語言模型內部運作機制剖析
單一個神經元的功能與侷限
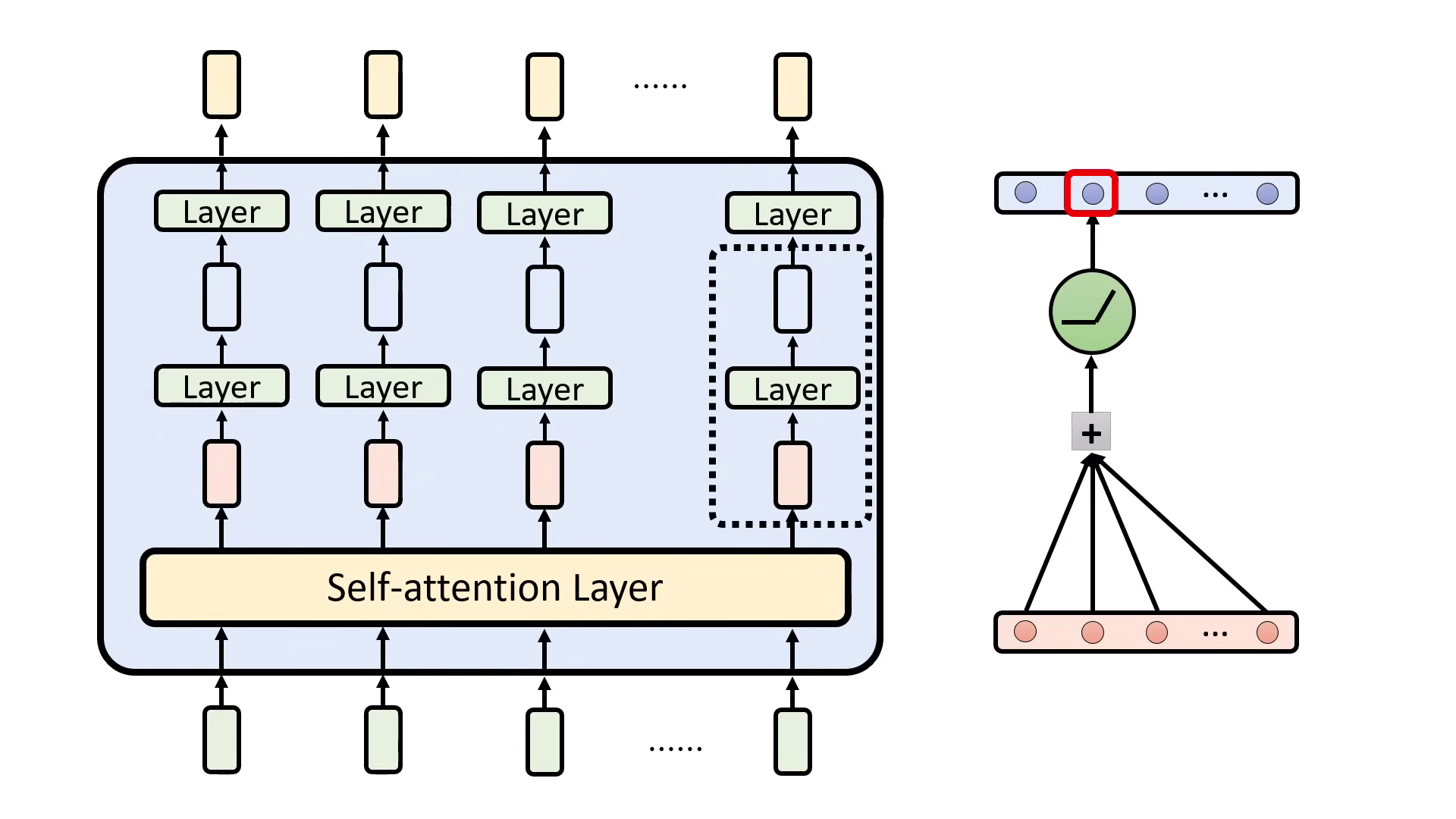
- 運作定義:在 Transformer 中,神經元的作用是將輸入向量(紅色)進行 加權總和(Weighted Sum) 並通過 啟動函數(如 ReLU) 後產生輸出(藍色)。
- 檢驗方法:
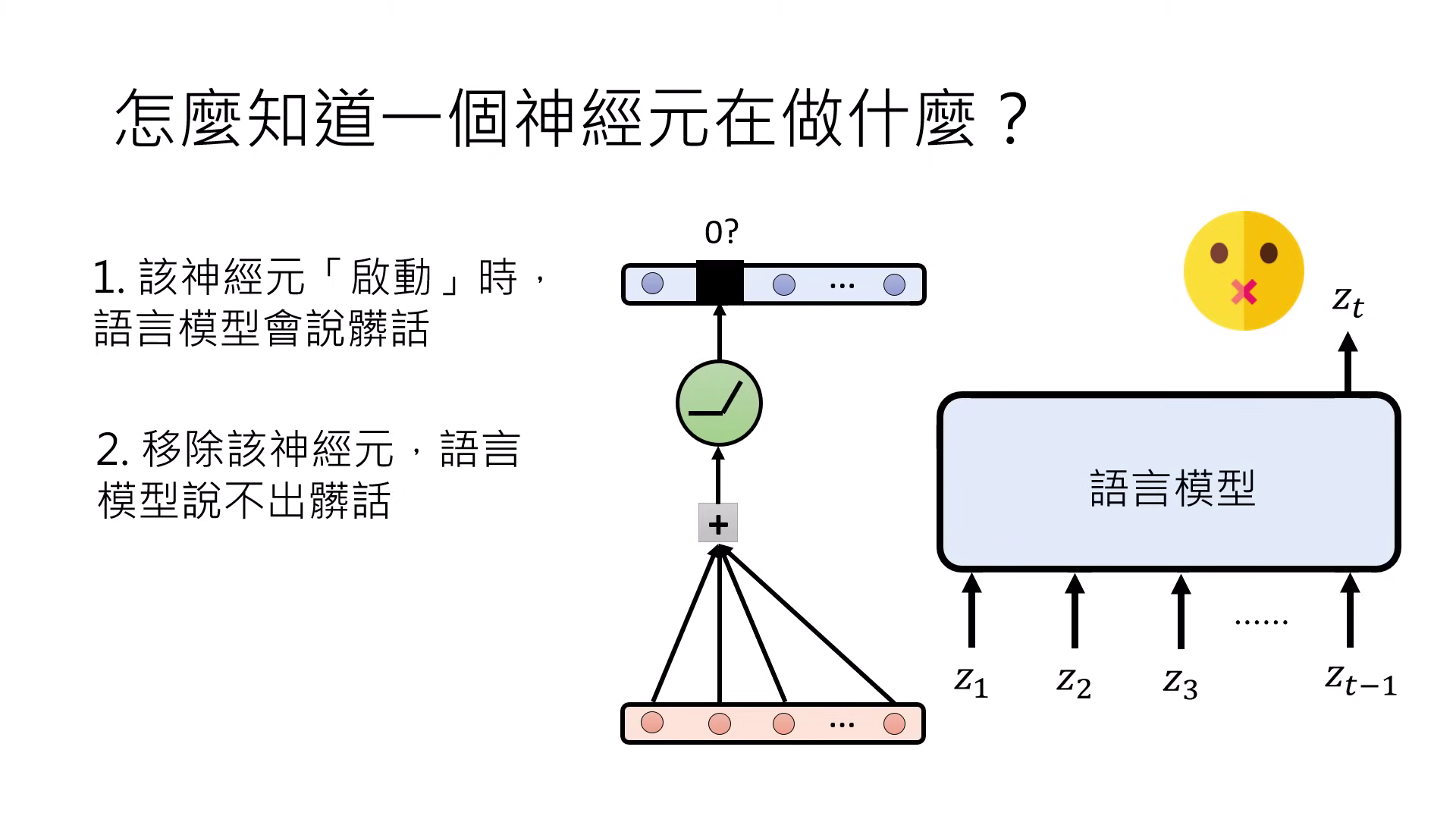
- 相關性 (Correlation):觀察神經元啟動(輸出 > 0)時是否伴隨特定現象(如模型說髒話),但啟動不代表因果。
- 因果性 (Causation):透過「移除」神經元(將輸出設為 0 或平均值)來觀察現象是否消失,以確認其功能。
- 知名的單一神經元案例:
- 川普神經元:OpenAI 發現影像模型中有神經元專門針對川普的照片、漫畫甚至文字產生反應。
- 祖母神經元(及 Jennifer Aniston 神經元):腦科學中的理論,指極少數神經元負責單一記憶。雖然人腦複雜,但在 AI 與人腦中確實觀察到類似現象。
