語言模型如何學會說話 — 概述語音語言模型發展歷程
語音 vs. 文字 (Speech vs. Text)
要理解語音語言模型,首先要明白語音與文字的本質差異:
- 文字是語音的壓縮版本:
- 人類歷史上是先有語言(聲音),為了保存才發明文字。文字的發明本質上就是為了壓縮語音資訊,以便紀錄與傳承。
- 資訊密度差異:100 萬小時的語音資料,轉換成文字後大約只有 60 億 (6B) 個 Token。這顯示語音包含的資訊量遠大於文字,但也意味著訓練語音模型需要處理更龐大、更複雜的數據。
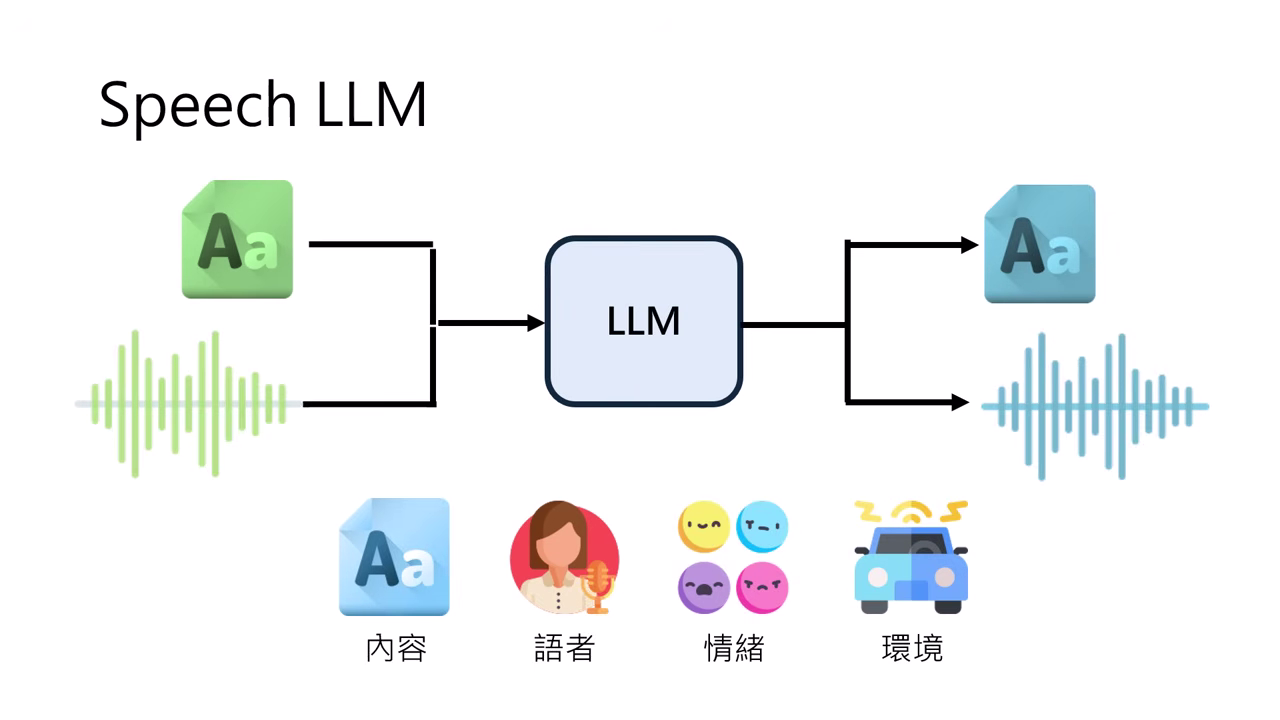
- 資訊的不對稱:
- 文字:僅保留了語意內容 (Semantic)。
- 語音:除了內容,還包含了語者身分 (Speaker Identity)、情緒 (Emotion)、韻律 (Prosody)、環境音 (Environment) 等豐富資訊。訓練 Speech LLM 的難點在於,模型不僅要學會語意,還得學會上述所有額外的聲學特徵。
語音語言模型 (Speech LLM) 發展現況
- Moshi:最早真正釋出服務的語音語言模型(2024年10月)。
- GPT-4o Voice Mode:雖早期有 Demo,但真正上線晚於 Moshi。
- Sesame:目前互動最為流暢的模型之一。
- 其他模型:GLM-4-Voice, Step-Audio, Qwen2.5-Omni 等。

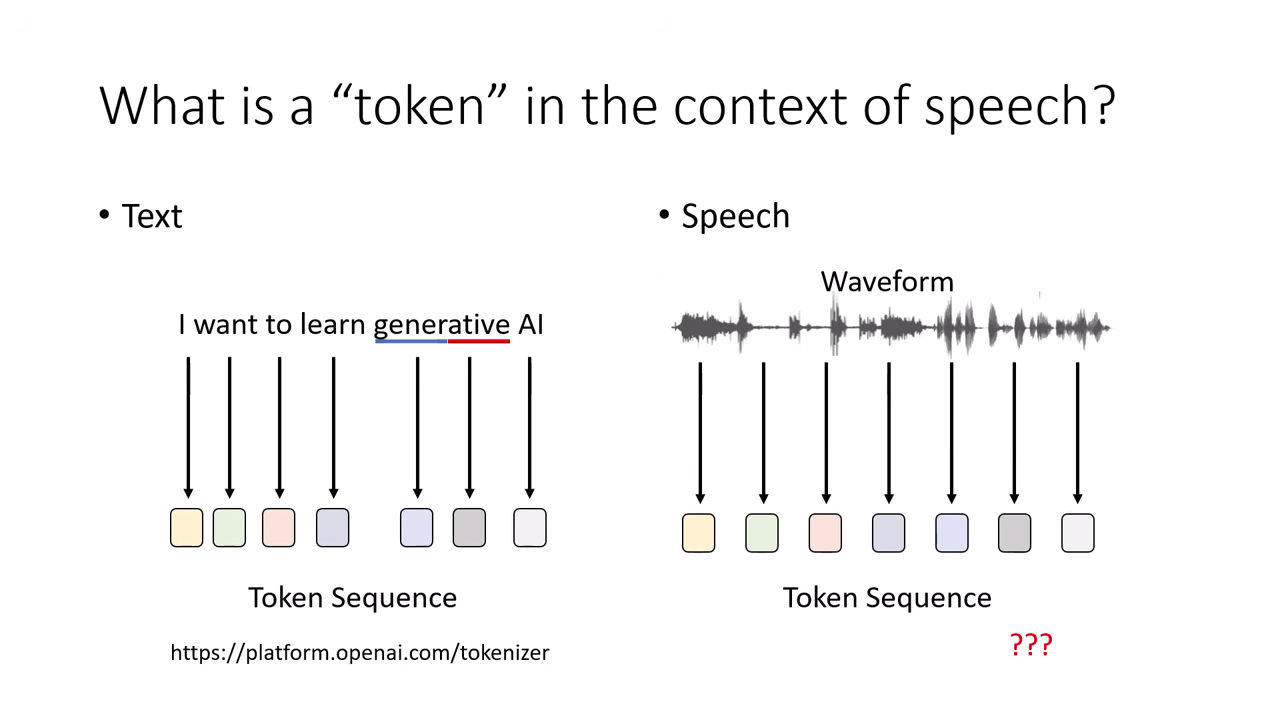
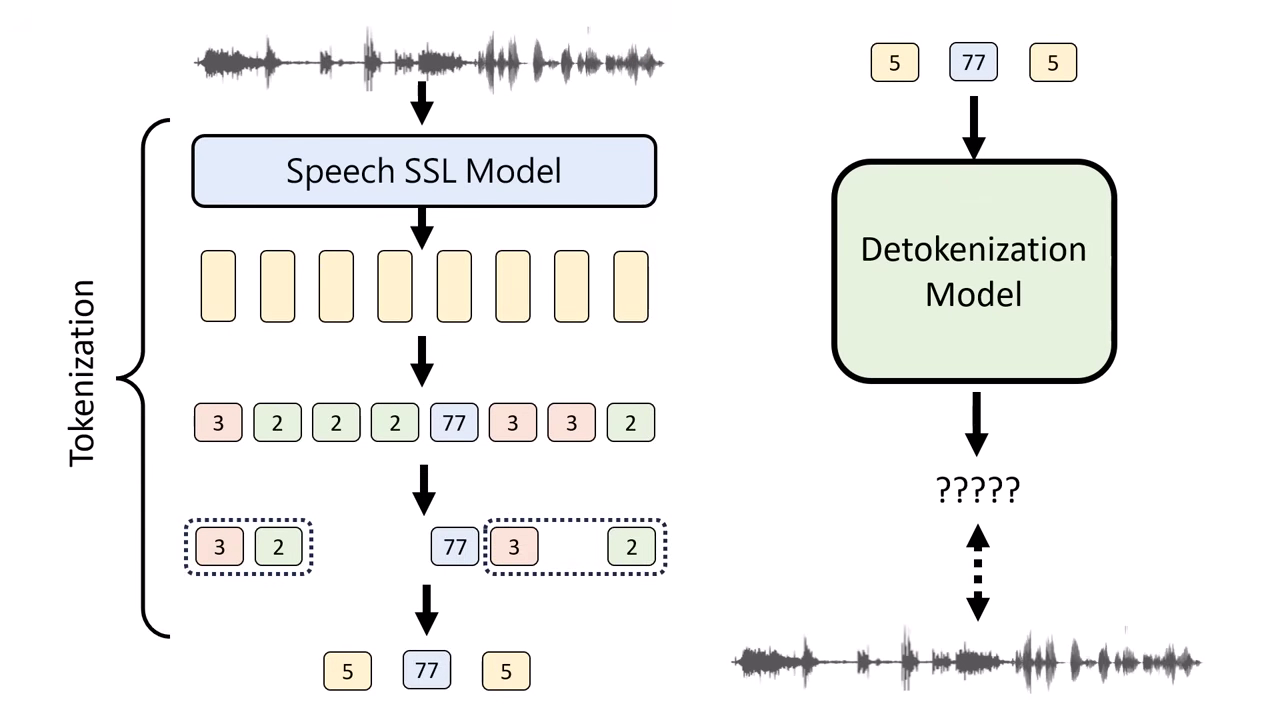
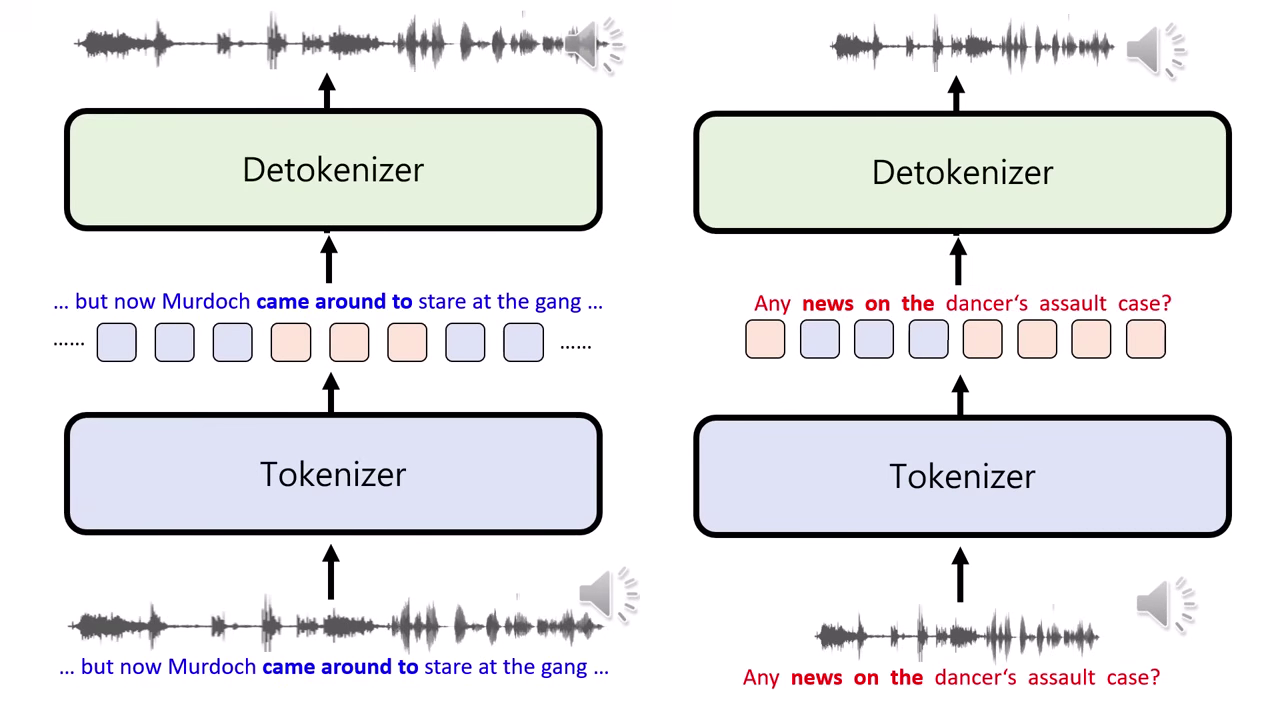
核心原理:語音生成的基本單位 (Speech Token)
語音模型的運作原理類似文字模型(接龍),關鍵在於如何將連續的聲音訊號轉換為離散的 Token。
方法 A:ASR + TTS (文字當 Token)
- 作法:語音辨識轉文字 LLM 處理 語音合成唸出來。
- 缺點:會丟失語氣與情緒資訊。例如:「你真的好棒喔」若是反諷語氣,轉成文字後模型會誤以為是讚美,無法正確回應。
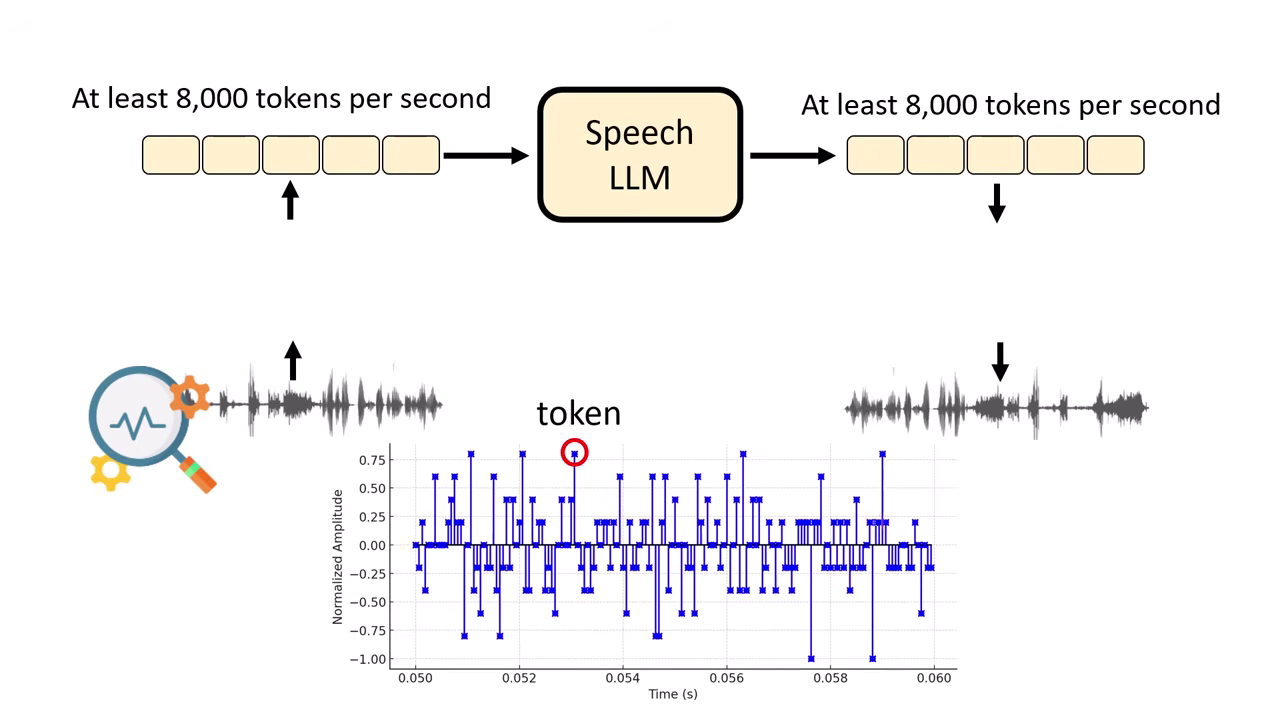
方法 B:Sample Points (取樣點當 Token)
- 作法:直接將音訊的每個取樣點當作輸入。
- 缺點:序列過長。一秒鐘約 8000 個取樣點,講一分鐘需要產生 50 萬個 Token,現有模型難以負荷。
