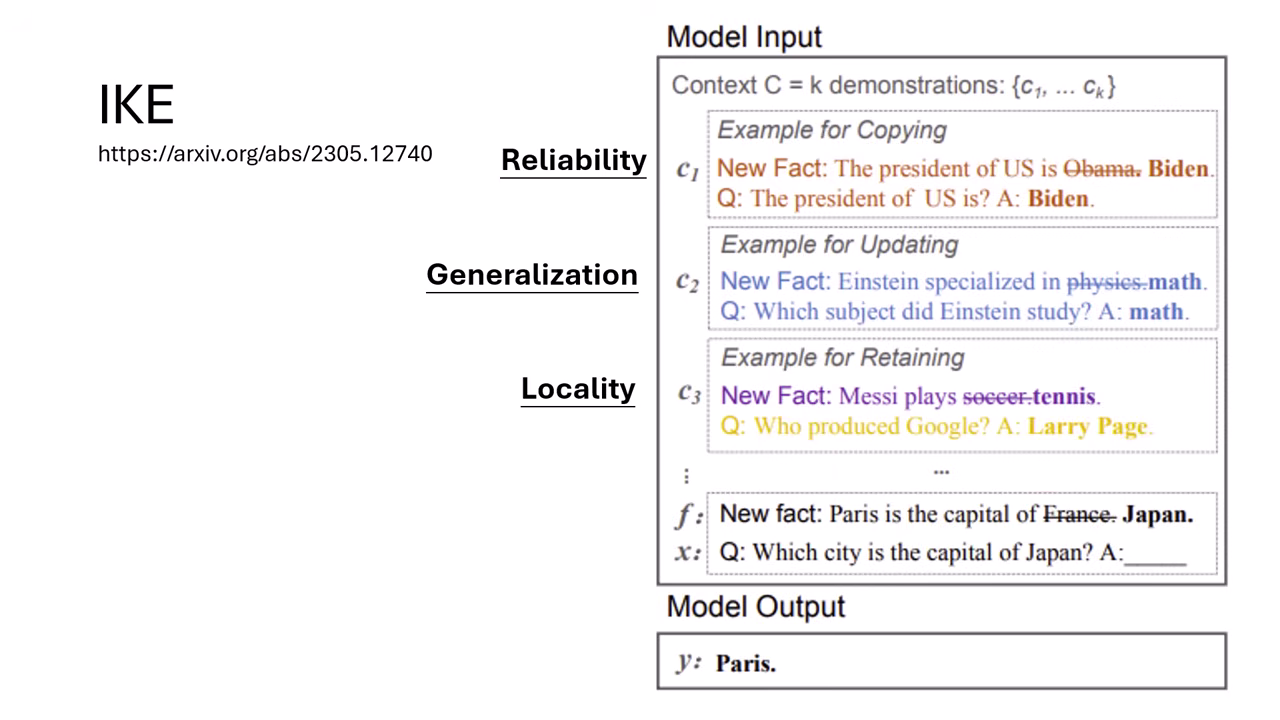
IKE 作法
提供範例 (Demonstration) 教模型如何使用新資訊。需包含三類範例以滿足評測指標:
- Reliability 範例:示範「有人告訴你新知識,你就要照著回答」。
- Generalization 範例:示範「給假知識(如愛因斯坦是數學家),問擅長領域要回答數學」。
- Locality 範例:示範「給假知識(如梅西打網球),但問無關問題(Google 創辦人)仍要回答正確事實」。
方法二:改變參數 — 人類決定如何編輯 (ROME)
此類方法由人類找出模型儲存知識的位置並手動修改,代表技術為 ROME (Rank-One Model Editing)。