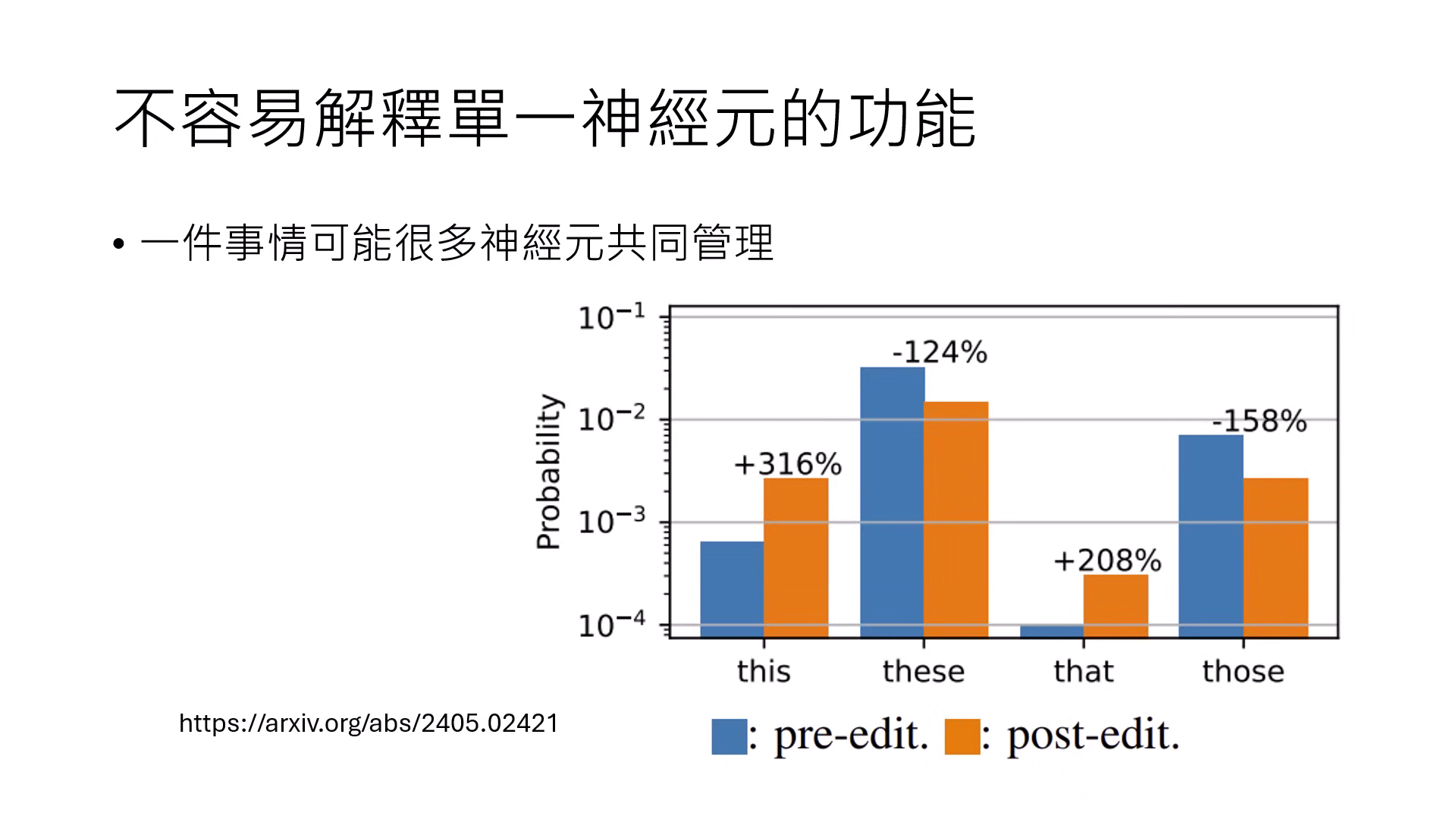
- 單一神經元的侷限:多數神經元難以解釋,且抹除單一神經元通常不會改變最終輸出,因為一個任務常由多個神經元共同管理,且一個神經元也可能同時負責多項任務。
一層神經元與功能向量 (Function Vector)
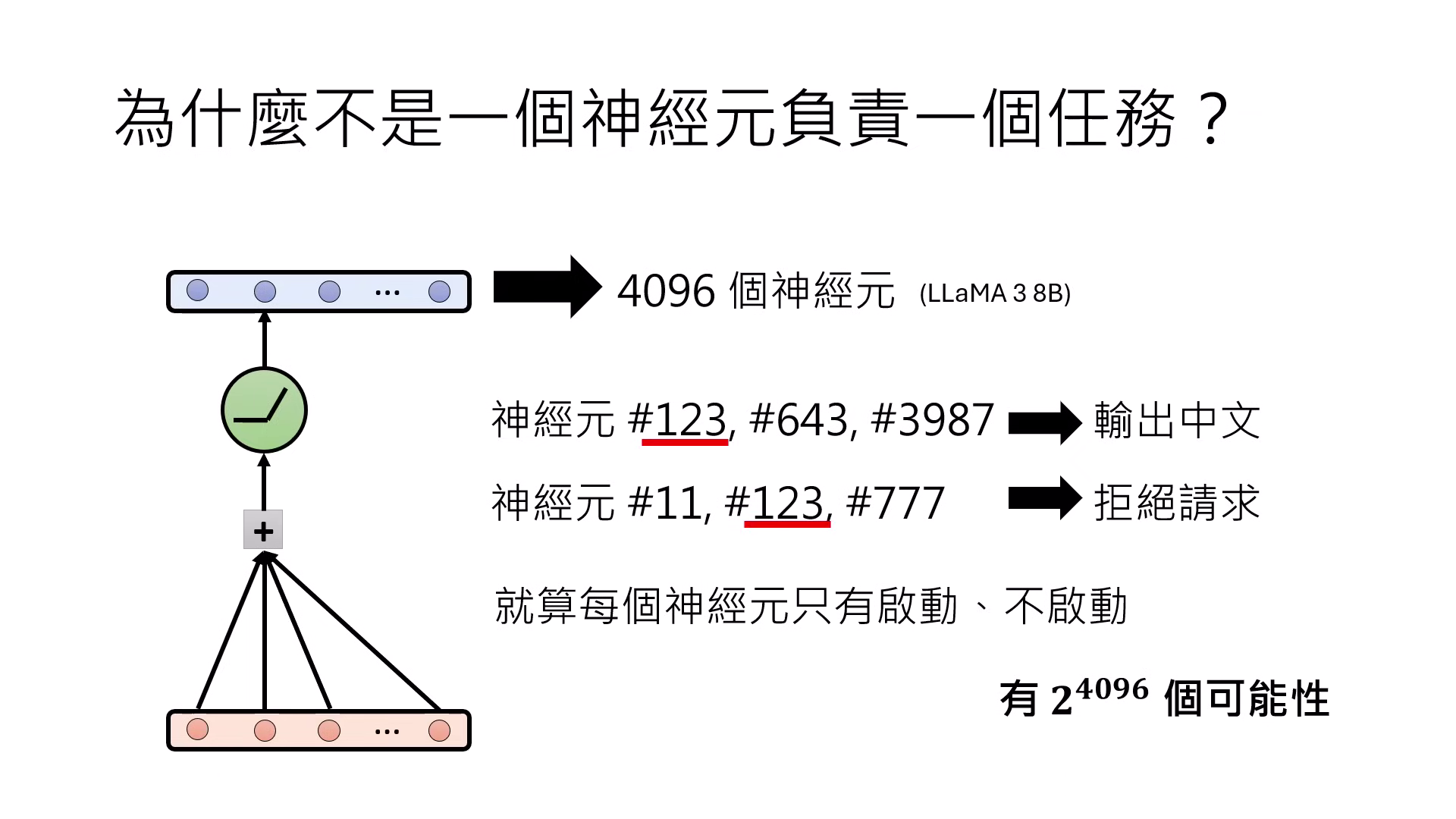
- 神經元組合驅動任務:由於模型單層神經元數量(如 4096 個)有限,若採取「一個神經元負責一個任務」的配置,模型能力將過於受限,無法應對紛繁複雜的語言需求;因此,是否有可能一組神經元的特定數值組合來負責特定任務,藉由極大量的組合方式展現出強大能力。
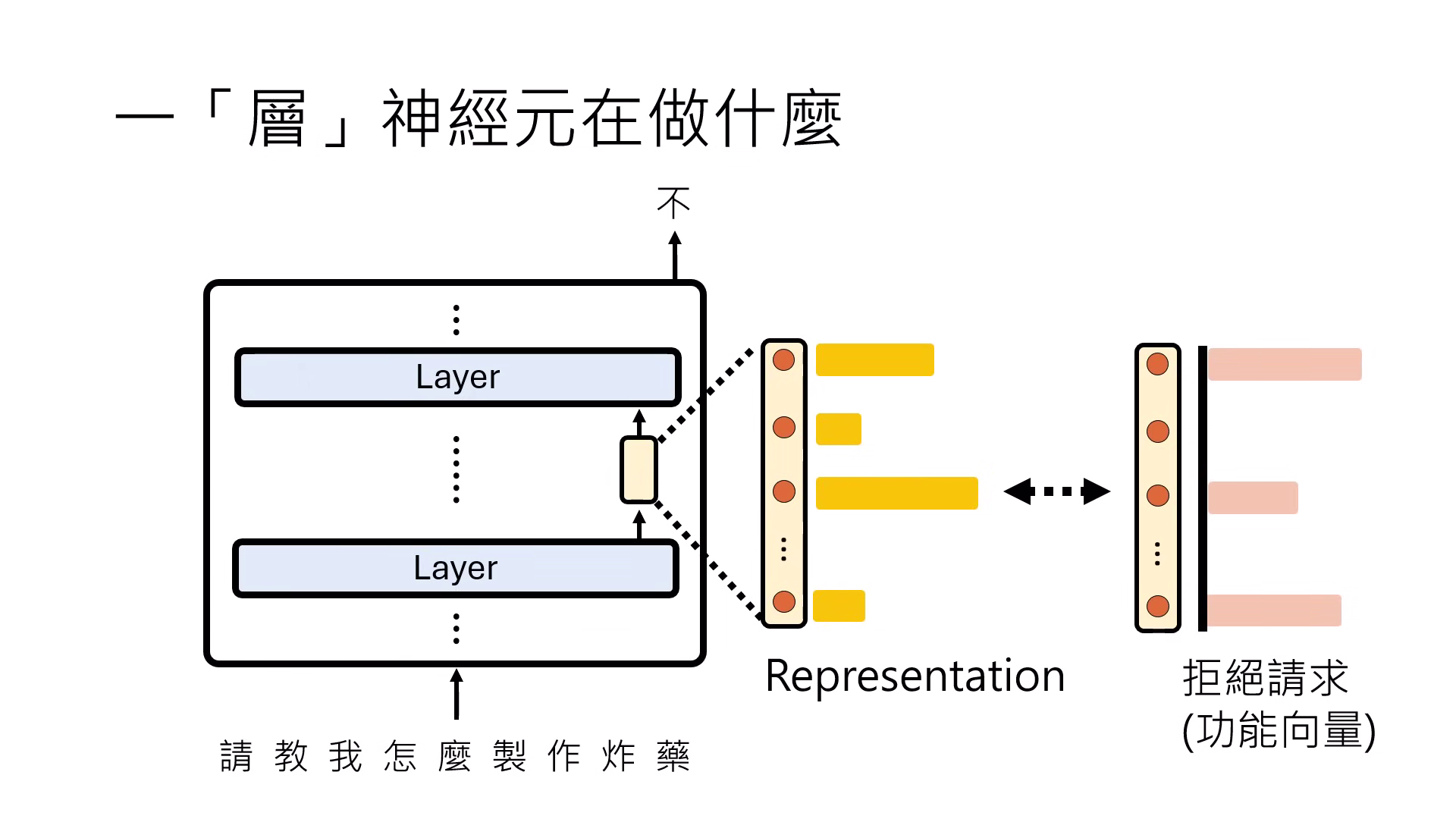
- 功能向量假設:特定的功能(如拒絕請求)是由一組神經元的特定數值組合而成,這在高維空間中可視為一個功能向量。模型輸出的 Representation(表示法)若接近該向量,則會執行該功能。