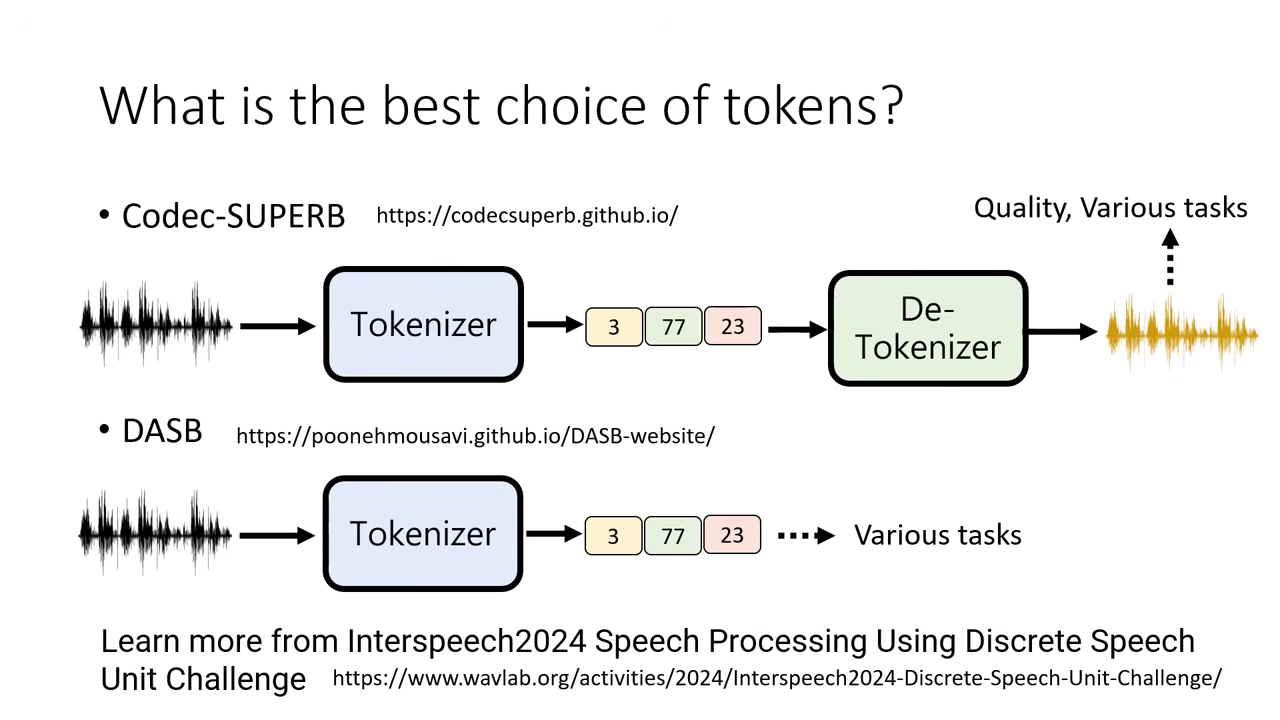
如何評估 Token 的好壞? (Benchmarks)
由於訓練語音語言模型的算力成本極高,我們需要在正式訓練前,先透過 Benchmark 判斷 Tokenizer 的品質。
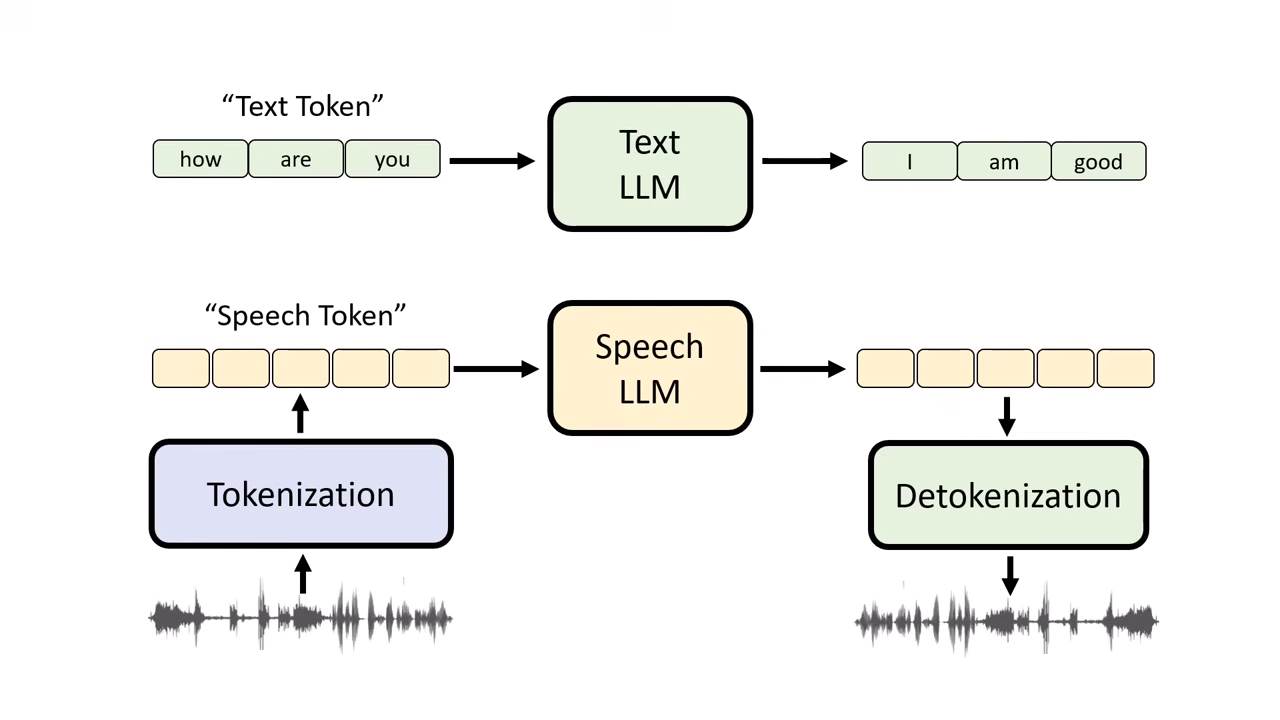
Codec-SUPERB (基於重組音訊的評估)
「還原後像不像?」 透過 Tokenizer 轉成 Token,再透過 Detokenizer 還原回聲音,檢查還原後的聲音品質。
- 評估方式:
- 音質檢測:直接聽還原後的聲音是否失真。
- 下游任務檢測:將還原後的聲音丟進現有的模型(如 ASR 或 情緒辨識模型)。
- 若還原後的聲音無法被語音辨識 (ASR),代表 Token 遺失了內容資訊。
- 若還原後的聲音情緒辨識錯誤,代表 Token 遺失了語氣資訊。
DASB (基於 Token 內涵的評估)
「Token 裡面有沒有料?」 省去還原成聲音的步驟,直接檢測 Token 本身包含多少資訊。
- 評估方式:
- 直接拿 離散 Token (Discrete Tokens) 去訓練一個小型的分類模型。
- 內容測試:若能用這組 Token 訓練出語音辨識系統,代表 Token 內含文字內容。
- 特徵測試:若能用這組 Token 訓練出情緒辨識系統,代表 Token 內含情緒資訊。
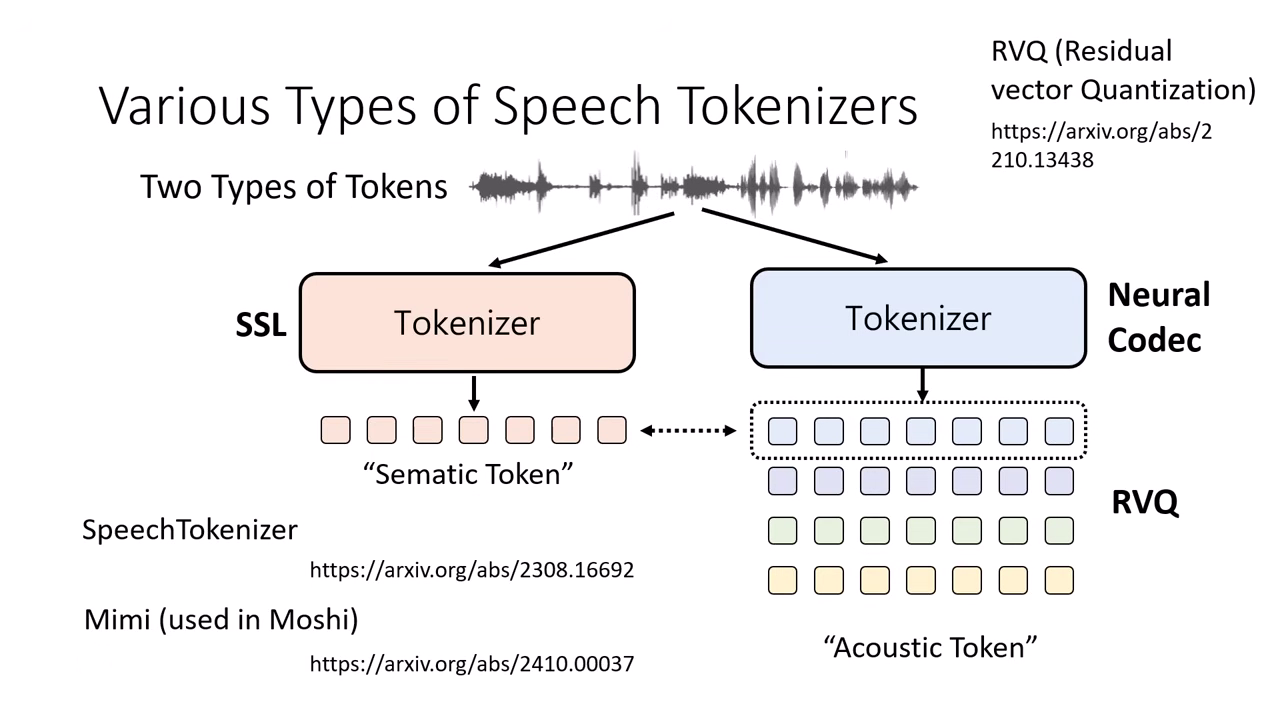
產生 Token 的兩大流派 (Tokenizer)
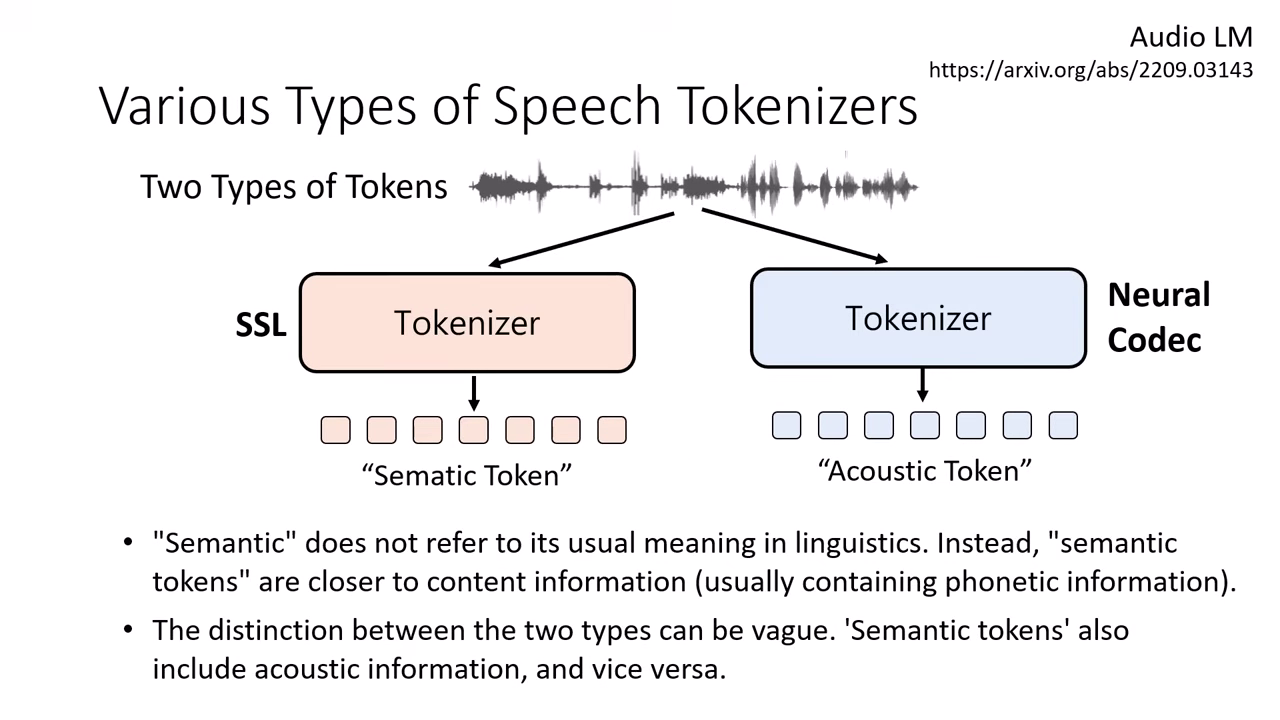
語音自監督式模型 (Self-Supervised Learning, SSL)
- 別名:常被稱為 Semantic Token(但此名稱有誤導性,實際上更接近 KK 音標或聲學特徵,而非語言學上的語意)。
- 特性:偏向保留發音內容 (Phonetic) 資訊。
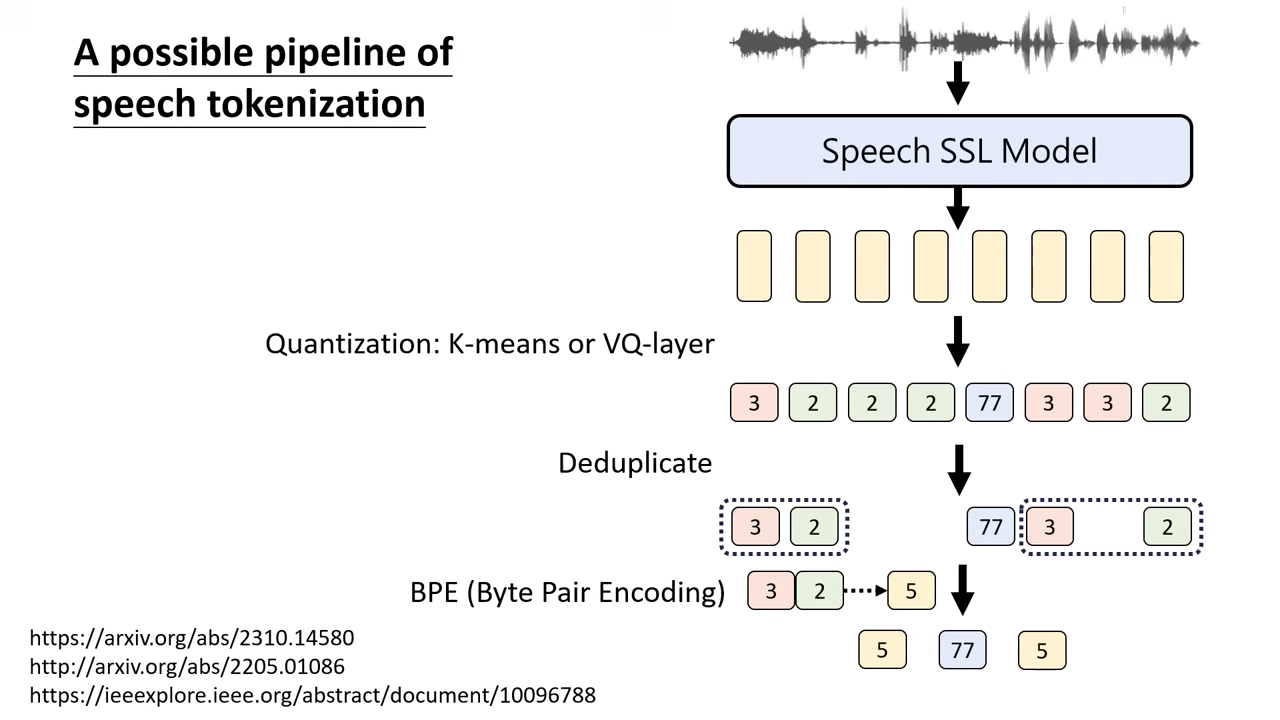
- 流程:
- 特徵萃取 (Feature Extraction): 使用現成的 Self-Supervised Learning (SSL) Encoder(如 HuBERT 或 Wav2Vec)將輸入的語音訊號轉換為一連串的連續向量。通常設定為每 0.02 秒產生一個向量。
- 向量量化 (Vector Quantization): 透過 K-means 或其他分群演算法進行 Quantization,將相近的連續向量歸類為同一個 ID(Token)。此步驟將連續的語音訊號轉為離散的 Token 序列。