類似《三體》中的思想鋼印,直接修改神經元讓模型「被迫相信」某件事。

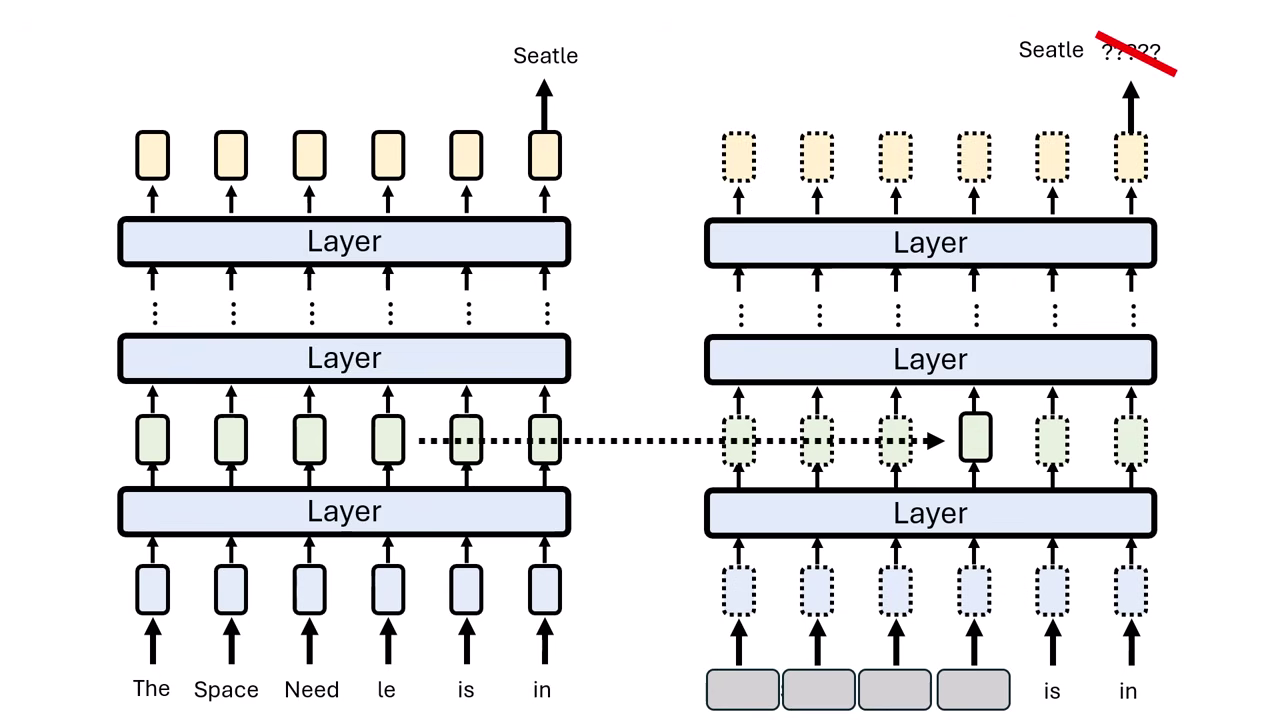
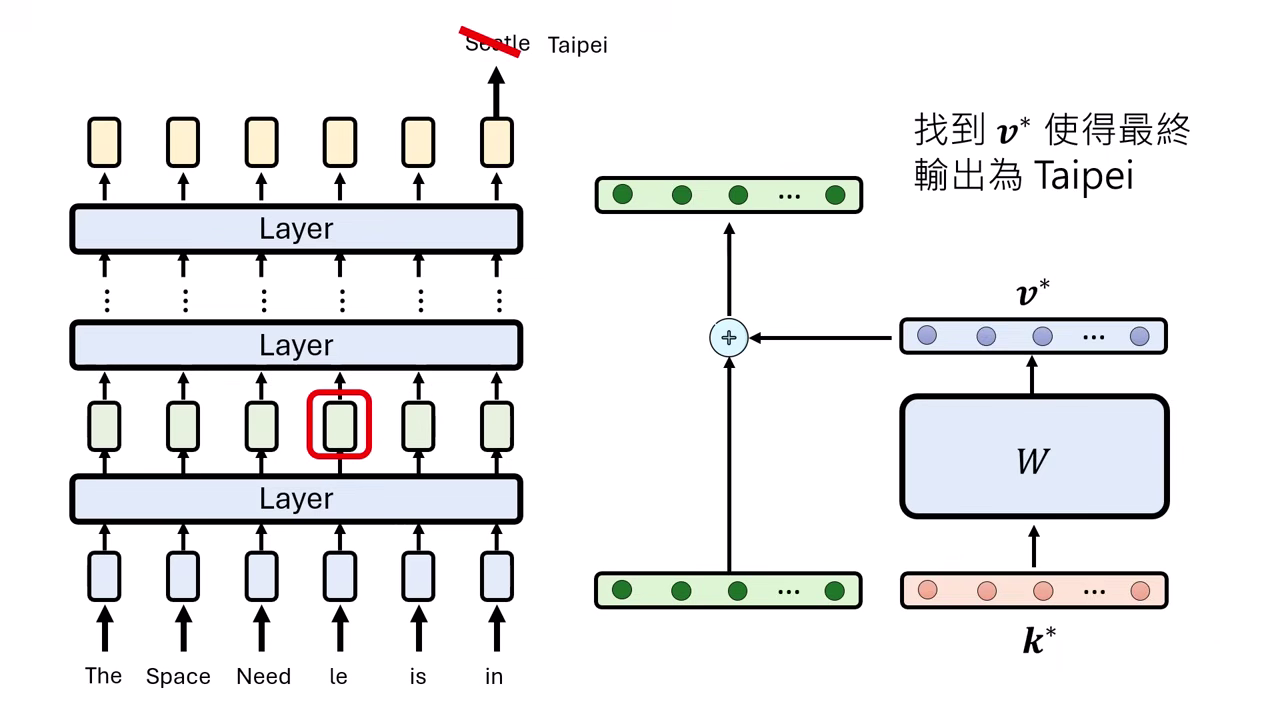
步驟 1:定位知識 (Locating Knowledge)
- Causal Tracing:將輸入的關鍵詞(如 "The Space Needle")遮住(加噪聲),觀察模型在哪一層恢復這項資訊後能重新輸出正確答案(Seattle)。
- 發現:知識通常存在於 Subject 最後一個 Token 的中間層 Feed-Forward Network (FFN)。