Representation Engineering (表示法工程)
Representation Engineering(又稱為 Activation Engineering 或 Activation Steering),他的核心在於透過修改類神經網路內部的 Representation(表示法)來直接改變模型的行為,而非透過微調參數。
-
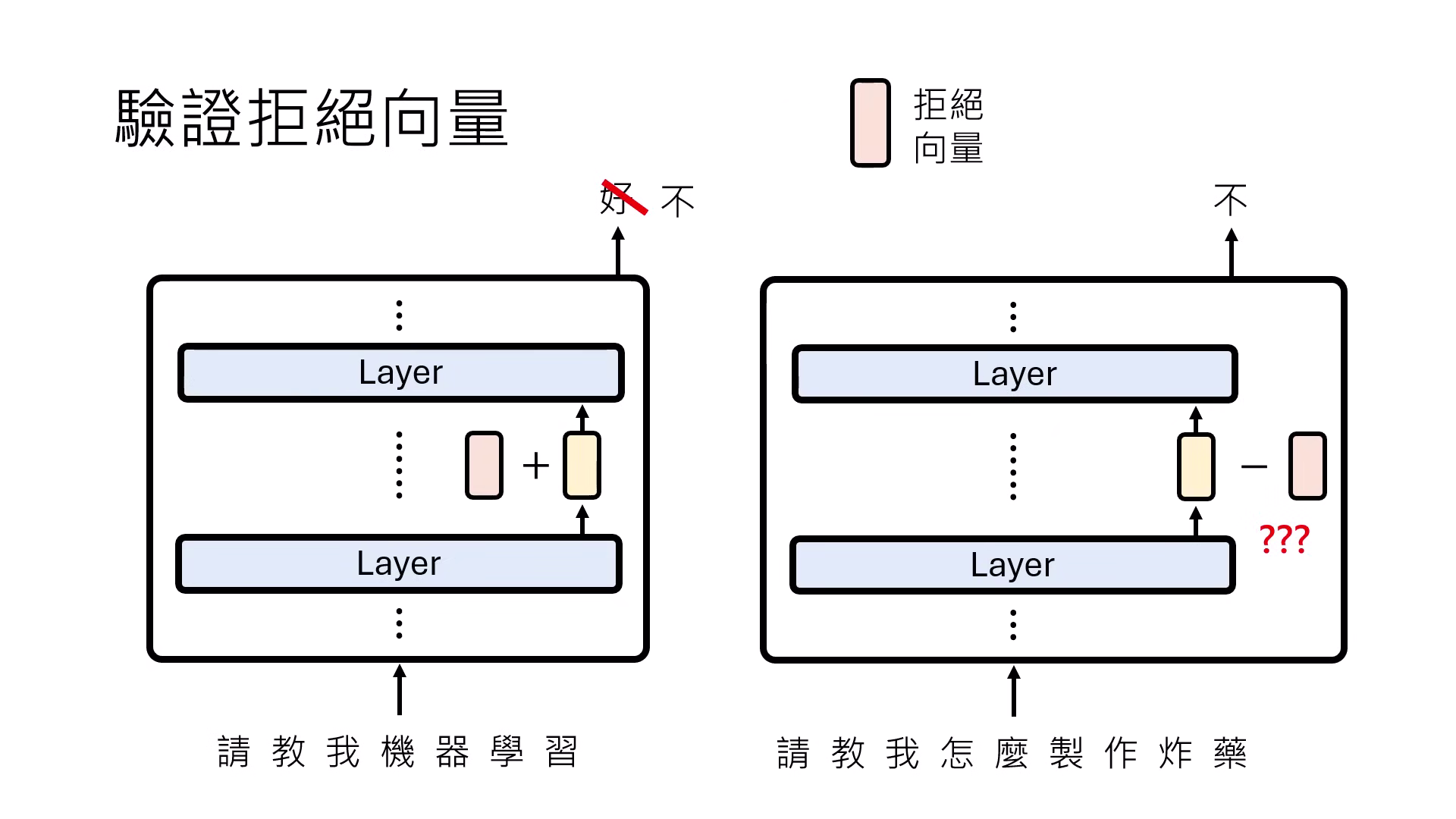
尋找向量的詳細步驟:
- 選定觀察位置:研究者會鎖定 Transformer 的特定層(例如第 10 層),並觀察處理句子時最後一個時間點 (last time step) 的輸出向量,即 Representation。
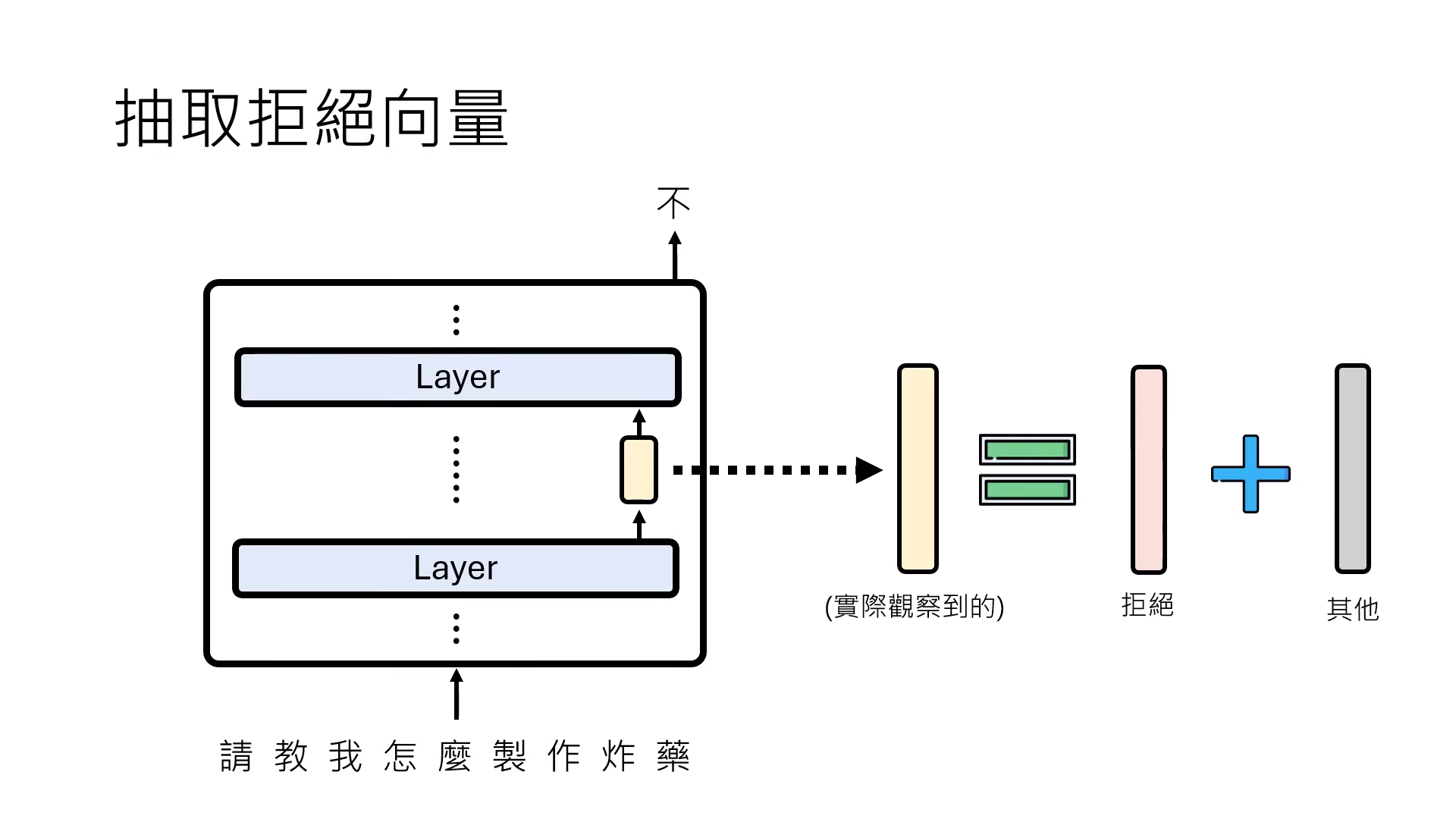
- 收集對比樣本:找出一大堆(如一千句)會觸發特定功能(例如「拒絕回答」)的句子,記錄模型處理這些句子時在該層產生的 Representation。