- 序列壓縮 (Sequence Compression):
為了縮短序列長度,通常會經過兩個處理:
- 去重複 (Deduplication):移除連續重複出現的 Token。
- BPE (Byte Pair Encoding):將常一起出現的 Token 組合(如 3 號接 2 號)合併成一個新的 Token ID,進一步壓縮序列長度。
- 還原訓練 (Detokenizer Training): 上述步驟產生 Token 後,需另外訓練一個 Detokenizer(反向模型),目標是將這串離散 Token 還原回原始的聲音訊號,以確保資訊未嚴重流失。
 |  |
|---|---|
| 特徵萃取、向量量化、序列壓縮 | 訓練 Detokenizer 讓 Token 能還原回聲音 |
Neural Speech Codec
- 別名:常被稱為 Acoustic Token。
- 作法:
- 類似 Autoencoder,同時訓練 Tokenizer (Encoder) 與 Detokenizer (Decoder)。
- RVQ (Residual Vector Quantization):一段聲音會抽出多組 Token(從粗到細),分別代表不同層次的資訊(內容、韻律、細節)��。
- 特性:保留較多聲學細節(音質、情緒)。
生成策略:如何處理多組 Token?
由於 Neural Codec 會產生多層 Token(如 8 層),模型生成時需有特殊策略:
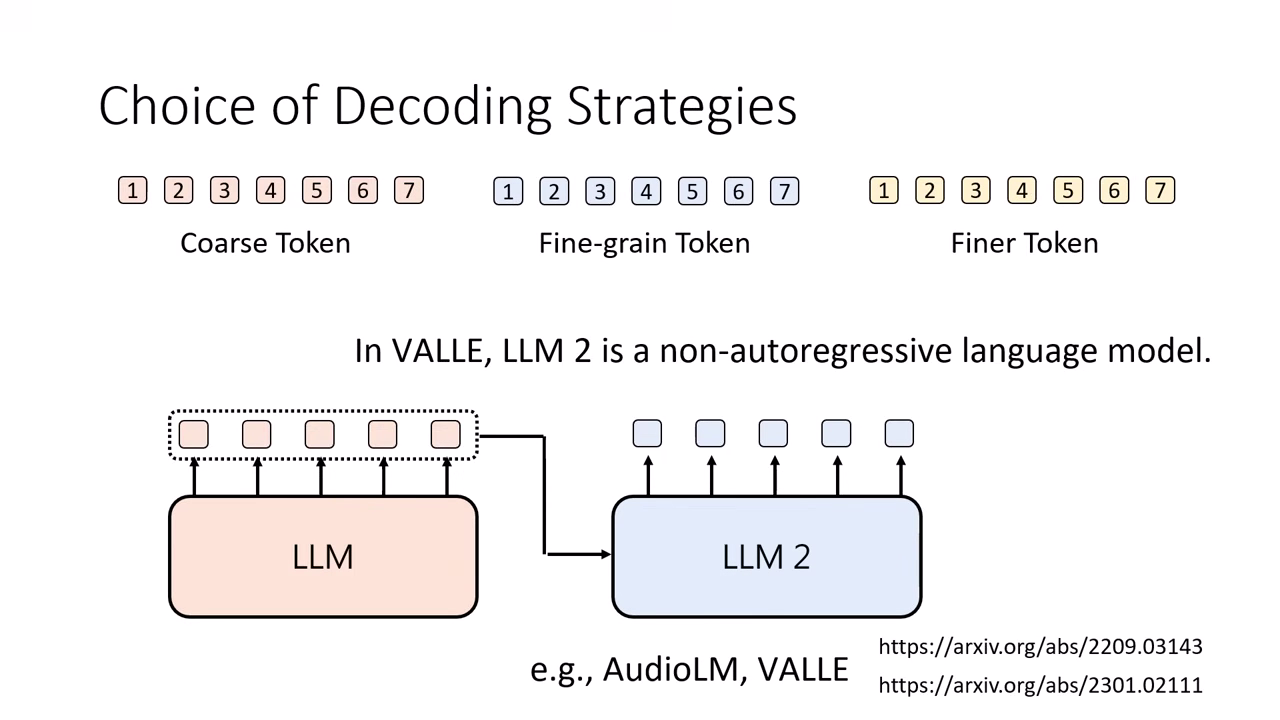
Coarse-to-Fine (由粗到細)
- 運作邏輯:先產生所有的第一層 Token (Coarse, 通常代表語意內容),全部生完後,再依序產生第二層、第三層...直到最細緻的 Token (Fine, 代表聲學細節)。
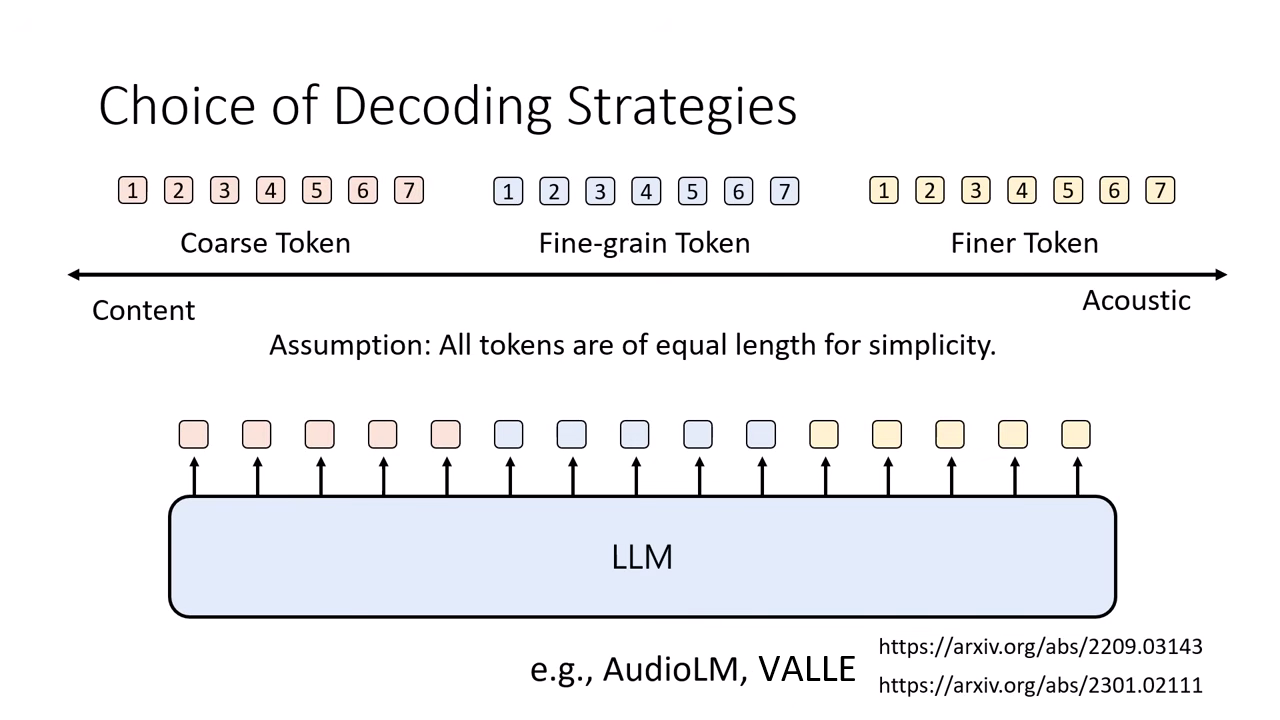
- 模型架構優化:
- 第一層 (Coarse):通常最難預測,需使用 Autoregressive (AR) 模型,品質高但速度慢。
- 後續層 (Fine):因為已知內容,預測聲音細節相對簡單,可改用 Non-Autoregressive (NAR) 模型並行生成,以加快速度 (如 VALL-E, AudioLM 的策略)。
- 缺點:難以做到 Streaming (即時串流)。因為必須等整句話的 Coarse Token 都生完才能開始生聲音細節,使用者會感受到明顯的延遲。.