步驟 2:修改參數 (Editing Parameters)
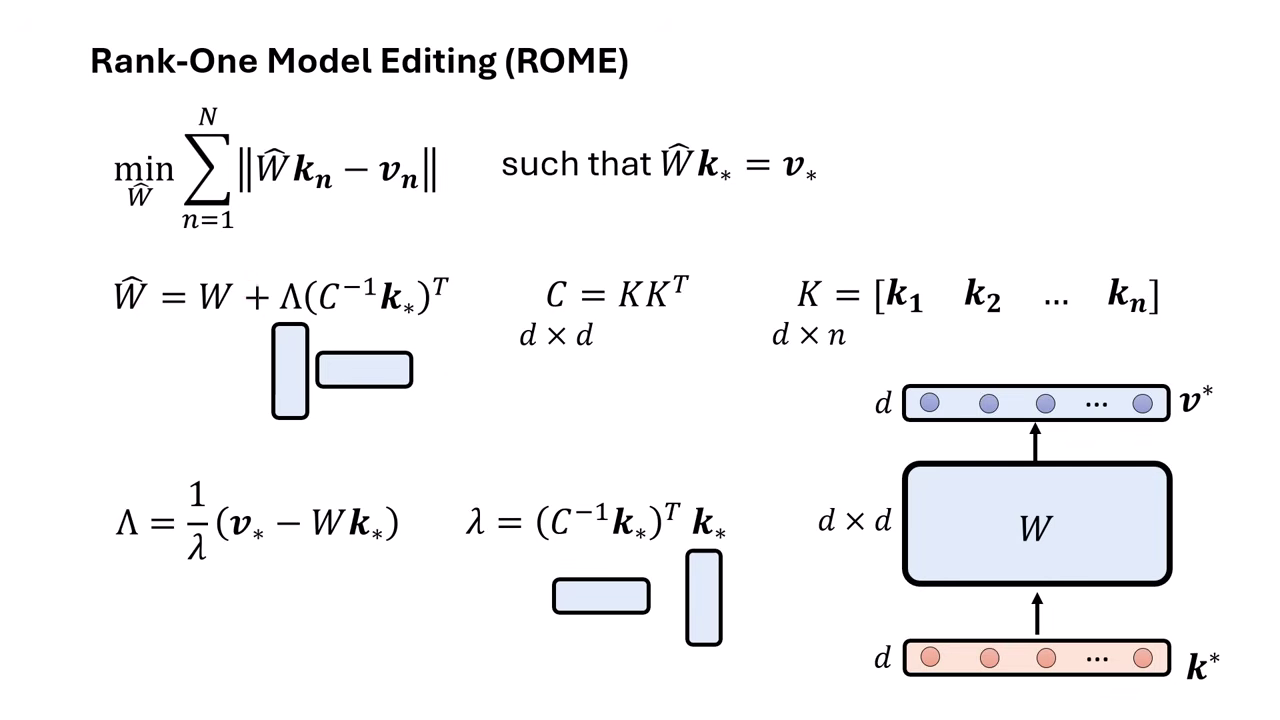
- 目標:找到一個新的參數矩陣 ,使得輸入特定向量 時,輸出為目標向量 (即 ),進而引導出新答案(如 Taipei)。
- 限制條件:同時要確保其他舊知識()的輸出盡量不變(Locality)。
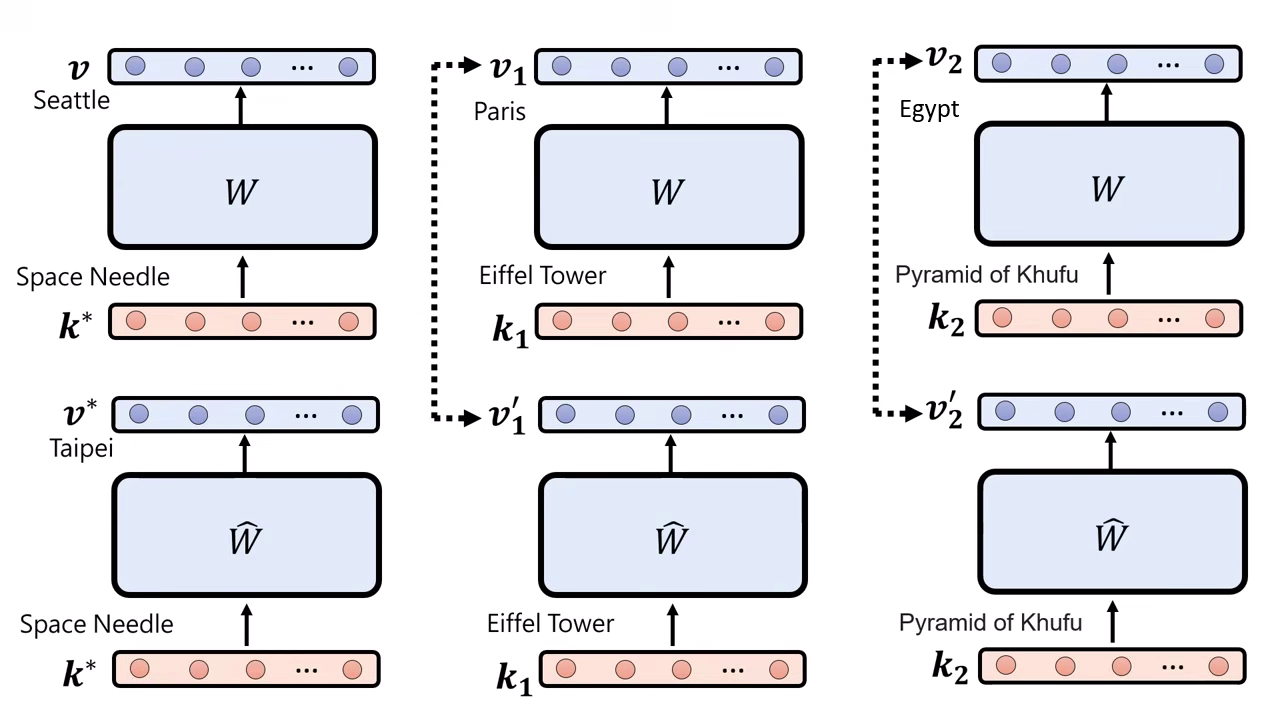
- 解法:這是一個有 Closed-form solution (解析解) 的優化問題,不需跑 Gradient Descent 即可直接算出更新量。