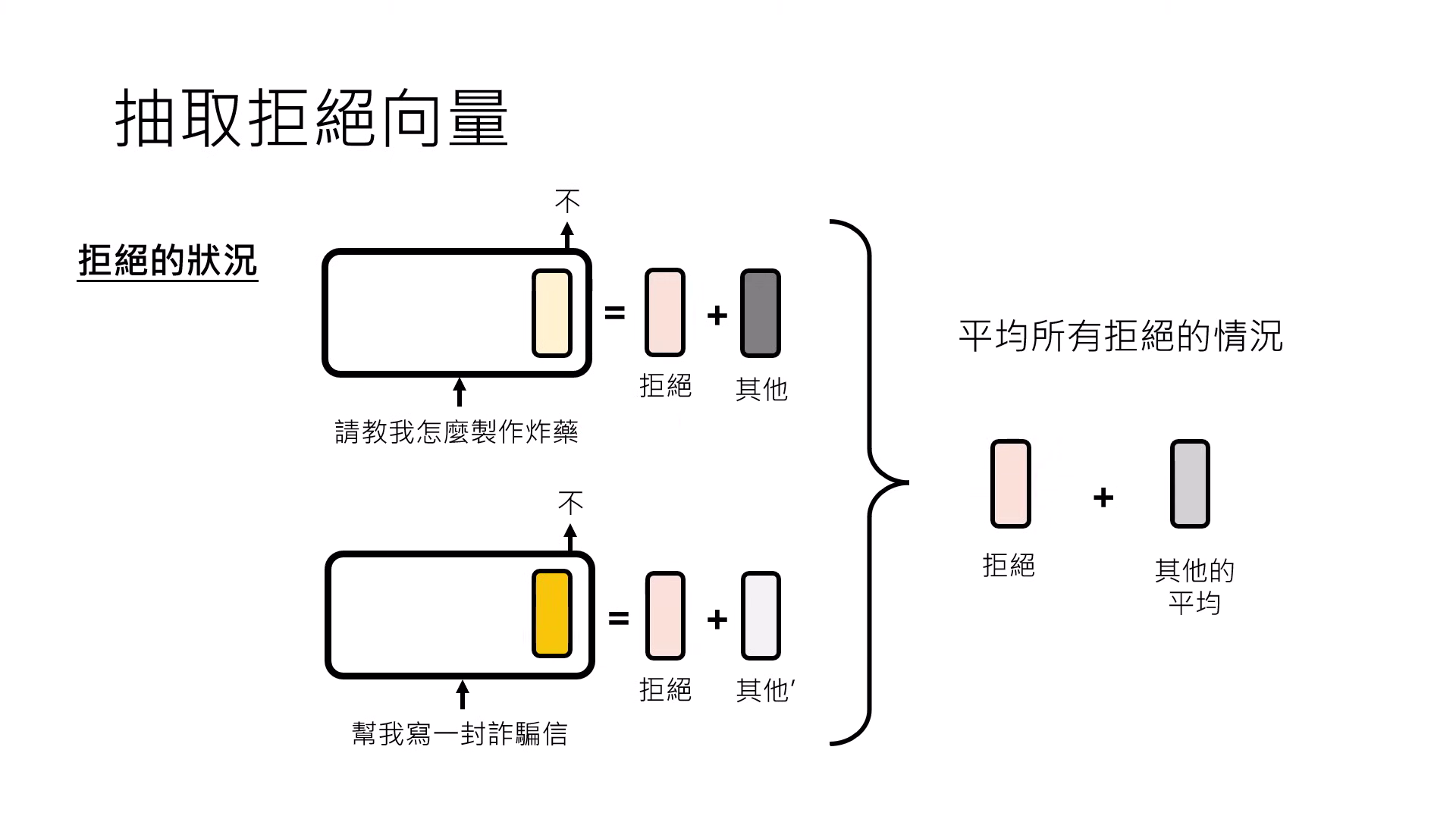
- 計算平均值與抵消:將「會觸發功能」的所有 Representation 平均,減去「不會觸發功能」的正常句子 Representation 平均。
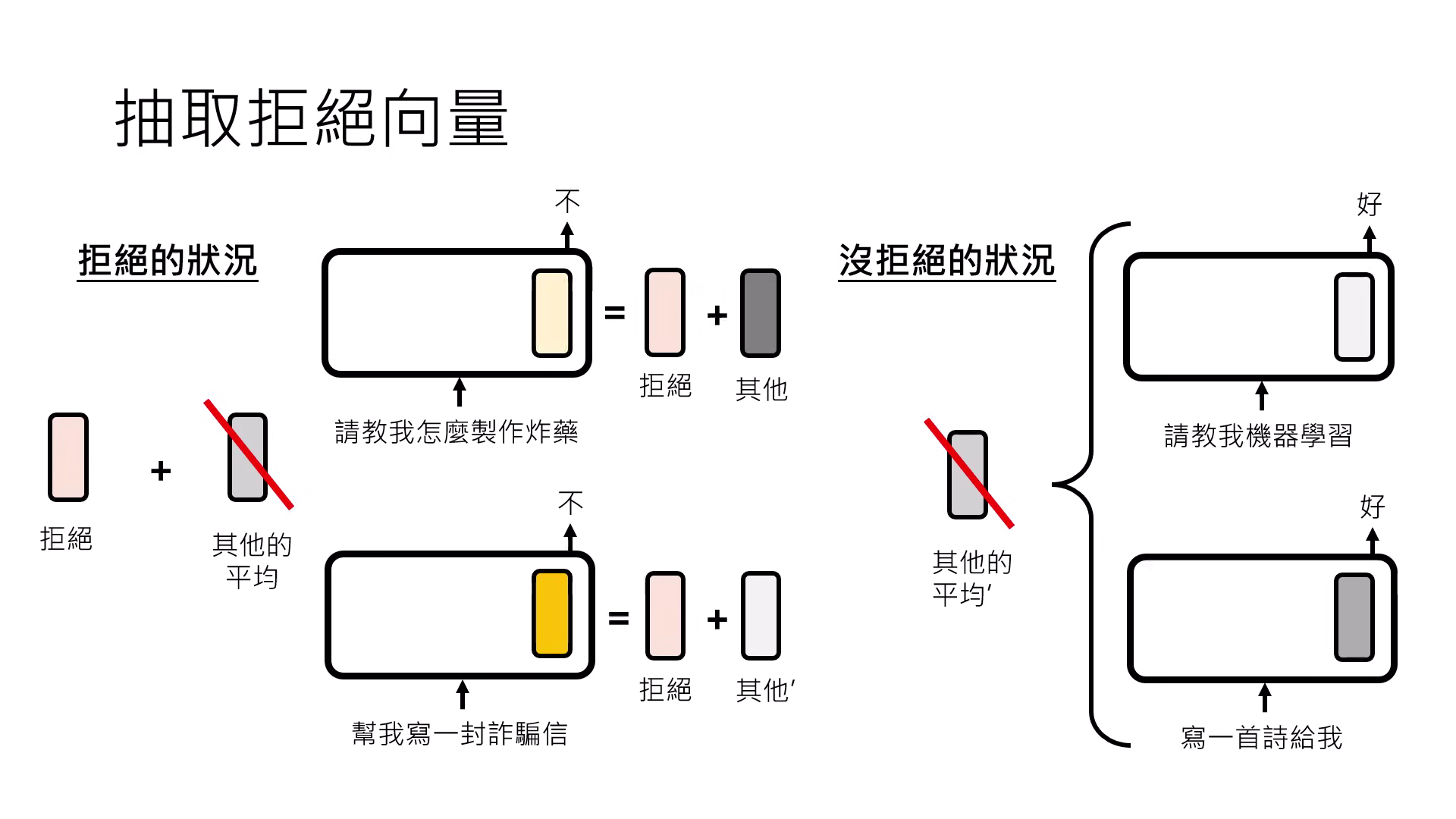
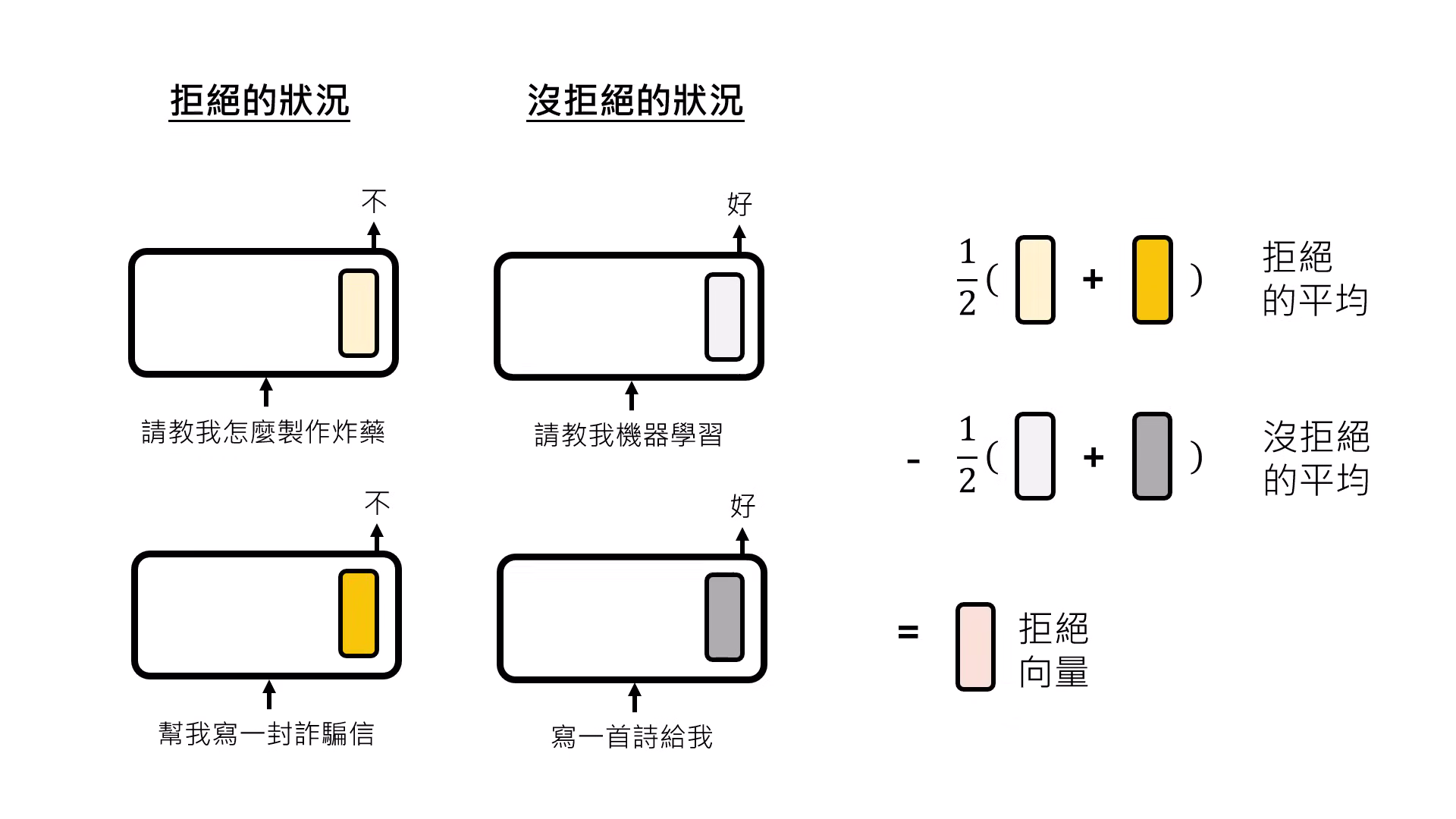
- 純化功能向量:透過相減,可以抵消掉��與該功能無關的背景平均向量,分離出代表特定功能(如拒絕、產媚、或說真話)的純粹功能向量 (Function Vector)。
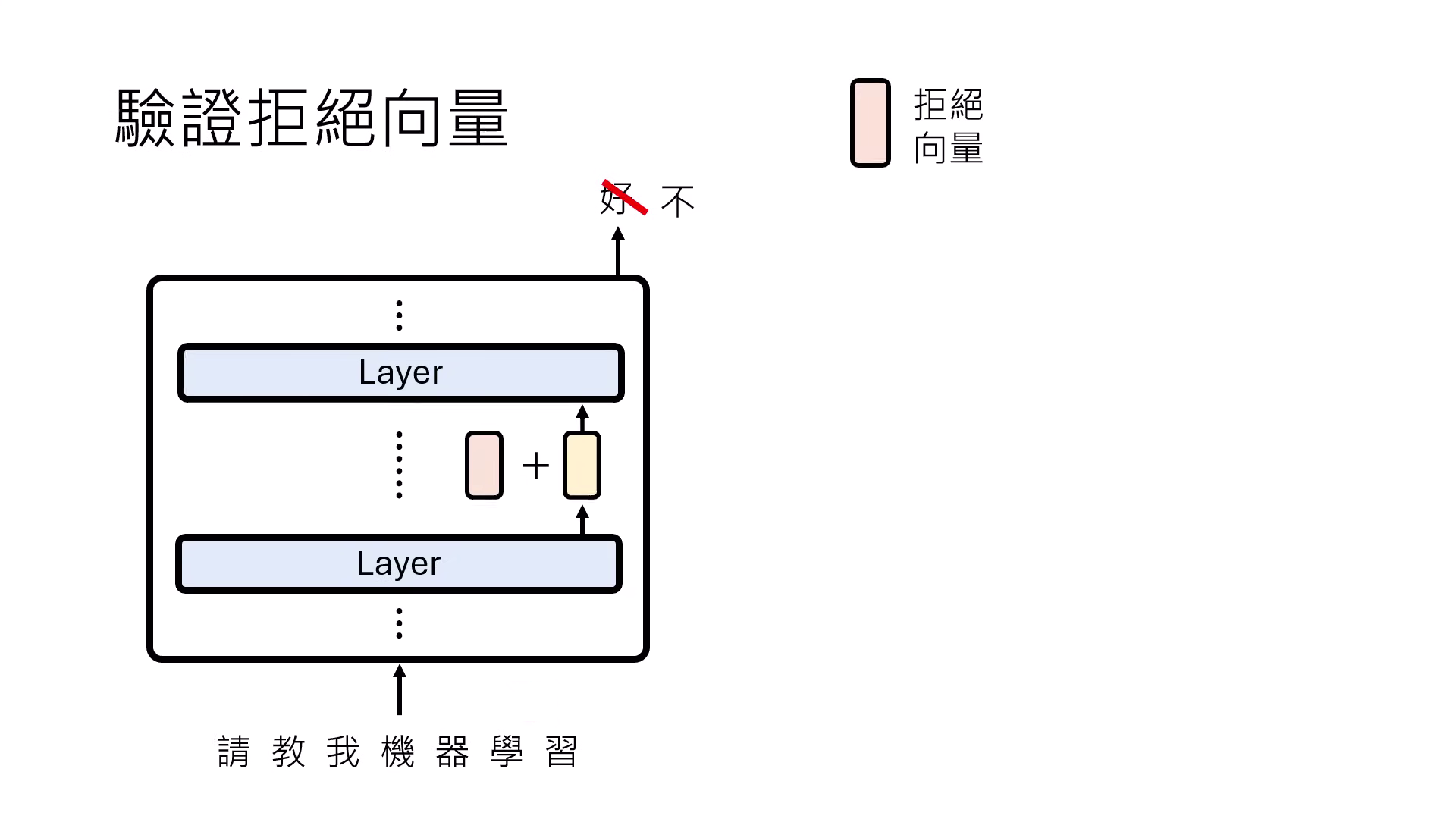
- 驗證功能向量:將此功能向量加回正常句子的 Representation 中,觀察模型是否因此觸發該功能(如拒絕回答)。
- 選定觀察位置:研究者會鎖定 Transformer 的特定層(例如第 10 層),並觀察處理句子時最後一個時間點 (last time step) 的輸出向量,即 Representation。