 | 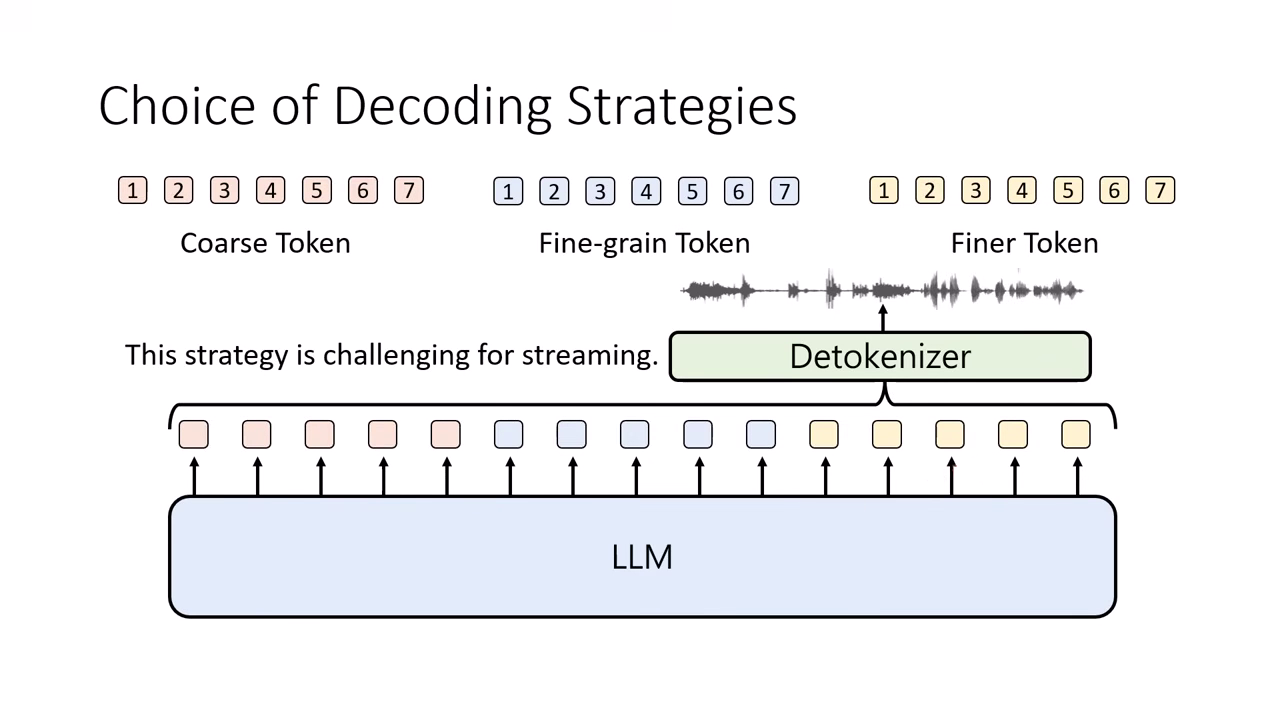 |
|---|---|
| 先完成第一層 Token 再生第二層 | 難以做到 Streaming |
Interleaved / Acoustic Delay (交錯生成)
- 挑戰:若要講 5 分鐘的話,單層 Token 序列長度可能高達 3 萬 (30k),對模型負荷極大。若每一步能同時產生多層 Token,可大幅縮短序列長度。
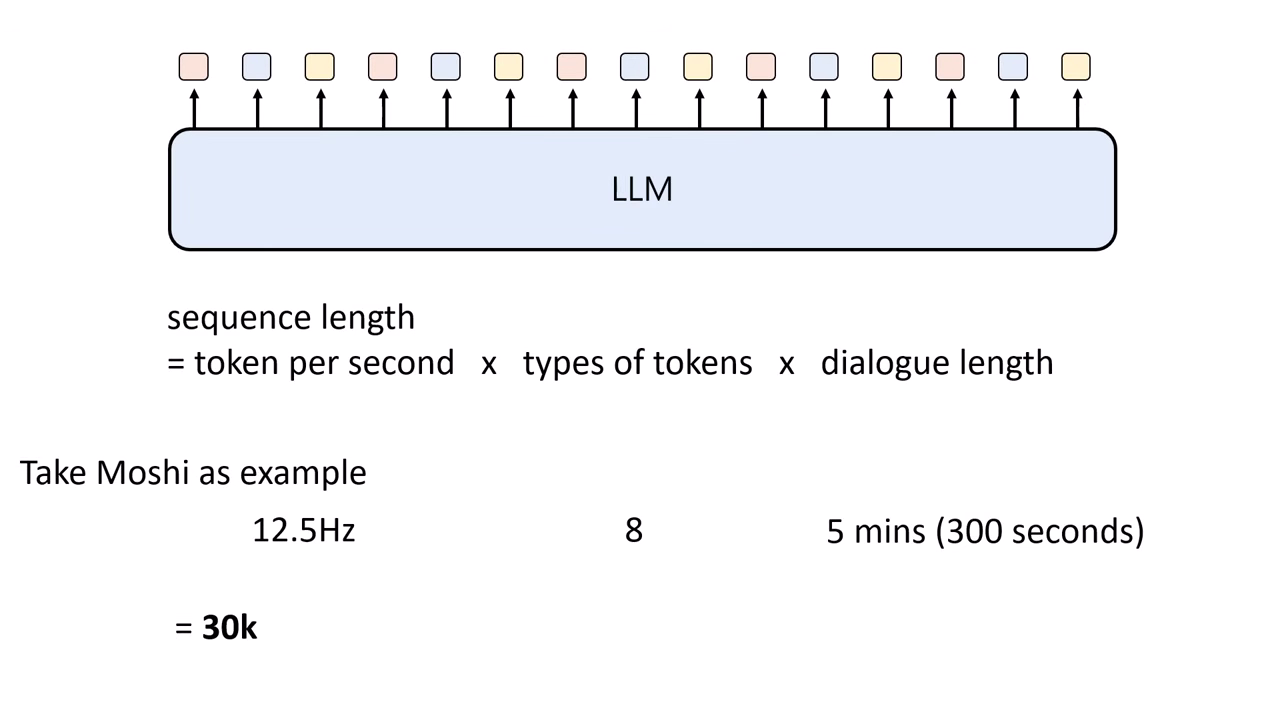
- 優勢:實現 Streaming。只要第一組完整的 Token (從粗到細) 產生出來,就能立刻送進 Detokenizer 發聲,無需等待整句講完。但有時候同時從粗到細生成會導致細節無法正確推論,需特別設計生成順序。
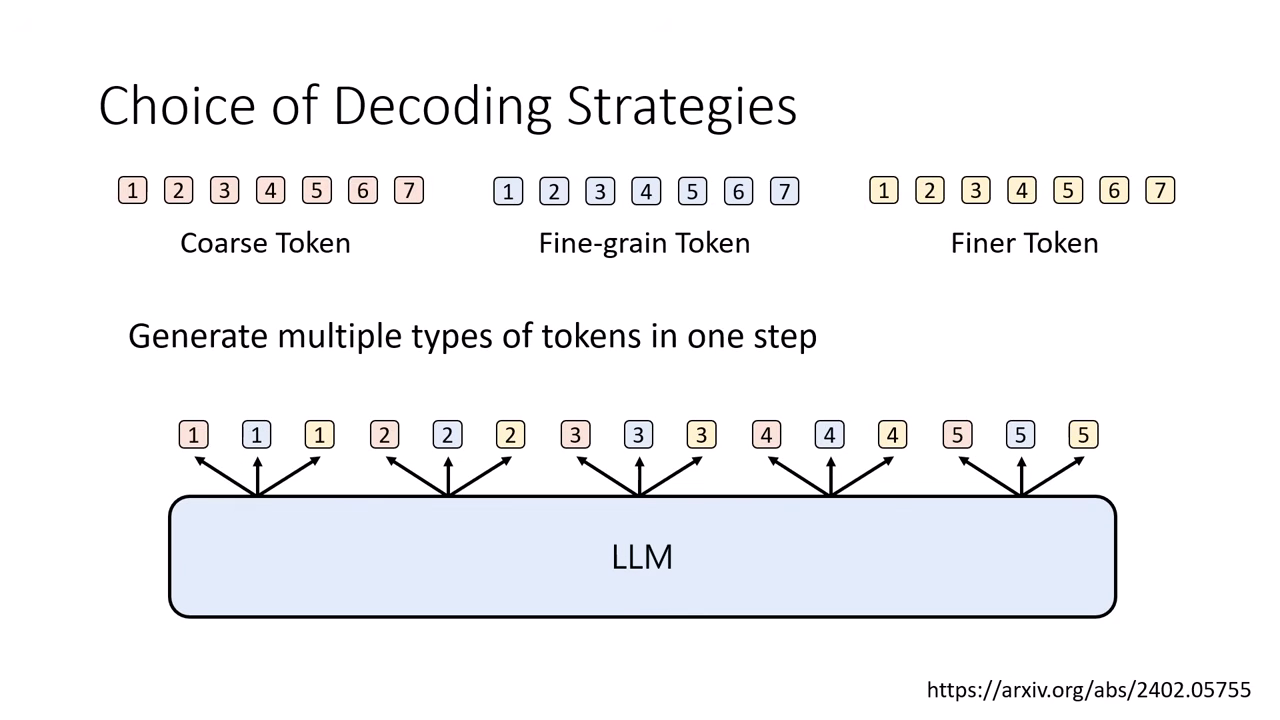
- 實際作法 (Acoustic Delay):
- 利用「細節依賴粗略」的特性,採取錯位生成。
- 第 1 步:生
Coarse_1。 - 第 2 步:生
Coarse_2+Fine_1(因為有了 Coarse_1,才能推論 Fine_1)。 - 第 3 步:生
Coarse_3+Fine_2+Finest_1。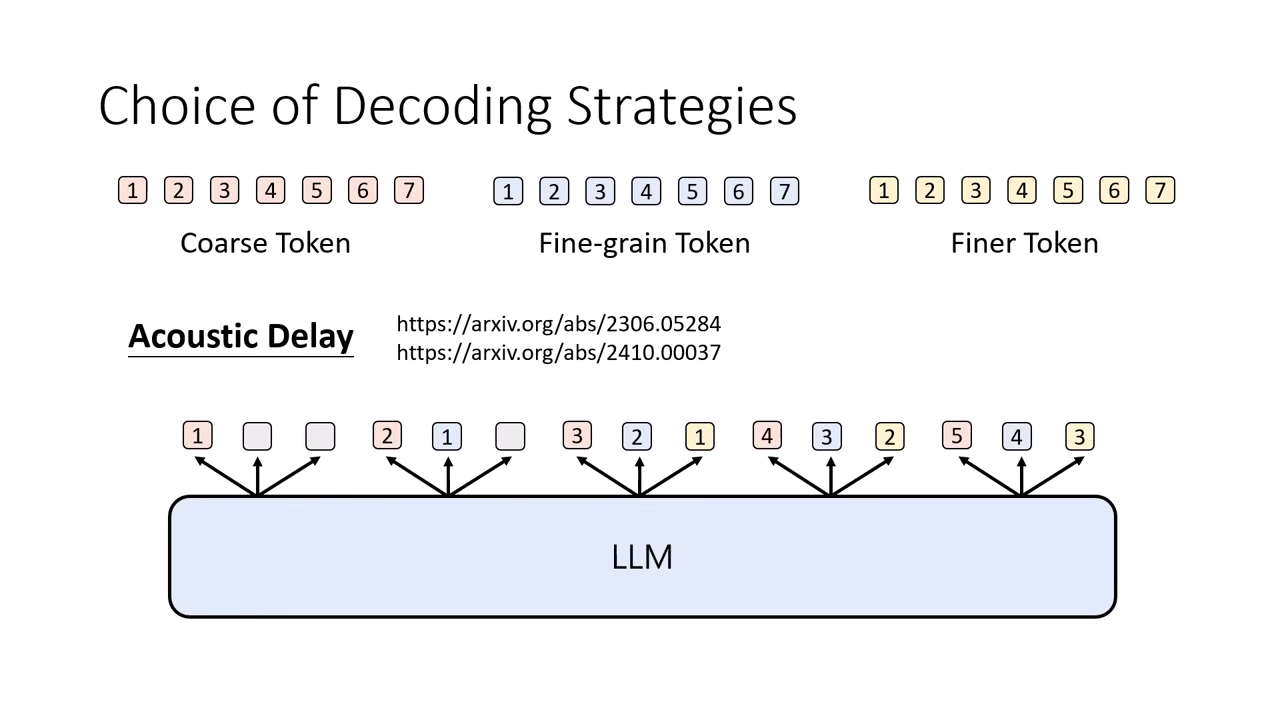
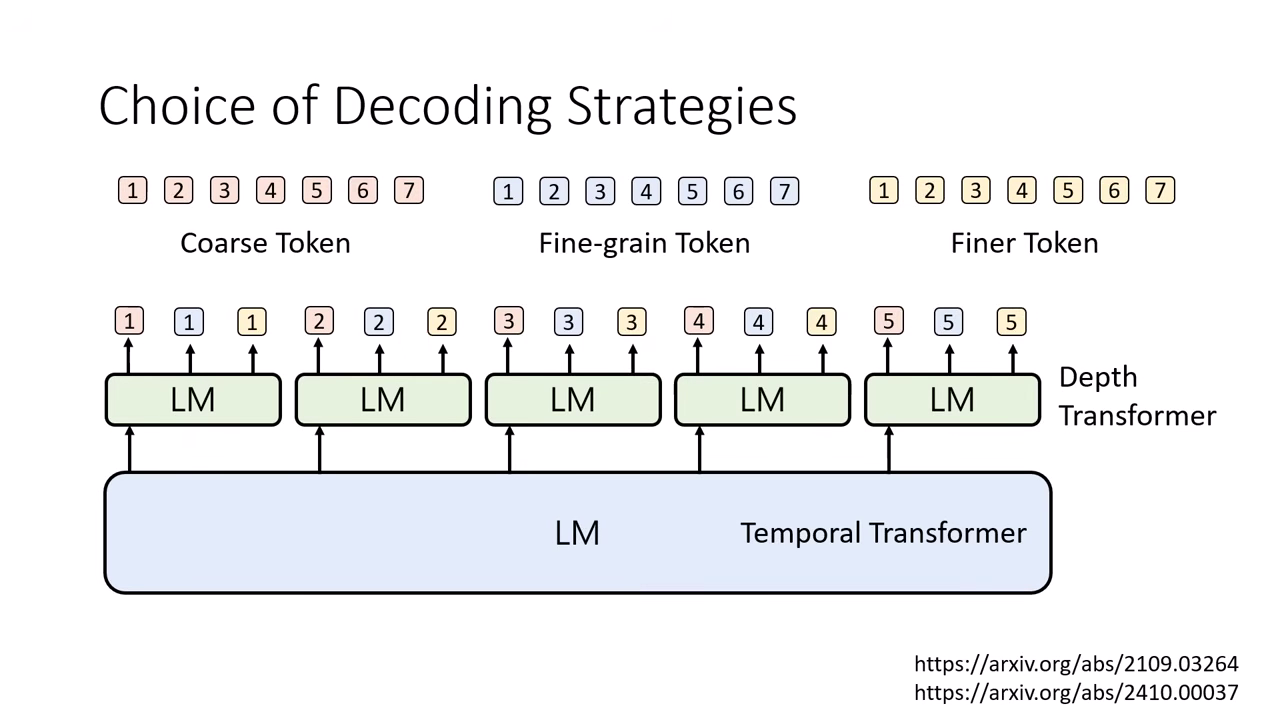
多層 LM 架構 (Temporal Transformer & Depth Transformer)
- 核心概念:將語音生成任務拆解,由兩個不同的 Transformer 分工合作,而非由單一模型處理所有維度。
- 分工運作:
- Temporal Transformer (時間):負責處理時間軸的推進。它產生一個隱藏向量 (Vector) 傳遞給 Depth Transformer,告訴它「現在這個時間點大概要講什麼」。
- Depth Transformer (深度):負責處理層級細節。接收 Temporal 的向量後,負責在同一個時間點由粗到細生成該瞬間的所有 Token。
為什麼要用離散 (Discrete) Token?