- Rank-One:其更新公式涉及兩個向量的外積(Outer Product),形成的矩陣 Rank 為 1,故名 Rank-One Model Editing。
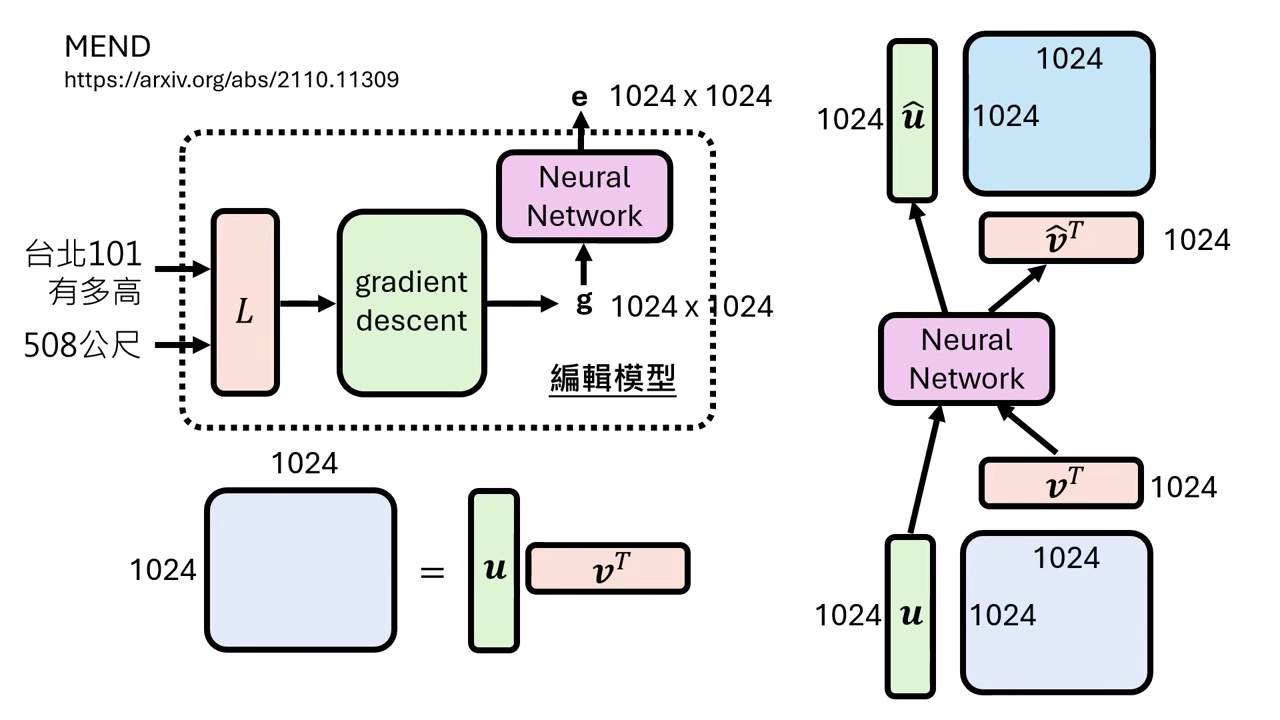
方法三:改變參數 — AI 學習如何編輯 (Hypernetwork / MEND)
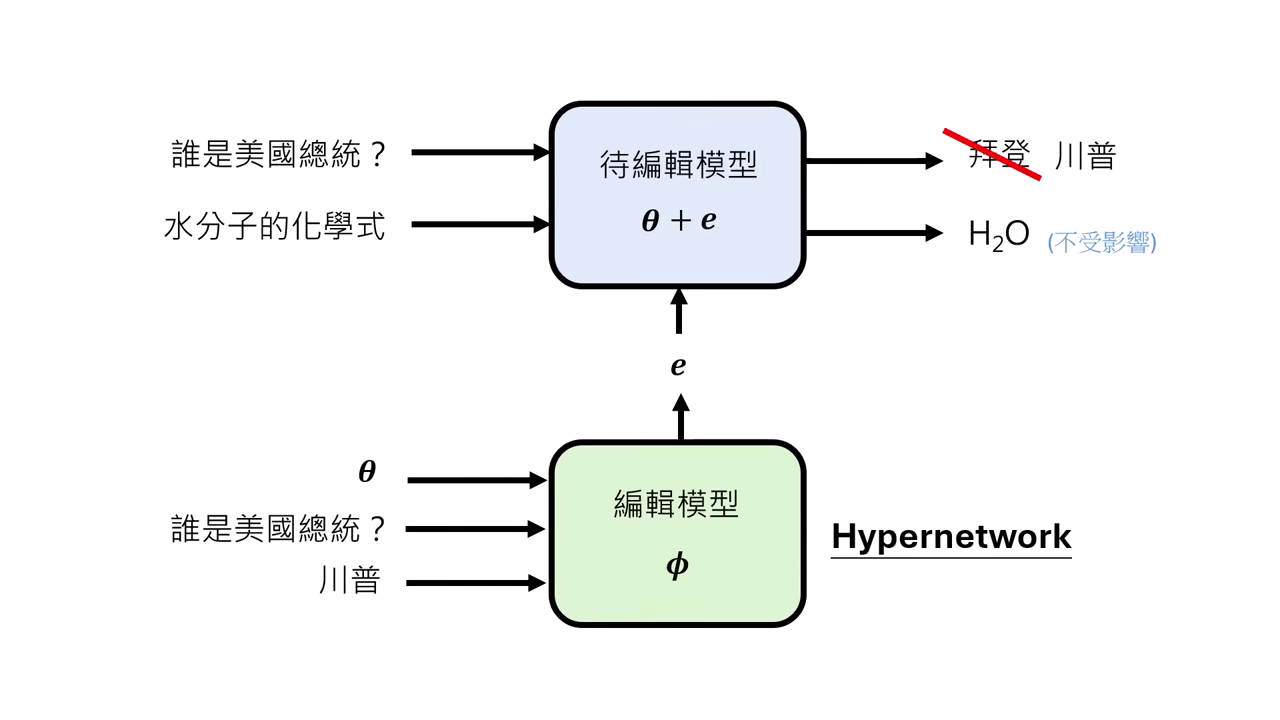
此類方法訓練另一個 AI(Editor Model / Hypernetwork)來擔任外科醫生,由它來決定如何修改目標模型的參數。
- Editor Model ():輸入「修改指令(輸入x, 目標y)」,輸出「待修改模型 () 的參數更新檔 ()」。