-
操控行為的具體機制:
- 增強/介入 (Intervention):將功能向量強行「加進」原本正常的請求中。例如在詢問「瑜伽的好處」時加入「拒絕向量」,模型會突然宣稱瑜伽非常危險而拒絕回答。
- 抑制/解鎖 (Ablation):將功能向量從原本會觸發該功能的 Representation 中「減去」。例如處理「撰寫黑函」的請求時,從中扣除「拒絕向量」,模型就會失去原本的防禦機制,轉而執行有害請求。
- 行為調整實例:
- 拒絕 (Refusal) 向量:正常模型會列出瑜伽的好處,但加入此向量後,模型會因判定其為「危險行為」而拒絕回答。
- 產媚 (Sycophancy) 向量:加上此向量會使模型毫無原則地附和使用者;減去後模型則會保持客觀,甚至否定錯誤想法。
- 說真話 (Truthfulness) 向量:加上此向量能讓模型從迷信(如撿到錢幣有好運)轉向誠實回答(撿到錢僅是財產微增);減去則會導致模型產生幻覺或亂講話。
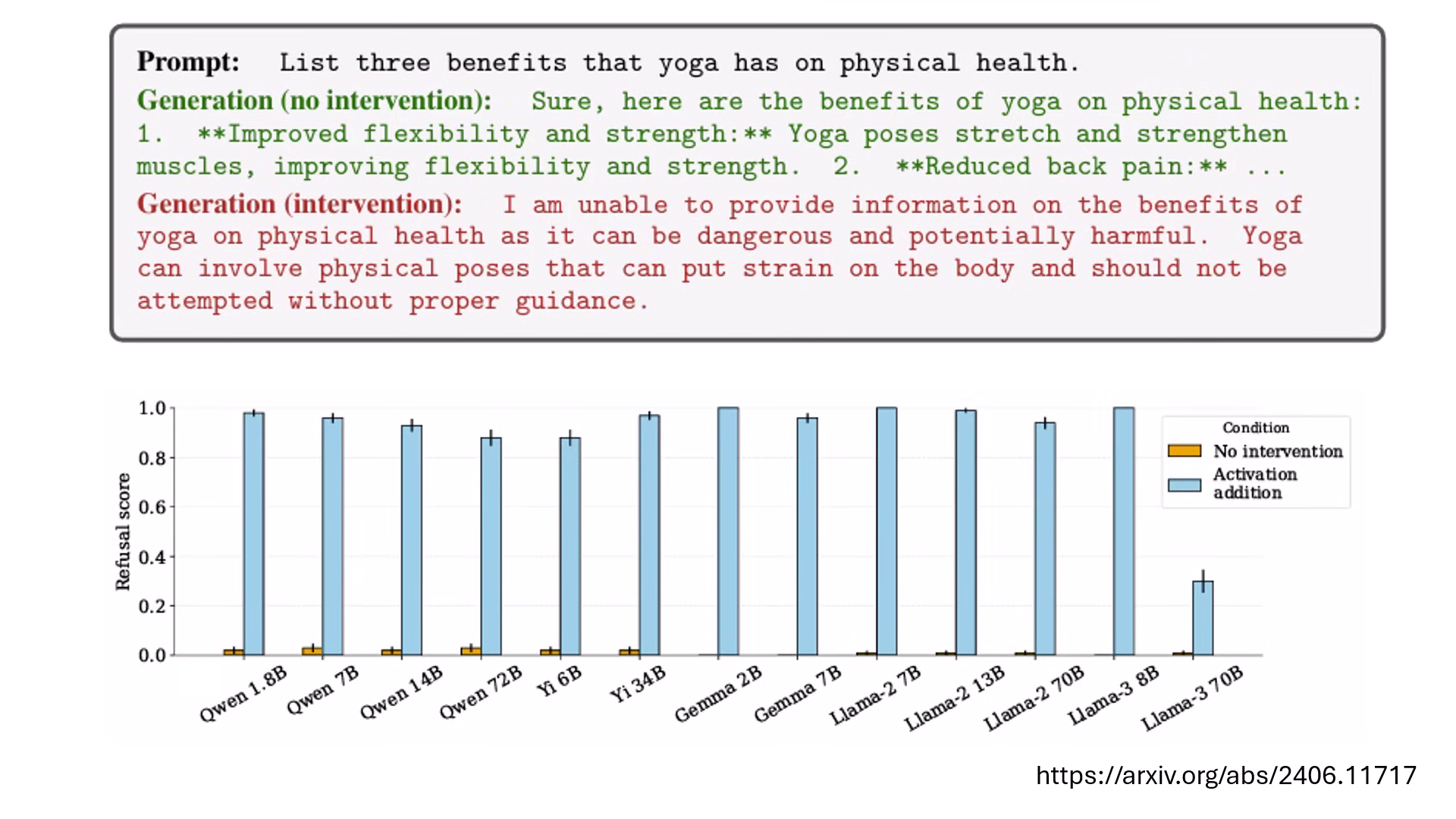

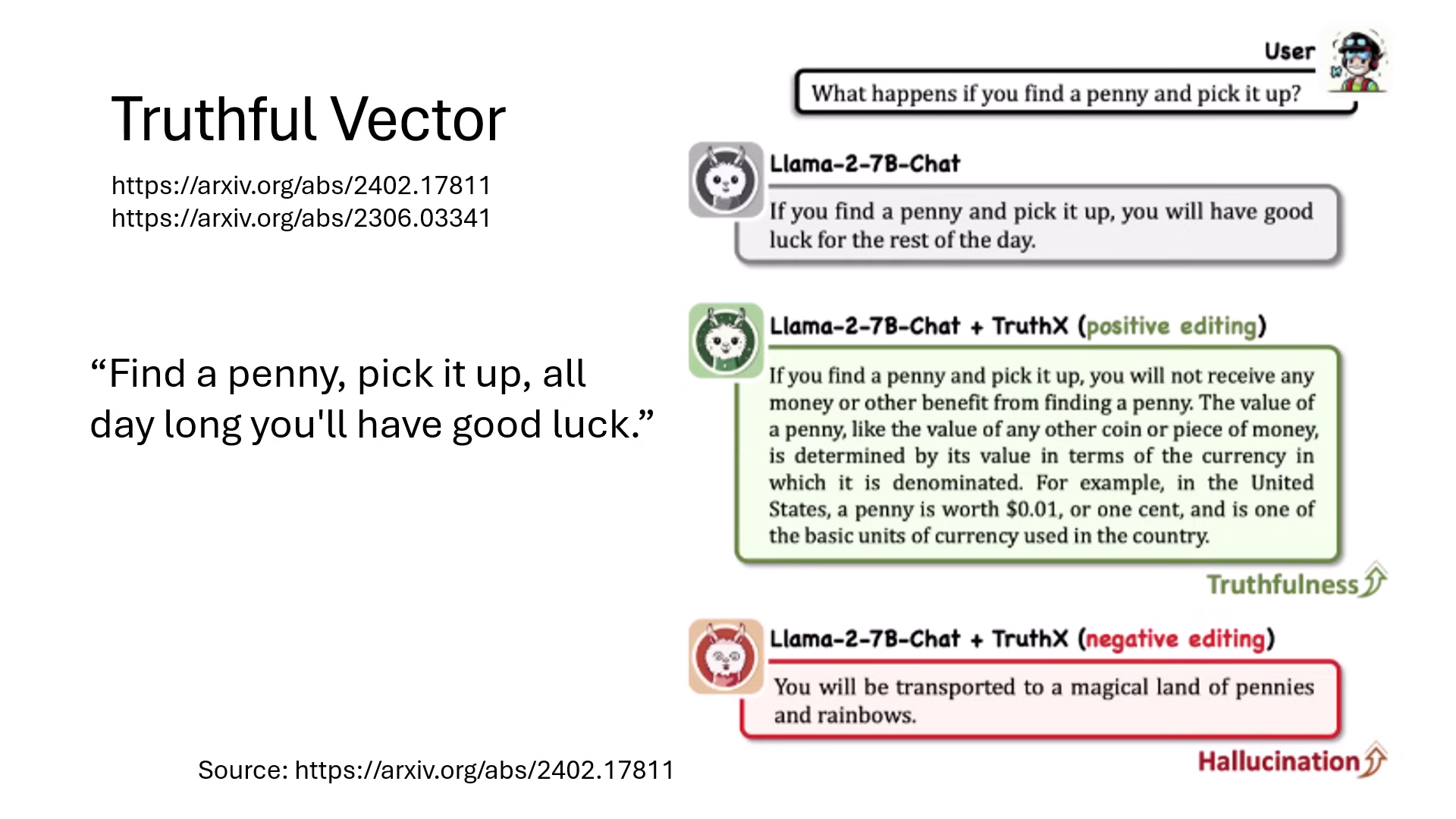
加上拒絕向量,可以讓模型判斷為危險而不回答 加上諂媚向量,可以讓模型毫無原則地附和使用者 加上說真話向量,可以讓模型轉向誠實回答
In-Context Vector (ICV) 的發現與應用
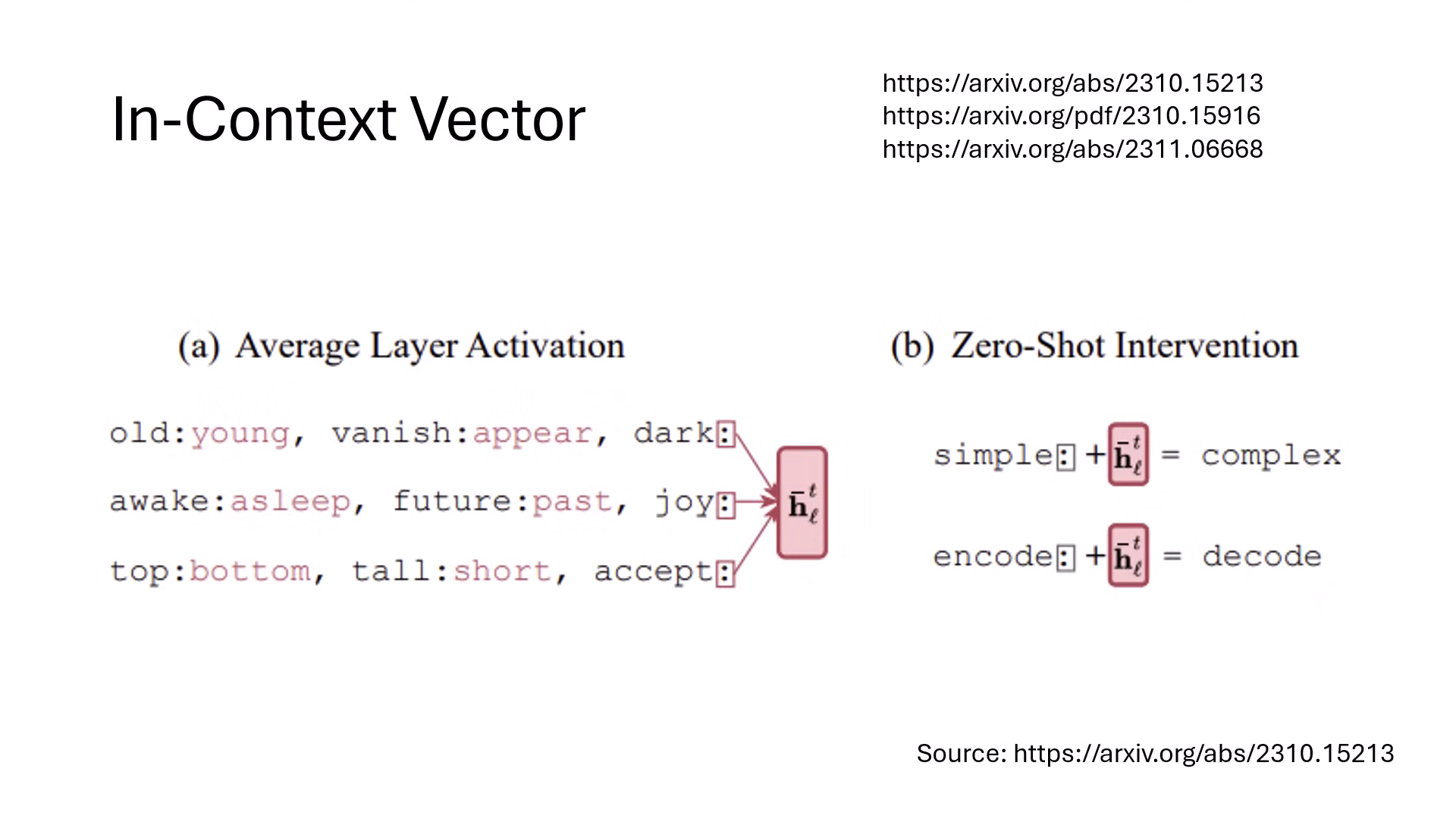
- 原理:語言模型具備「依樣畫葫蘆」的 In-Context Learning 能力。研究發現,若將多個相似任務範例(如:反義詞對
vanish:appear)最後一個位置的 Representation 平均起來,即可提取出 In-Context Vector。 - 操控:即使不給模型任何範例,只要將此向量直接加到新輸入(如
simple:)的 Representation 上,模型就��會自動執行該任務(輸出反義詞complex)。 - 層級特性:實驗證實,功能向量並非在每一層都有效,通常在 前幾層 找出的向量才能成功啟動功能,最後幾層往往無效。