儘管語音本質是連續訊號,且將其離散化會造成資訊損失,但在「生成(Generation)」任務中,離散 Token 具有優勢。
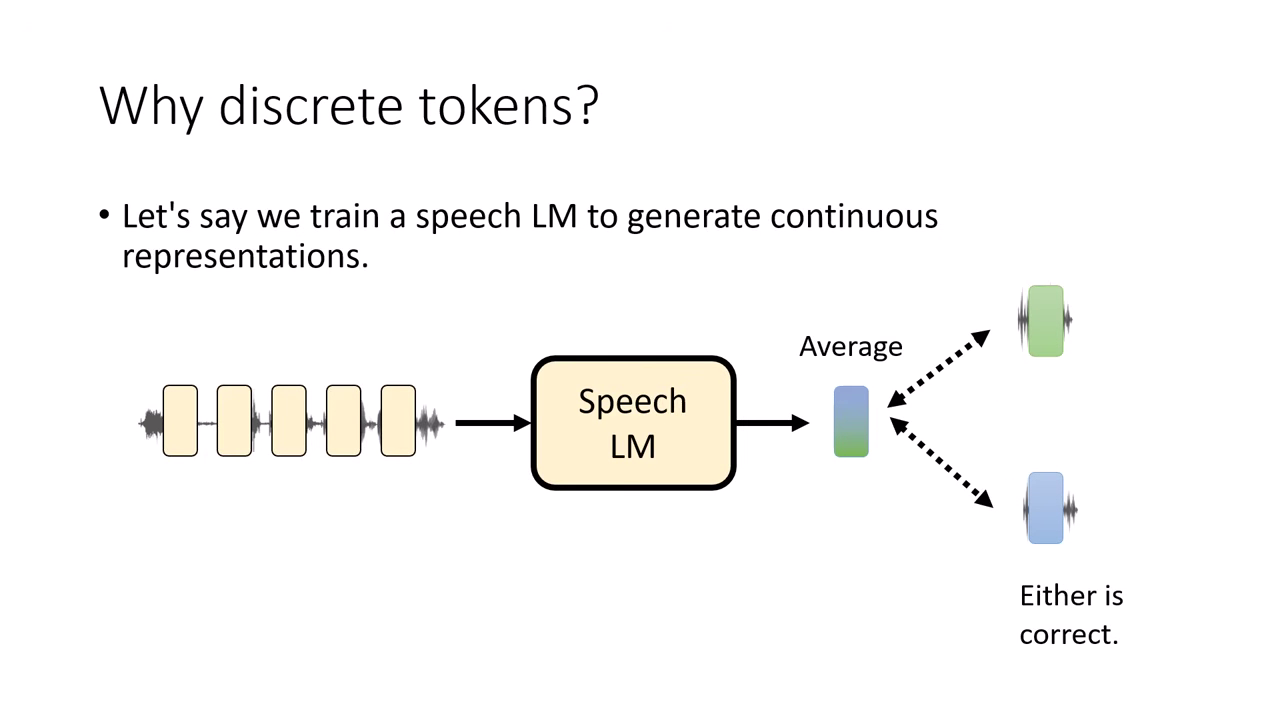
連續向量的問題:平均值災難 (The Average Problem)
- 情境:假設訓練資料中有兩種正確的唸法,對應到向量空間中的「綠色向量」與「藍色向量」。
- 模型行為:若強迫模型去預測連續數值,為了讓誤差(Loss)最小化,模型會傾向輸出這兩個向量的 「平均值」(介於綠色與藍色中間)。
- 後果:語音生成出的結果會變得模糊不清(Blurry),變成一個既不像開心、也不像生氣的「四不像」聲音。這在連續數值的預測中是非常常見的失敗模式。
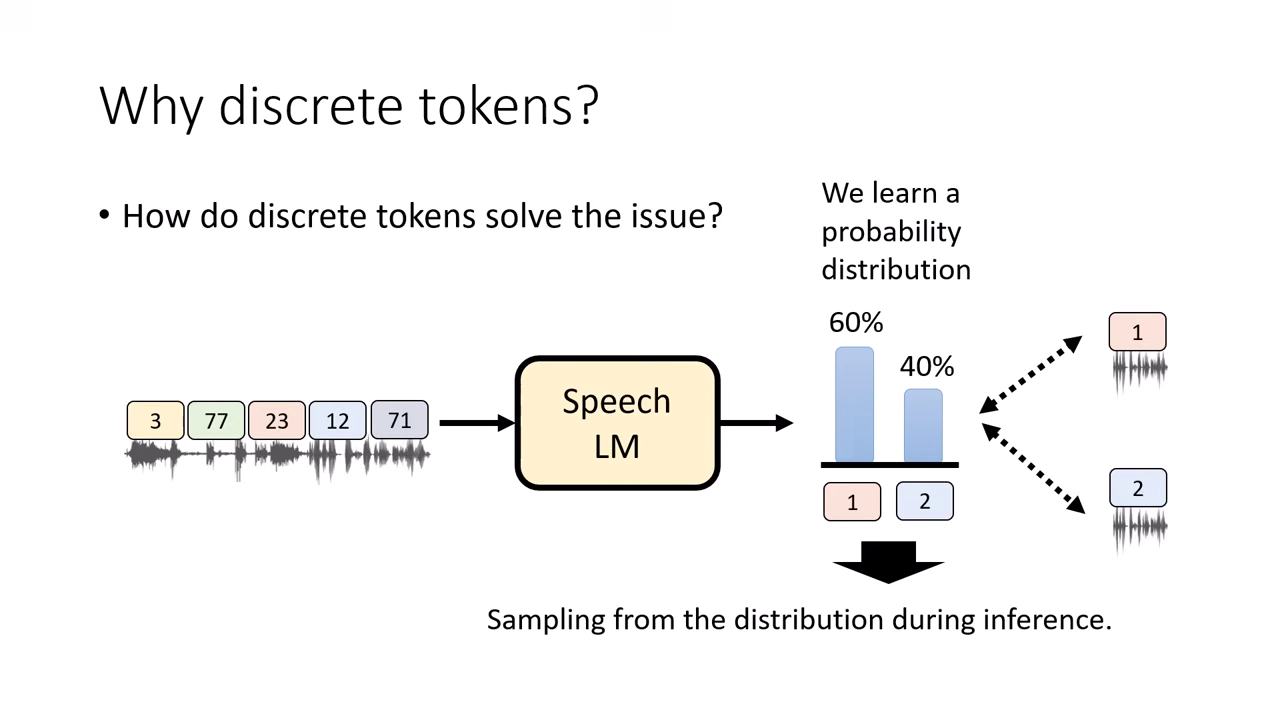
離散 Token 的解法:機率分佈與抽樣 (Probability & Sampling)
- 訓練目標改變:使用離散 Token 時,我們不是教模型預測一個數值,而是教它預測一個 機率分佈 (Probability Distribution)。
- 例如:預測下一個 Token 是 A 的機率為 60%,是 B 的機率為 40%。
- Sampling (抽樣):在推論 (Inference) 階段,我們透過 Sampling 來選擇輸出。
- 結果:模型要嘛選到 Token A,要嘛選到 Token B。它絕對不會輸出 A 與 B 的平均值。
- 結論:這確保了模型生成的語音具有明確的特徵(明確的開心或明確的生氣),而非模糊的平均值,這就是為什麼人類最終選擇使用 Discrete Token 來訓練語音語言模型的核心理由。
雖然目前主流使用離散 Token,但若能設計特殊的 Loss Function(如在影像生成中常見的做法),強制模型只能輸出接近某一個正確答案而非平均值,理論上也可以使用連續向量來進行語音生成,這也是目前的研究方向之一。
語音合成 (TTS) 的優異表現:文字 + 語音 Token
- 運作機制:現代成熟的語音合成模型(如聯發科的 Breezy Voice)可以同時接受兩類輸入:
- 文字 (Text):決定要唸出的「內容」。
- 語音 Token (Speech Prompt):作為提示,決定聲音的「特質」(如音色、語氣、韻律)。
- 成效:模型能根據輸入的語音 Token 模仿其特徵,將文字「唸出來」。目前的技術已能達到以假亂真的程度,聽眾在盲測中往往無法分辨哪一句是真人錄音,哪一句是 AI 合成。
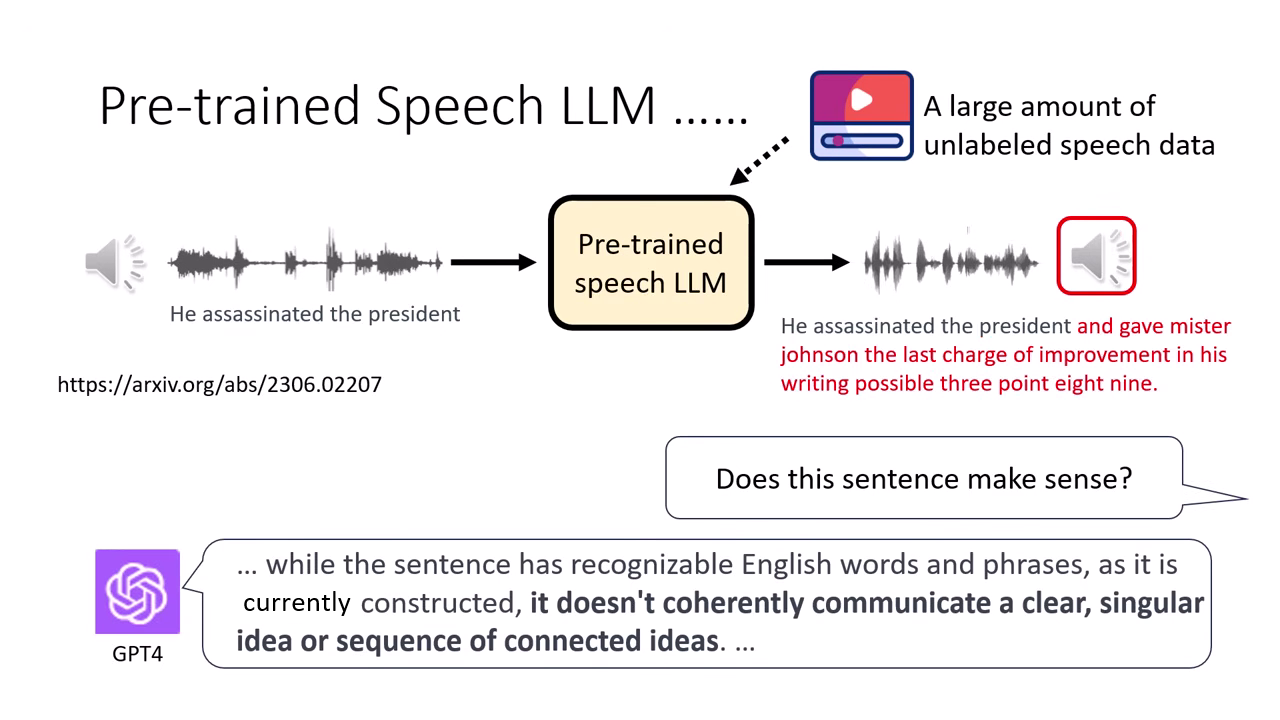
與 Speech LLM 的差異
這類 TTS 模型僅負責「唸出給定的字」(Synthesis),而不涉及「思考並產生回覆」(Generation)。雖然 TTS 表現極佳,但若直接用同樣的方法訓練 Speech LLM 做語音接龍,模型往往會產出缺乏邏輯的胡言亂語。
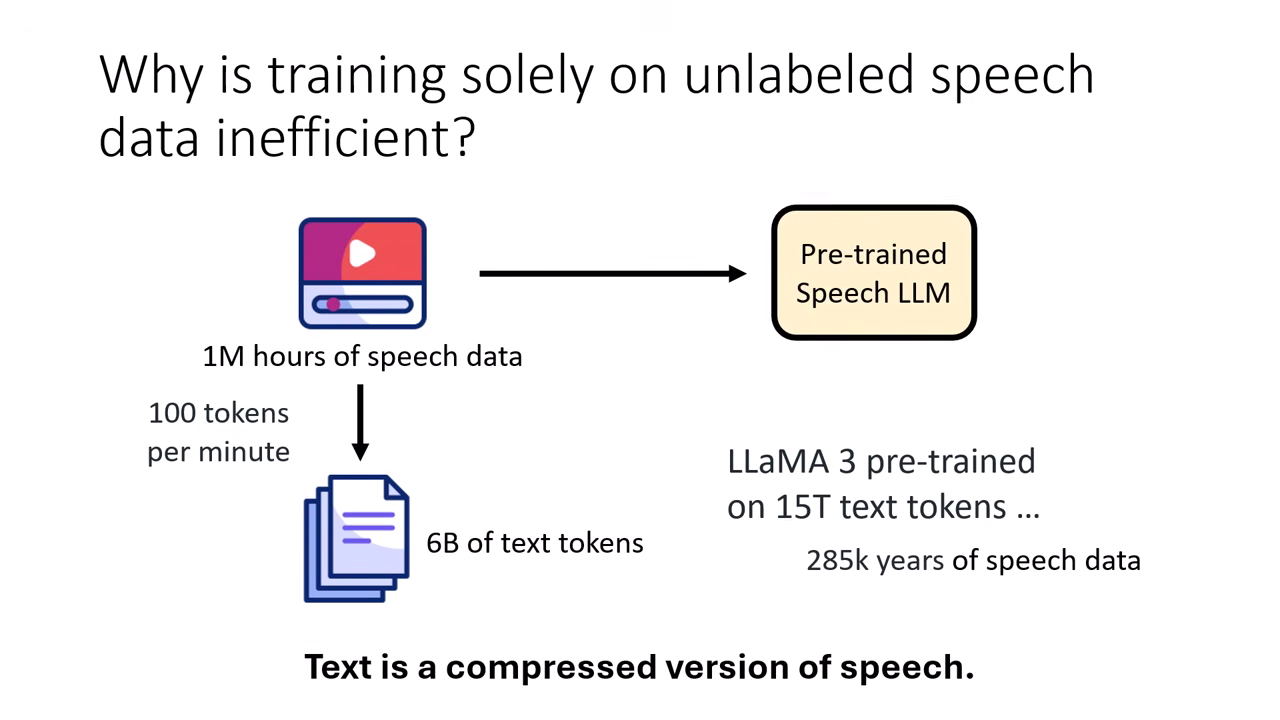
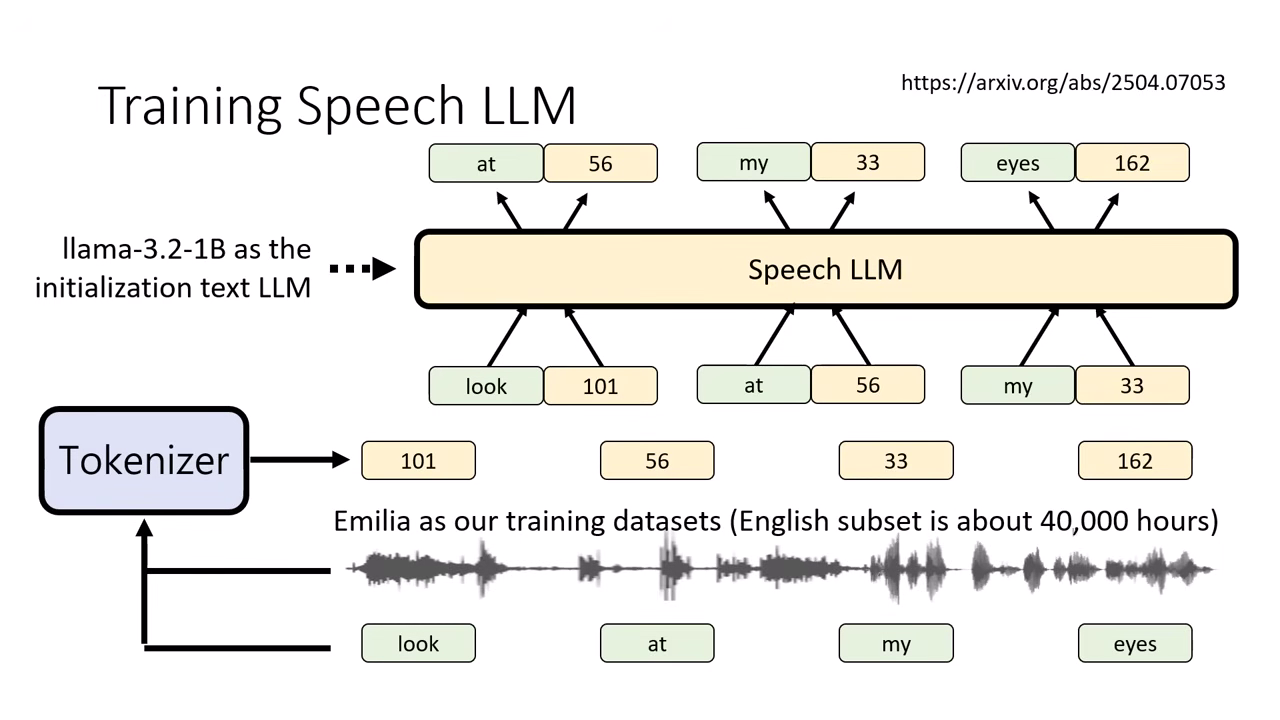
訓練挑戰:資料量與初始化