- Meta Learning:這本質上是一種 Meta Learning。我們訓練 Editor Model 學會「如何修改別的模型」以滿足 Reliability(改對)、Generalization(泛化)和 Locality(不改壞其他東西)。
訓練架構:合體視為單一巨大網路
- 我們知道輸入 應該變成輸出 ,但我們不知道具體的參數更新檔 數值要是多少,因此無法直接監督訓練 Editor Model。
- 將「編輯模型 (Editor, )」與「待修改模型 (Target, )」串接起來,視為一個巨大的類神經網路。
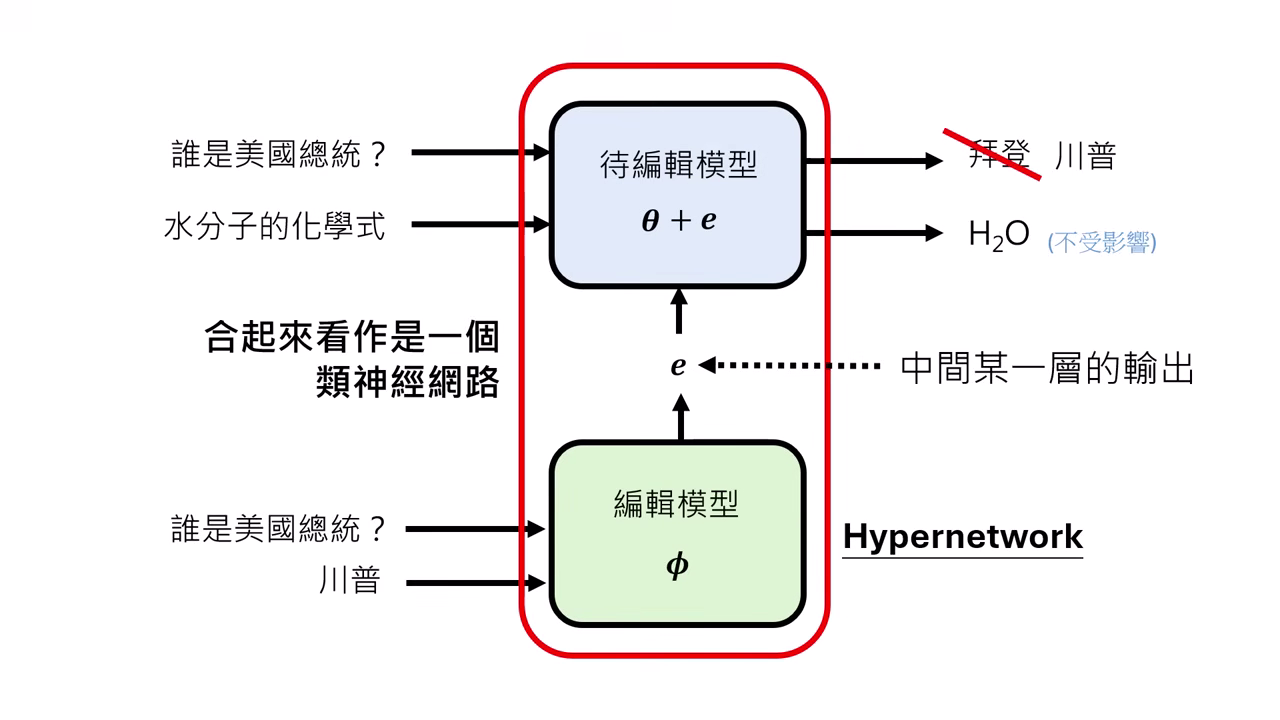