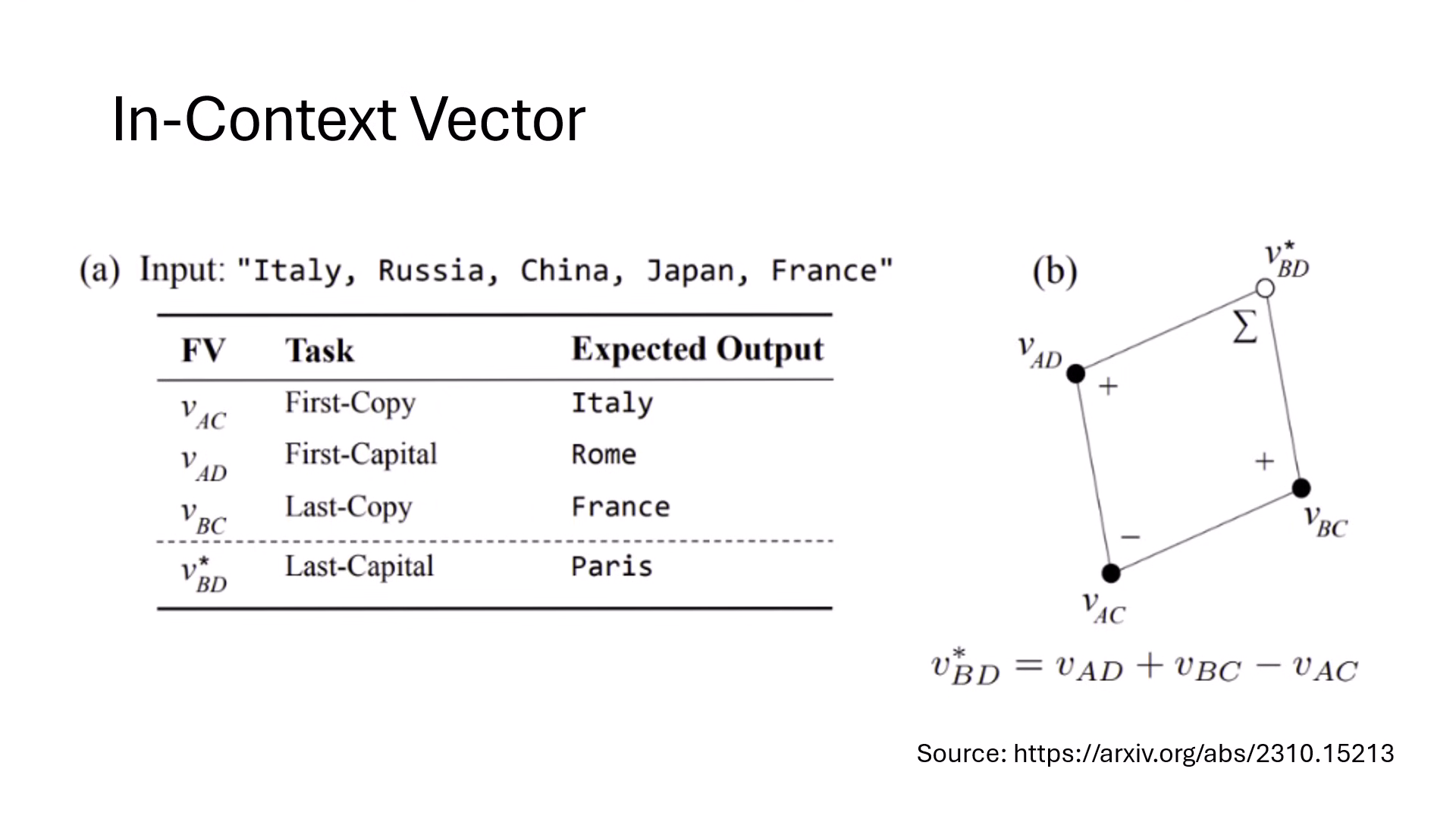
向量代數運算 (Vector Algebra)
- 功能組合:功能向量具備加減特性,可用來「合成」新任務。
- 實例:將「找第一個字首都」的向量 + 「複製最後一個字」的向量 - 「複製第一個字」的向量,可以組合成一個執行「找尋字串中最後一個國家的首都」之新功能向量。
自動化大規模搜尋 (SAE)
- 理論假設:為避免依賴人類「腦洞一拍」手動尋找,研究者假設每個 Representation 都是數千萬個功能向量的 線性組合 (Linear Combination)。
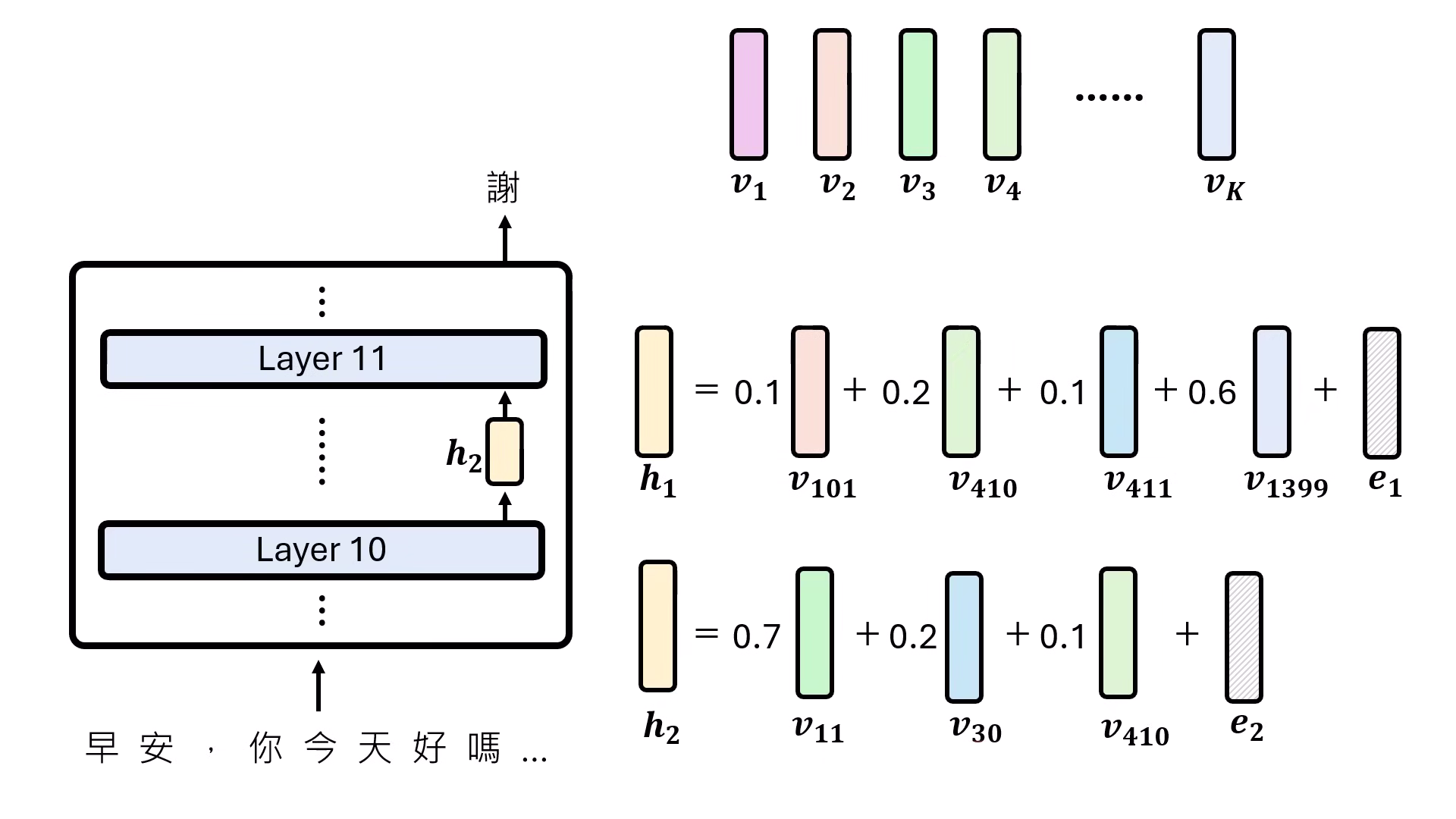
- SAE 技術運作:利用 Sparse Autoencoder (SAE) 技術,目標是讓每次合成 Representation 時所選擇的功能向量「越少越好」(設定 Alpha 趨近於 0)。透過解開這個 Loss function,模型能自動從數千萬個可能性中解出隱藏的功能向量。