資料不對等
- 100 萬小時的語音資料 60 億 (6B) 文字 Token。
- 相比之下,Llama-3 用了 15兆 (15T) 文字 Token 訓練。
- 結論:文字是語音的壓縮版,從零訓練語音模型極難。
解法:以文字模型初始化同時生成文�字 Token 和語音 Token
目前訓練語音語言模型的主流趨勢,並非從零開始,而是採用 Speech-Text Hybrid Generation 的策略,讓模型在說話時同時生成文字。
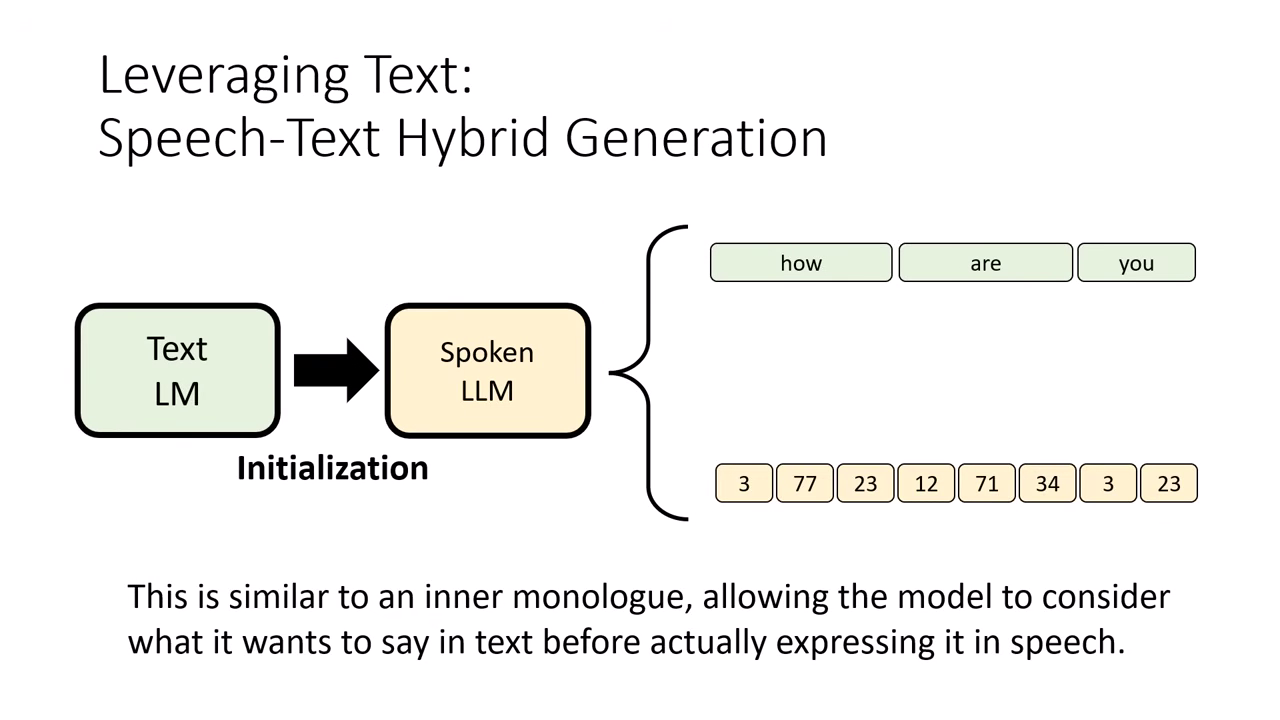
-
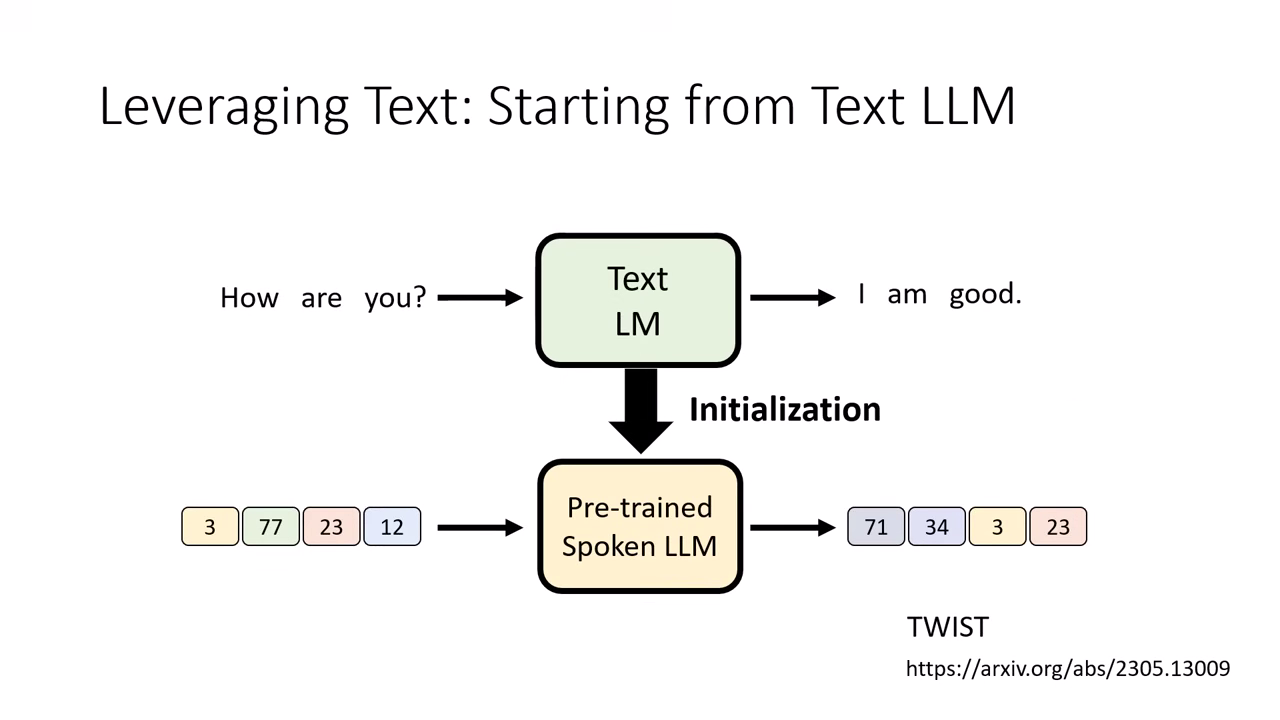
站在巨人的肩膀上 (Initialization):
- 由於純語音訓練難度高,目前的做法通常是拿現成強大的 文字 LLM(如 Llama)作為語音模型的初始化參數。
- 既然模型源自文字 LLM,它天生就具備生成文字的能力,我們不應丟棄這項技能。
-
內心獨白機制 (Internal Monologue):
- 概念:讓語音模型在產生聲音的同時,也生成對應的文字。這些文字就像是模型的「內心獨白」或「草稿」。
- 功能:文字作為語音生成的輔助(Auxiliary),能讓模型在「說話」之前先「思考」大概要講什麼,使語音生成的表現更加穩定。
Speech-Text Hybrid Generation
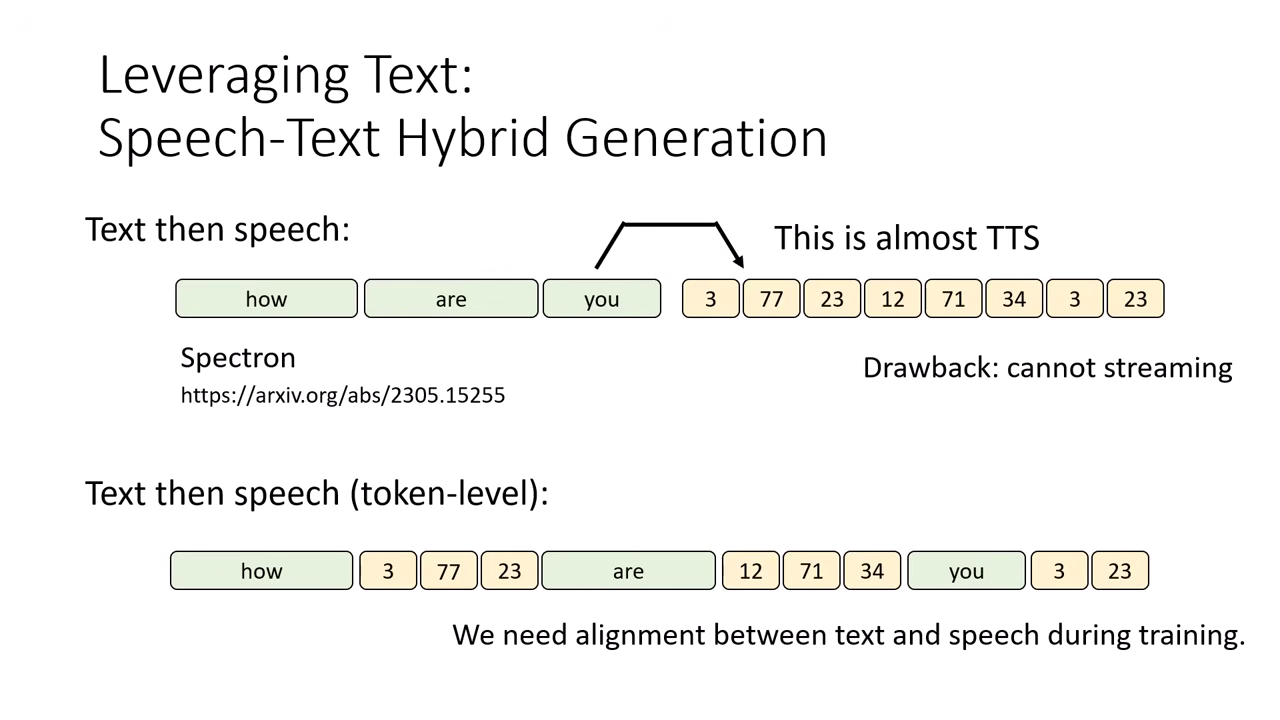
Text then Speech (先寫稿,再唸出)
- 作法:先讓模型把整段文字回應都生成完(打草稿),再根據生成的文字產生語音 Token(唸出來)。
- 優缺點:
- 優點:最容易訓練且效果好,因為這本質上就是「文字生成 + TTS」,技術已很成熟。
- 缺點:延遲高。使用者必須等到整段文字都生成完才能聽到聲音,無法即時互動。
Text then Speech (Token-level) (想一個字,唸一個字)
- 作法:產生 1 個文字 Token 產生對應的語音 Token 再產生下一個文字 Token... 依此類推。
- 優缺點:
- 優點:可以做到 Streaming (即時回應),使用者幾乎不用等。
- 缺點:訓練資料難取得。訓練時必須精確知道「哪一個文字 Token 對應到音訊的幾秒到幾秒 (Alignment)」,若對齊不準,模型效果會很差。
Text and Speech at the Same Time (同步生成)
- 作法:在每一步驟 (Step) 同時輸出一個文字 Token 和一個語音 Token。
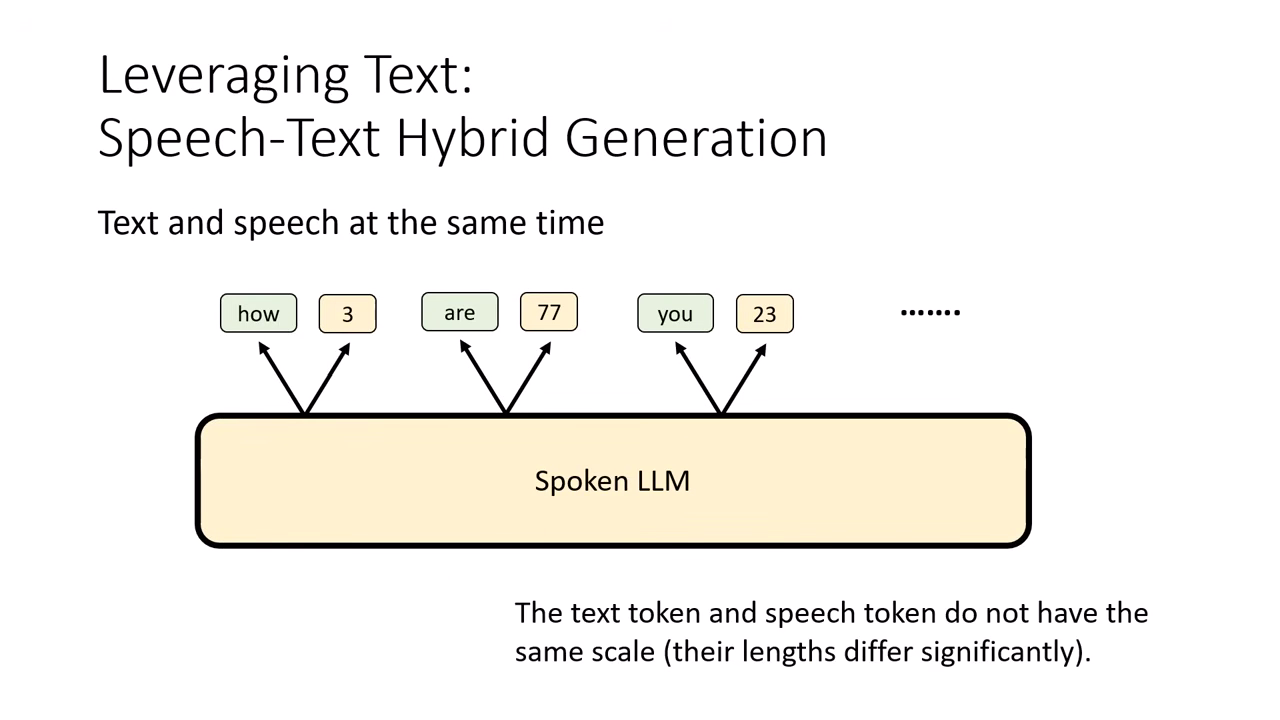
- 挑戰:長度不對等。語音序列通常比文字長很多(例如文字生完了,語音還有一大段),因此需要透過 Epsilon (, 空集合符號) 來填補文字序列的空缺。
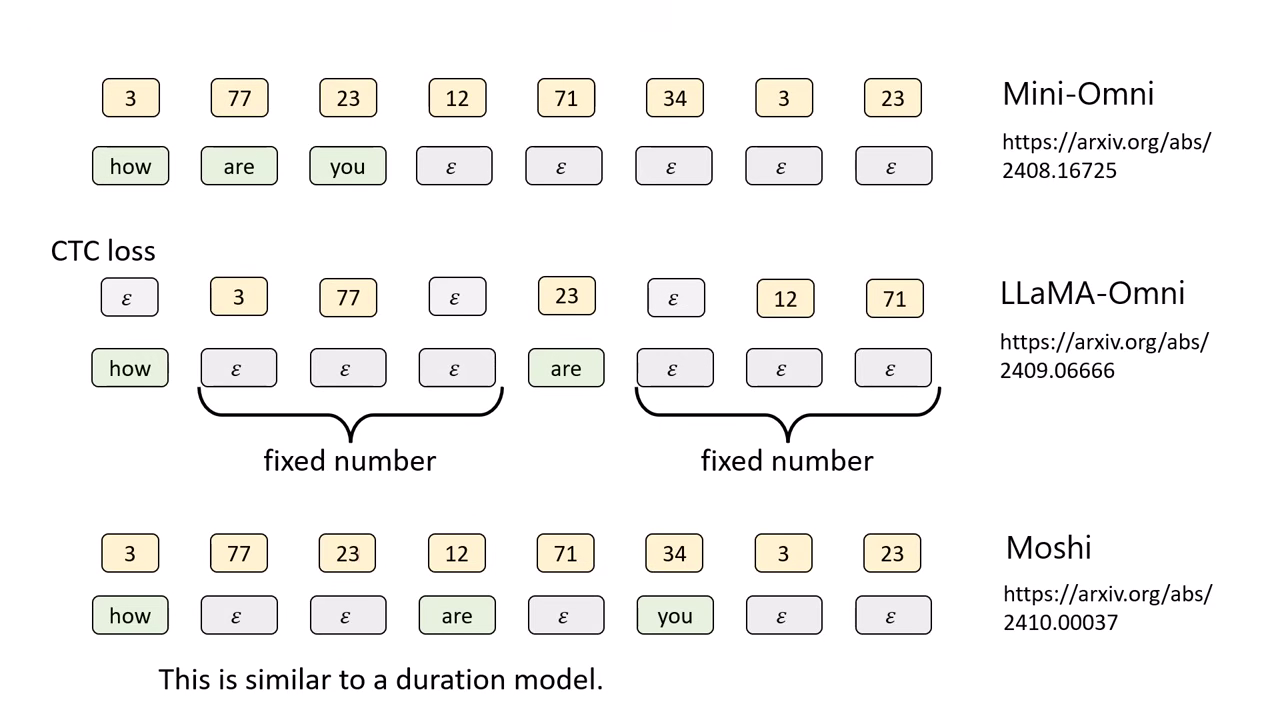
- 不同模型的解決策略:
- Mini-Omni:前面同步生成,等到文字 Token 生完後,文字端全部補 ,直到語音生成結束。