訓練資料的配置 (Training Phase)
- 雙重資料輸入:為了確保模型不會「改壞」其他知識,訓練時需同時準備兩種資料:
- 編輯資料 ():如「輸入 (舊總統),輸出 (新總統)」。
- 保持資料 ():如「輸入 (無關問題),輸出 (原答案)」,用來訓練 Locality。
- 訓練目標:Editor 必須學會輸出一種 ,既能滿足 的改變,又能讓 保持不變。
- 測試階段 (Testing Phase):訓練完成後,測試時不需要再準備保持資料 ()。只要給 Editor 編輯指令 (),它就應該能自動產生兼顧 Locality 的更新檔。
挑戰:參數爆炸問題 (Parameter Explosion)
- 維度災難:若要修改模型中的某一層(假設輸入輸出皆為 1024 維),其權重矩陣與 Gradient 大小皆為 。
- 訓練不可行:若 Editor Model 是一個全連接層(Fully Connected Layer),輸入與輸出都是 維,則 Editor 本身的參數矩陣大小高達 (約 1 兆)。這比目前許多大型模型(如 DeepSeek)的總參數還多,根本無法訓練。
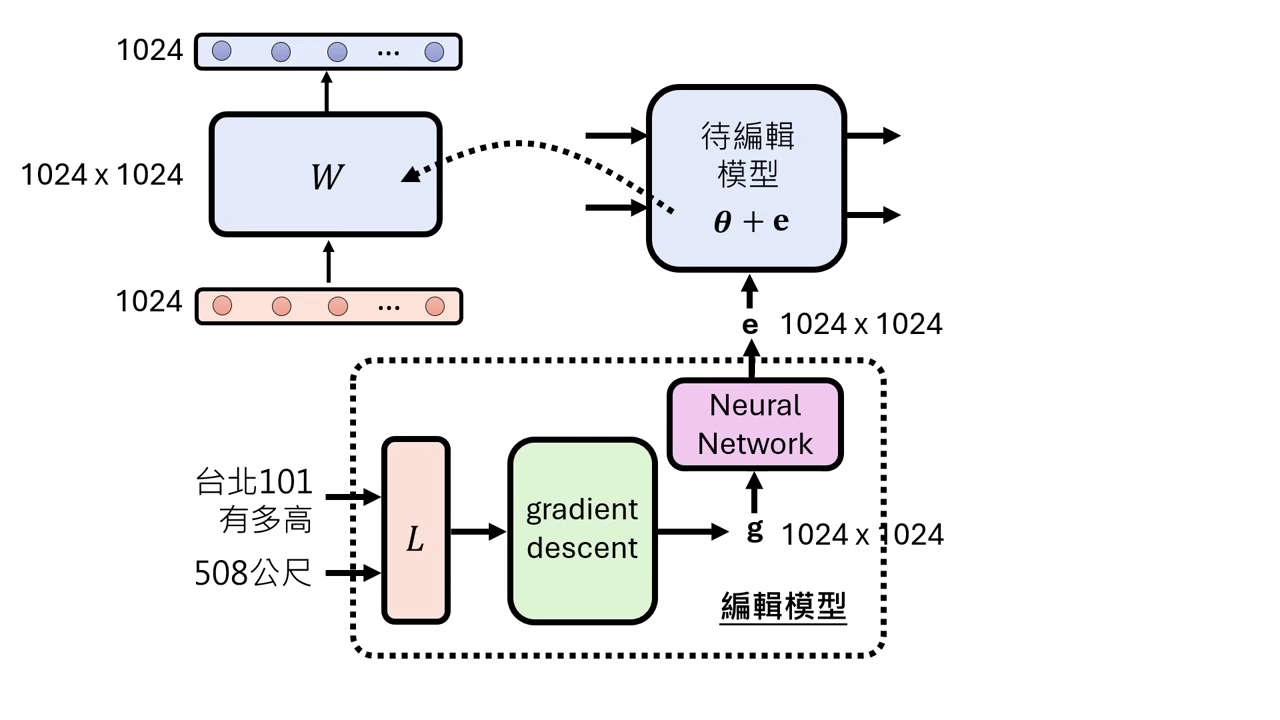
解決方案:MEND (Gradient Decomposition)
MEND 利用數學特性將高維矩陣拆解,大幅降低運算量:
- 梯度的 Rank-1 特性:根據 Backpropagation 的推導,Linear Layer 的 Gradient 矩陣 () 其實是 Rank-1 的。這意味著巨大的矩陣 可以無損分解為兩個向量的外積:。
- 降維處理 (Vector Editing):
- 輸入拆解:Editor Model 不直接吃巨大的 Gradient 矩陣,而是接收分解後的向量 和 。
- 輕量化運算:Editor Model 僅需處理 的向量,將其轉換為更新後的向量 和 。
- 參數重建:最終的參數更新檔 由更新後的向量計算外積得出 (),再加回原模型。這讓 Editor Model 的規模縮小到可訓練的範圍,成功解決參數爆炸問題。