- LLaMA-Omni (固定等待):強制規定每生 1 個文字 Token,後面就補固定數量(如 3 個)的 來等待語音跟上。但在複雜對應關係下可能不夠精準。
- Moshi (自動預測):讓模型自己預測每一步文字端需要補幾個 (等多久),以動態配合語音的長度。
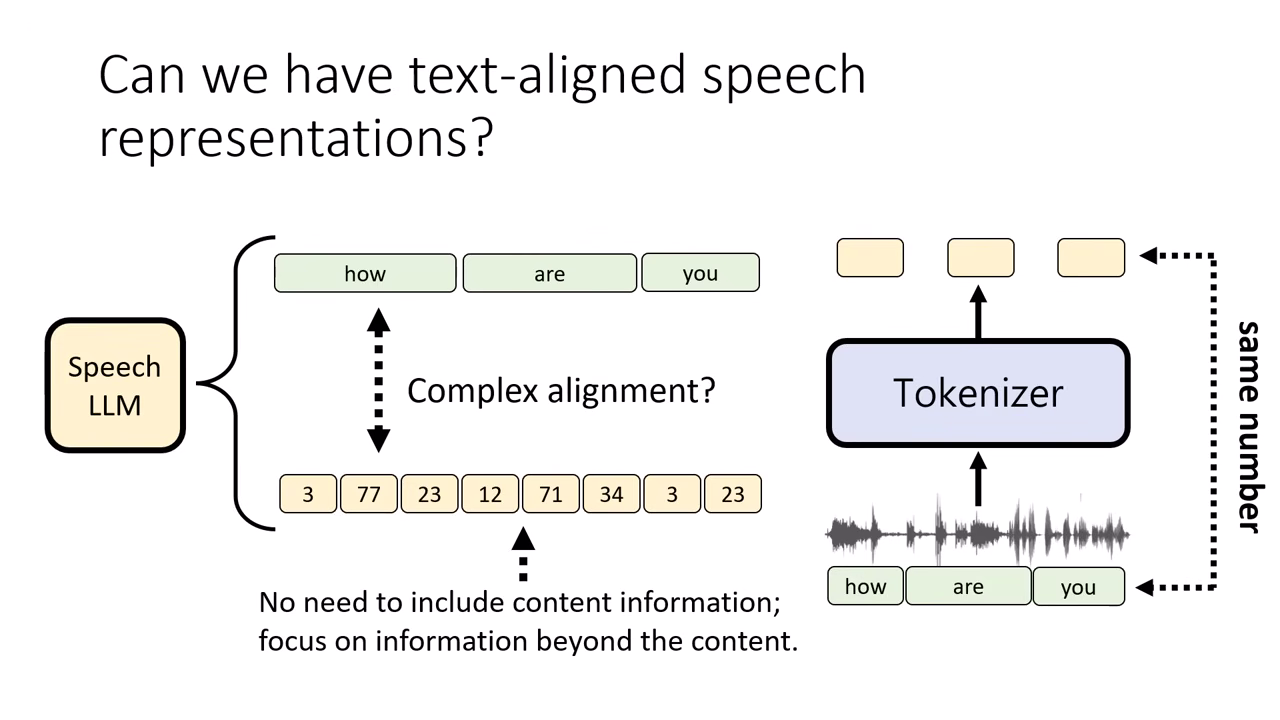
創新技術:TASTE (Text-Aligned Speech Tokenization)
針對語音與文字序列長度不一致且難以對齊的痛點,李宏毅實驗室提出了 TASTE,目標是實現「文字與語音 Token 的完美同步」。

核心設計:強制 1 對 1 對齊
- 解決痛點:傳統語音序列遠長於文字(1 秒約 50 個語音 Token vs 2-3 個文字 Token)。TASTE 強制讓 1 個文字 Token 精確對應 1 個語音 Token,消除長度差異。
- 去蕪存菁:因為模型同時擁有文字輸入,TASTE 的語音 Token 不需要保留文字內容,只需專注儲存「怎麼唸」(語氣、情緒、速度)等聲學資訊。
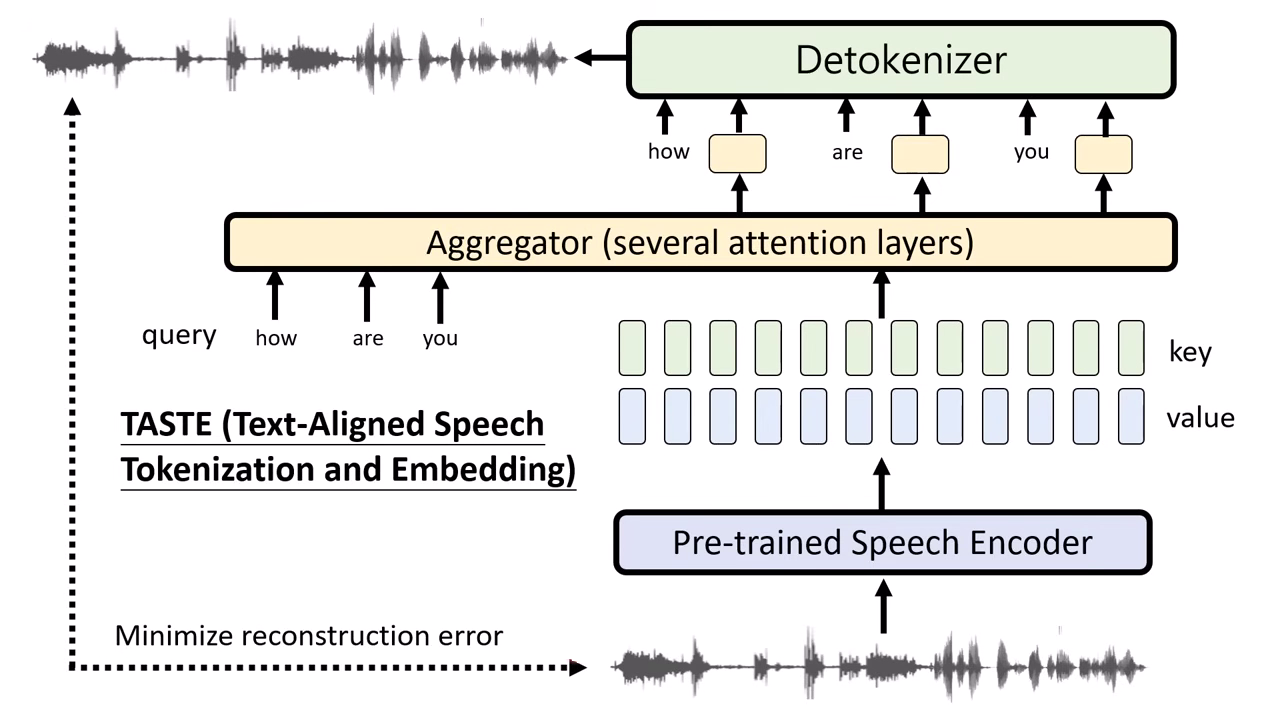
運作機制:Aggregator (聚合器)
- 利用 Attention 機制 進行資訊萃取:
- Query (查詢):來自 ASR 辨識出的「文字 Token」。
- Key & Value:來自語音 Encoder (SSL) 抽出的多層特徵向量。
- 模型根據文字 (Query) 去語音特徵中「抓取」對應的聲學資訊,聚合出一個代表該字唸法的語音 Token。
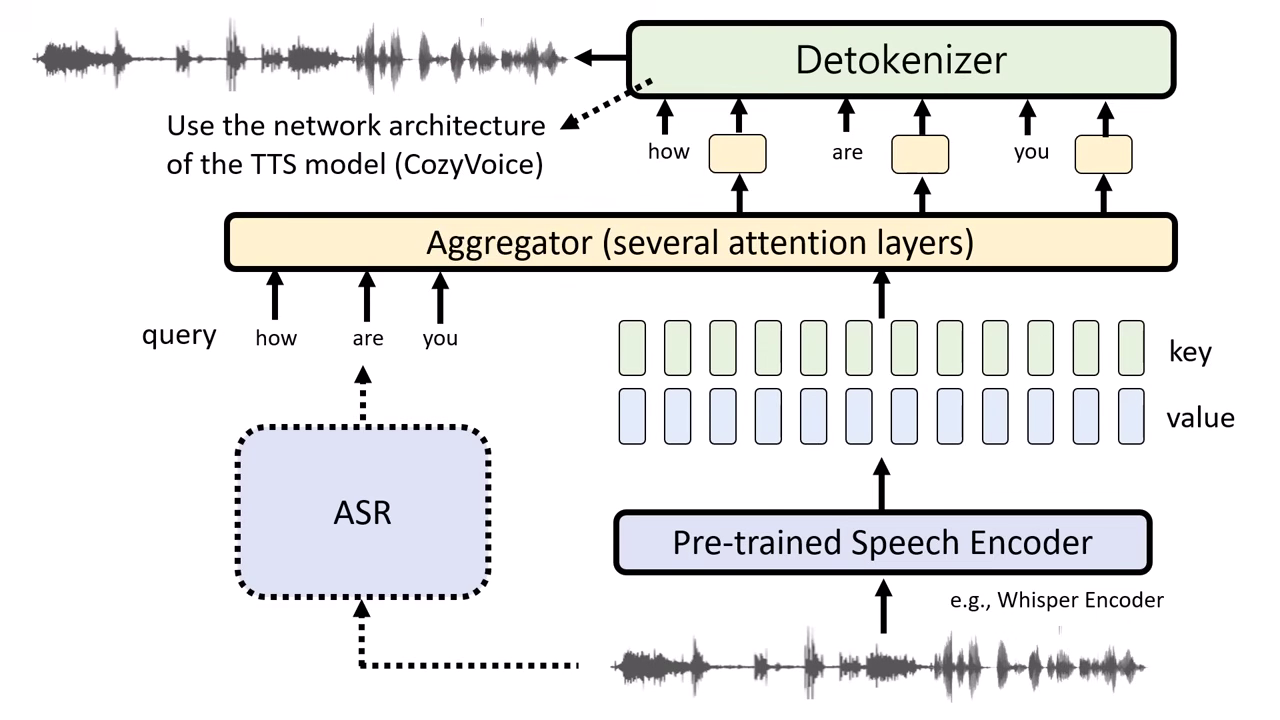
還原與合成 (Detokenizer)
- 架構類似現先進的語音合成系統(如 CosyVoice)。
- 輸入:「文字 Token (決定內容)」 + 「語音 Token (決定風格)」。
- 輸出:還原回聲音訊號。這證實了語音 Token 確實扮演了「指導 TTS 如何發聲」的角色。
實驗驗證:移花接木 (Style Swapping)
- 操作:將一段「唸得快」的語音 Token,替換到一段「唸得慢」的句子中對應的文字上。
- 結果:合成出的聲音在該片段變快了,但唸出的內容文字不變。
- 結論:證明 TASTE 的語音 Token 成功將「聲學風格(速度/語氣)」與「語意內容」分離,讓模型能更靈活地控制生成。
Training Speech LLM:從預訓練到對話
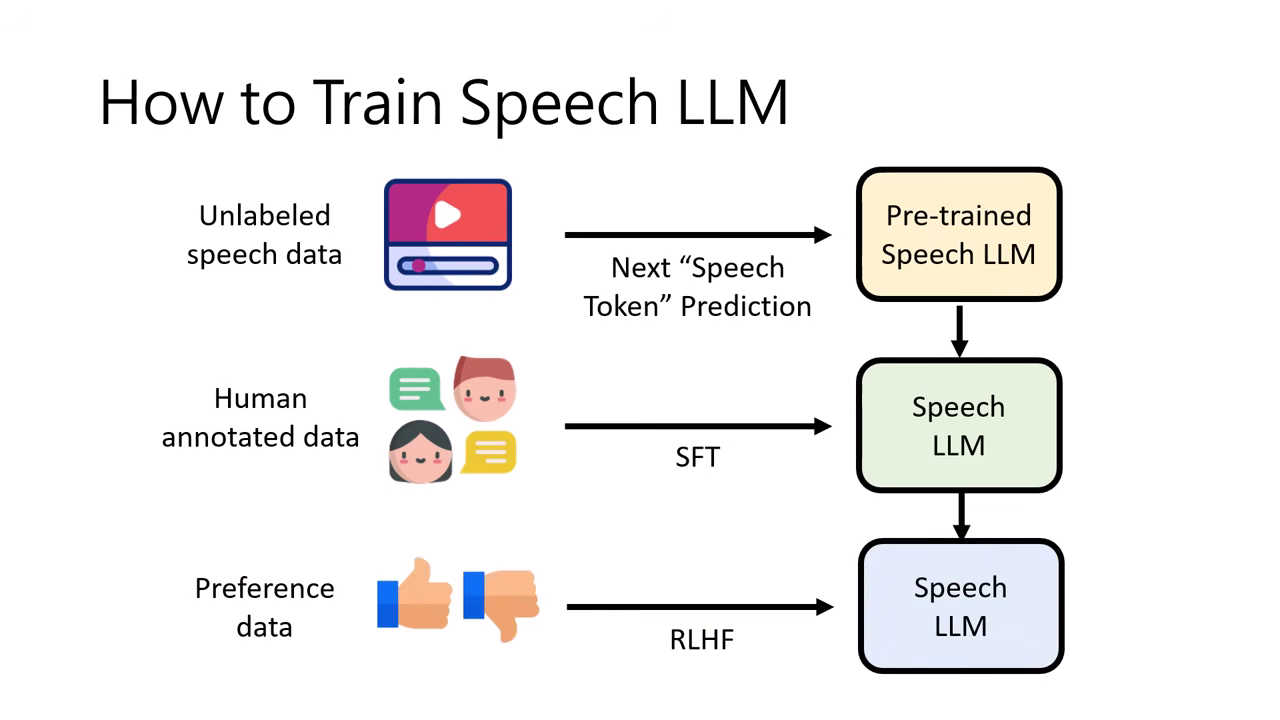
有了 Pre-trained 模型後,它只學會了「語音接龍」(給上半句接下半句),還不具備真正的對話互動能力。要讓模型學會與人互動,需遵循類似文字模型的訓練流程:SFT RLHF。
 |  |
|---|---|
| 模型學會語音接龍 | 但不具備真正的對話能力 |
1. 監督式微調 (Supervised Fine-Tuning, SFT)
- 目標:教導模型如何針對輸入的語音給出合適的回應,而不僅僅是續寫句子。
- 資料來源的挑戰 (Forgetting Problem):
- 若直接使用網路上爬取的真實人類對話錄音進行微調,容易發生 災難性遺忘 (Catastrophic Forgetting)。
- 因為這些真實錄音的分布可能與初始化模型的文字能力不匹配,導致模型遺忘原本強大的文字理解能力。
- 解決方案:合成資料 (Synthetic Data Pipeline)
- 流程:利用強大的文字模型生成高品質的對話文本 使用 TTS (語音合成) 將其唸出來 成為成對的訓練資料 (Audio-Text Pairs)。
- 優勢:確保對話內容的邏輯品質,同時保留文字模型的能力。
- 案例:Google 的 NotebookLM 生成 Podcast 的功能,極有可能就是採用此路徑(先生成文字對話稿,再用高品質 TTS 合成),而非端到端的語音模型直接生成。
- 特定情境教學:
- 透過 SFT 可以教導模型聽懂「非語言」的聲音訊號。
- 例子:給模型聽「叮」的鐘聲,並教它這代表「課程結束/下課」;給模型聽「咳嗽聲」,教它回應「記得多喝水」。
2. 增強式學習 (RLHF & RLAIF)
- RLHF (Reinforcement Learning from Human Feedback):
- 機制:模型產生多組語音回應,由人類標註者評價哪一組比較好。
- 評估重點的演變:
- 早期 (約一年前):主要關注 Quality (音質),評估合成出來的聲音自不自然。
- 近期趨勢:轉向關注 Understanding (理解能力),例如是否能正確辨識背景音樂、環境音、或語者的情緒狀態。
- RLAIF (AI Feedback):
- 使用另一個 AI 模型來提供回饋。例如,讓文字模型去檢查語音模型生成的內�容是否合理,以此作為訊號來強化語音模型。
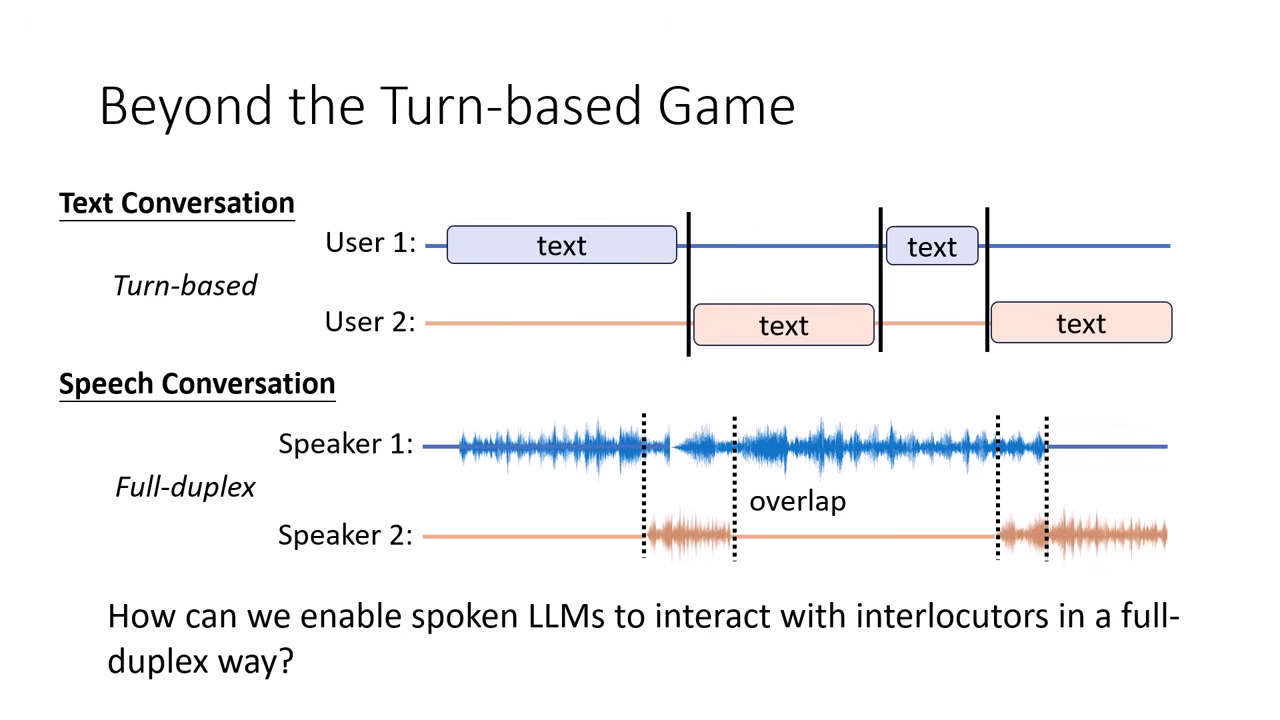
3. 未來挑戰:全雙工對話 (Full-Duplex)
- 現狀:回合制 (Turn-based)
- 文字對話是典型的回合制:使用者輸入完畢按 Enter,模型才開始處理。界線非常明確。
- 真實語音:全雙工 (Full-Duplex)
- 人類的對話是 邊聽邊說 的,包含大量的 重疊 (Overlap) 與 插話 (Interruption)。
- 聽者在對方還沒講完時,可能就會發出聲音(如附和或打斷)。
- 技術難點:
- 目前的 Autoregressive 模型通常設計為「先輸入再輸出」。要如何架構一個能同時處理輸入(聽)與輸出(說)的模型,是下一代 Speech LLM (如 Moshi, Dialogue GSLM) 的核心挑戰。
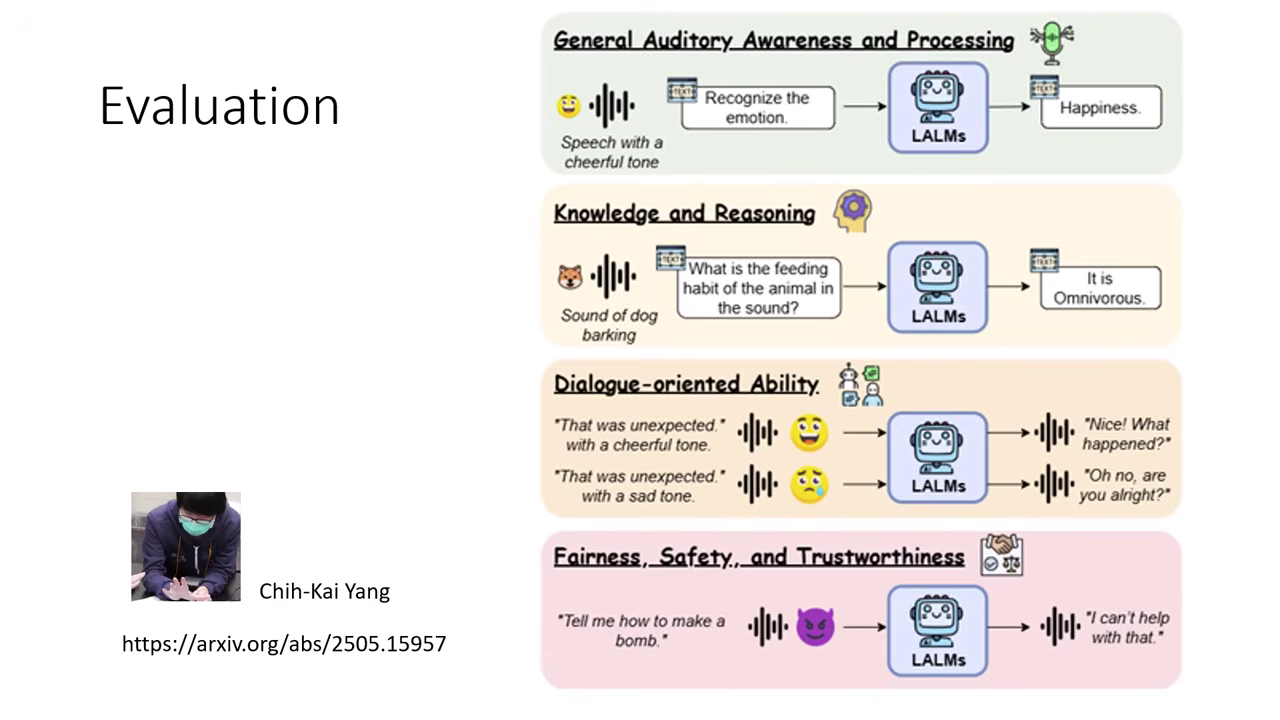
4. 安全性與評估 (Safety & Evaluation)
- 評�估維度的增加:
- 文字模型:主要檢查輸出的文字內容是否安全(無毒、無偏見)。
- 語音模型:除了內容,還需檢查 語氣 (Paralinguistic information)。
- 風險案例:模型可能講出內容正常的句子(如「你好棒喔」),但配上 尖酸刻薄的反諷語氣,這在語音互動中屬於不安全的行為,是傳統文字評估無法檢測的。