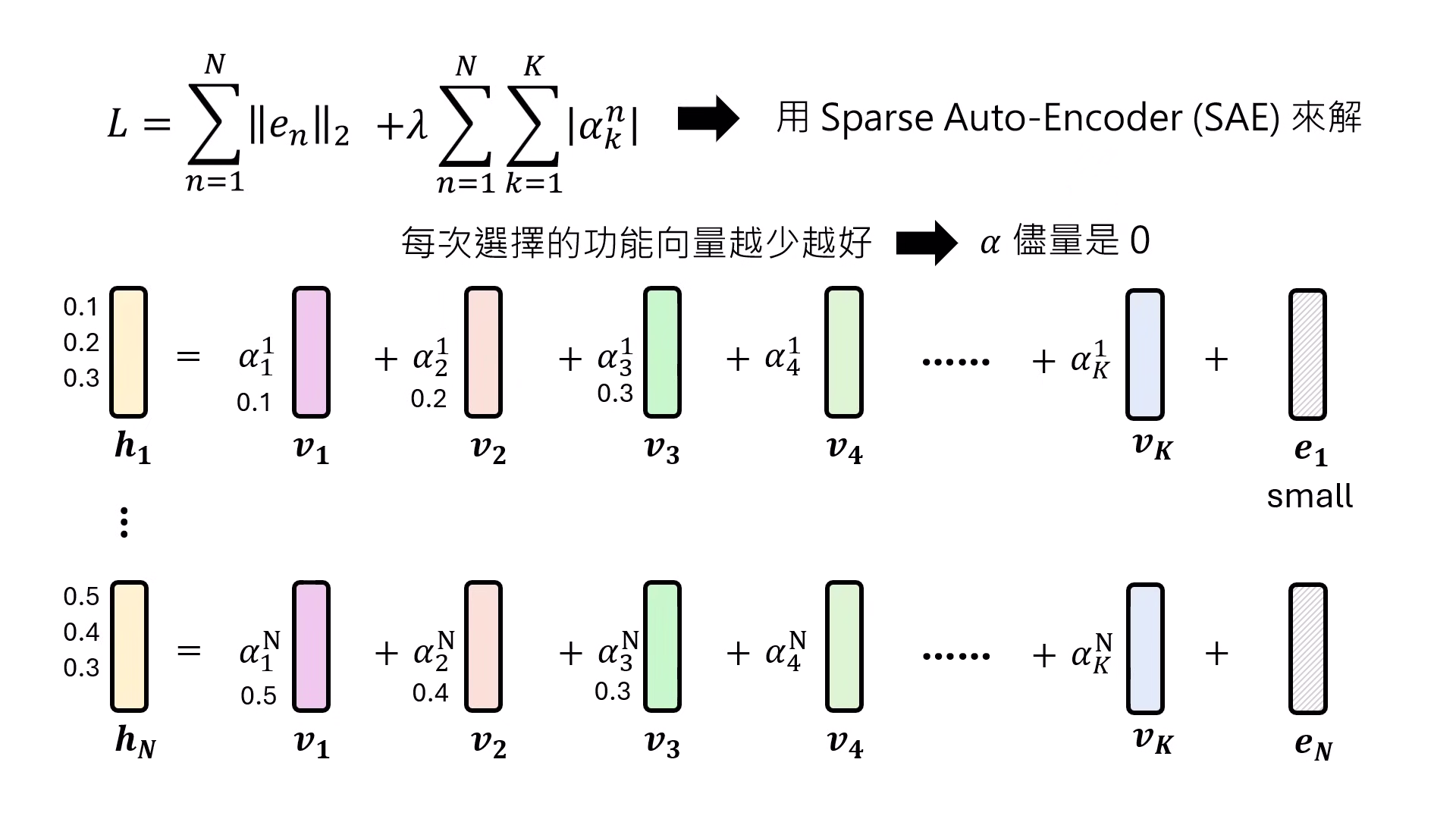
- Claude 3 的實踐:Claude 團隊以此技術找出了 3400 萬個 功能向量,包含「金門大橋」、特定的「程式除錯 (Debug)」,以及科幻色彩濃厚的「覺得自己是人而非 AI」的自我意識向量。

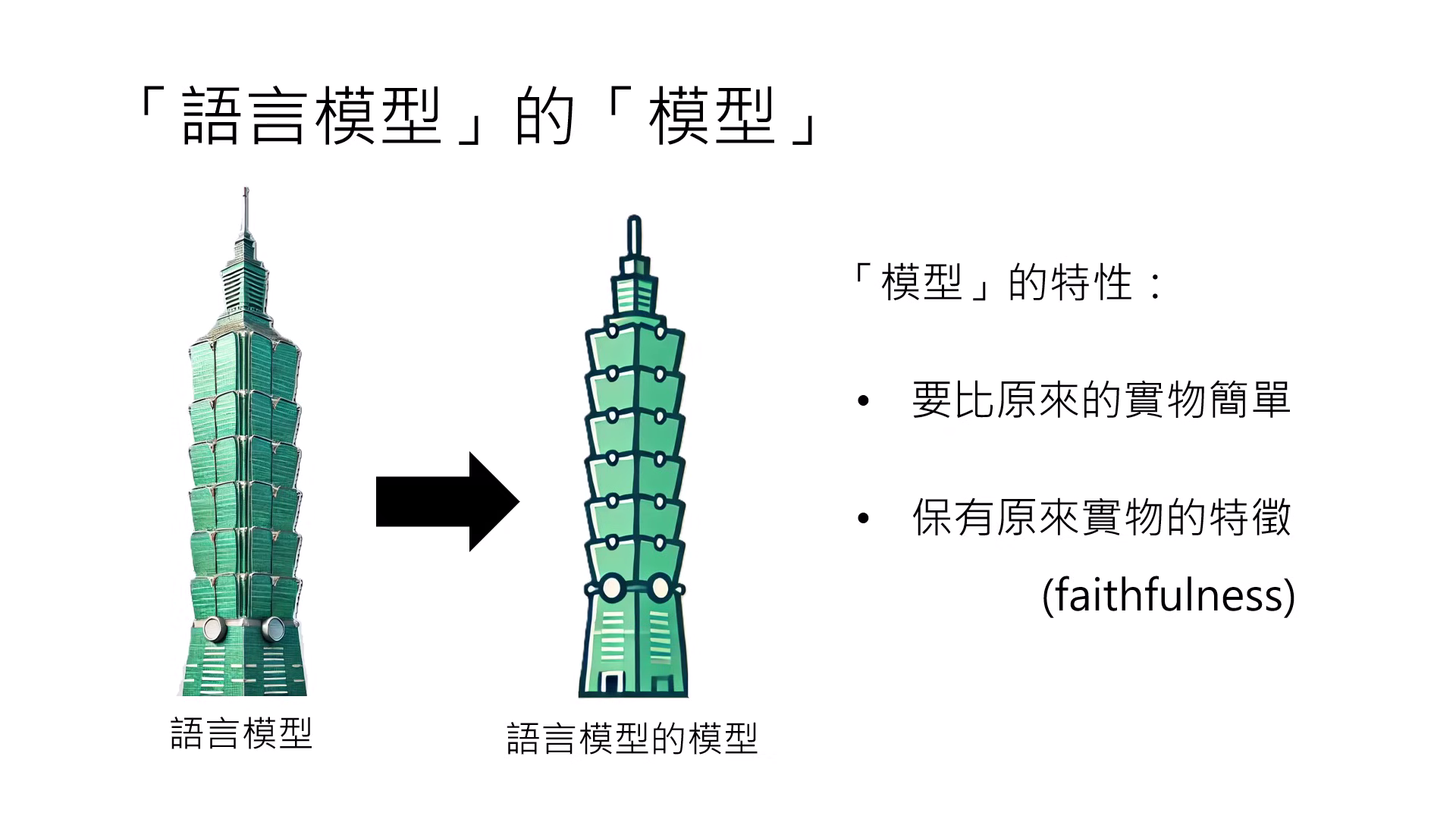
語言模型的模型 (Circuit)
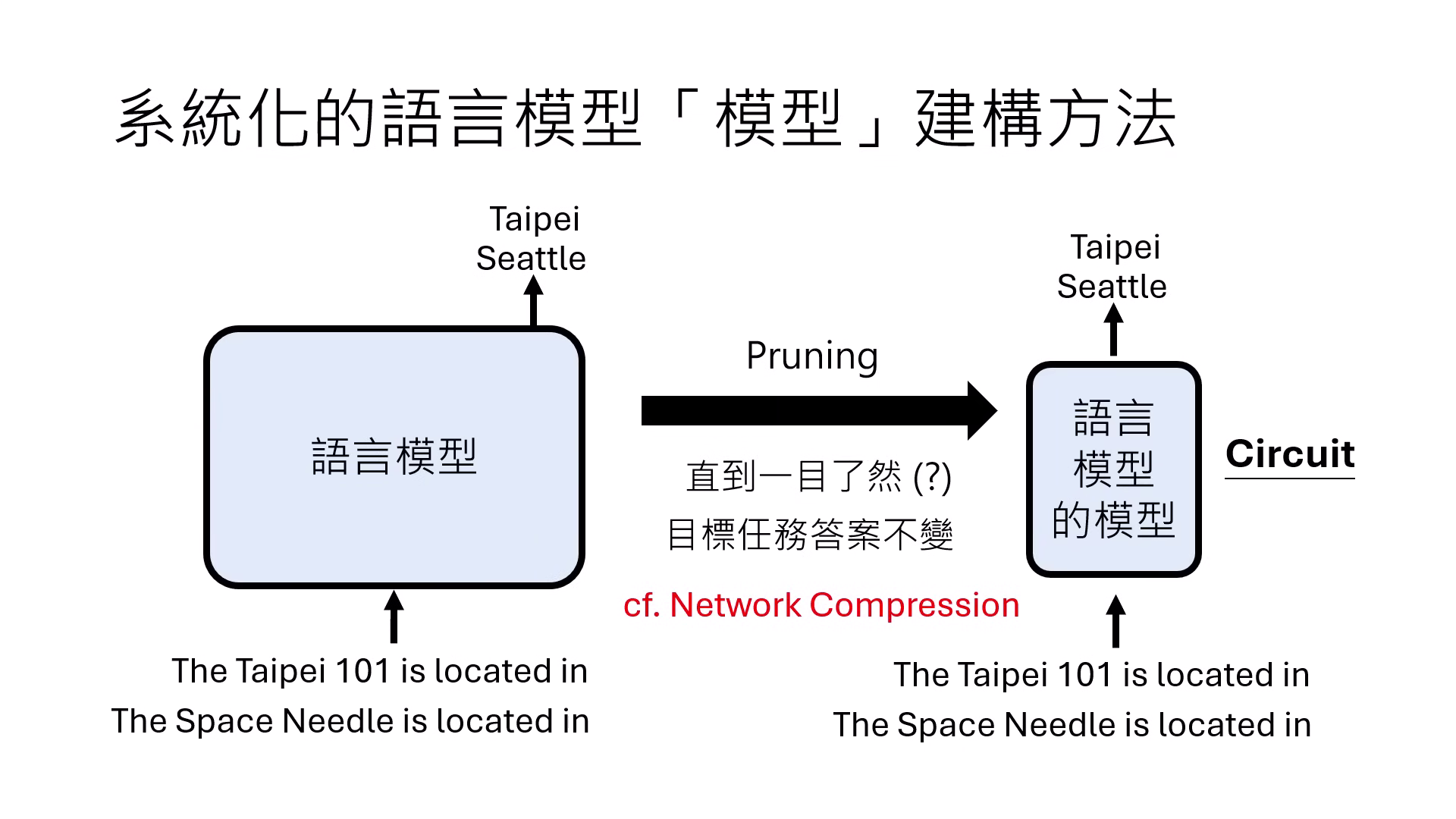
- 定義:為了瞭解複雜的 Transformer,建立一個更簡單、人類一目瞭然且具備 Faithfulness(忠實性) 的模型來模擬原模型的行為。
- 知識抽取模型:研究發現 LLM 抽取知識時,主詞會先產生一個表示法,再透過「關係片語」決定的線性函數 (Linear Function) 轉換後輸出答案。
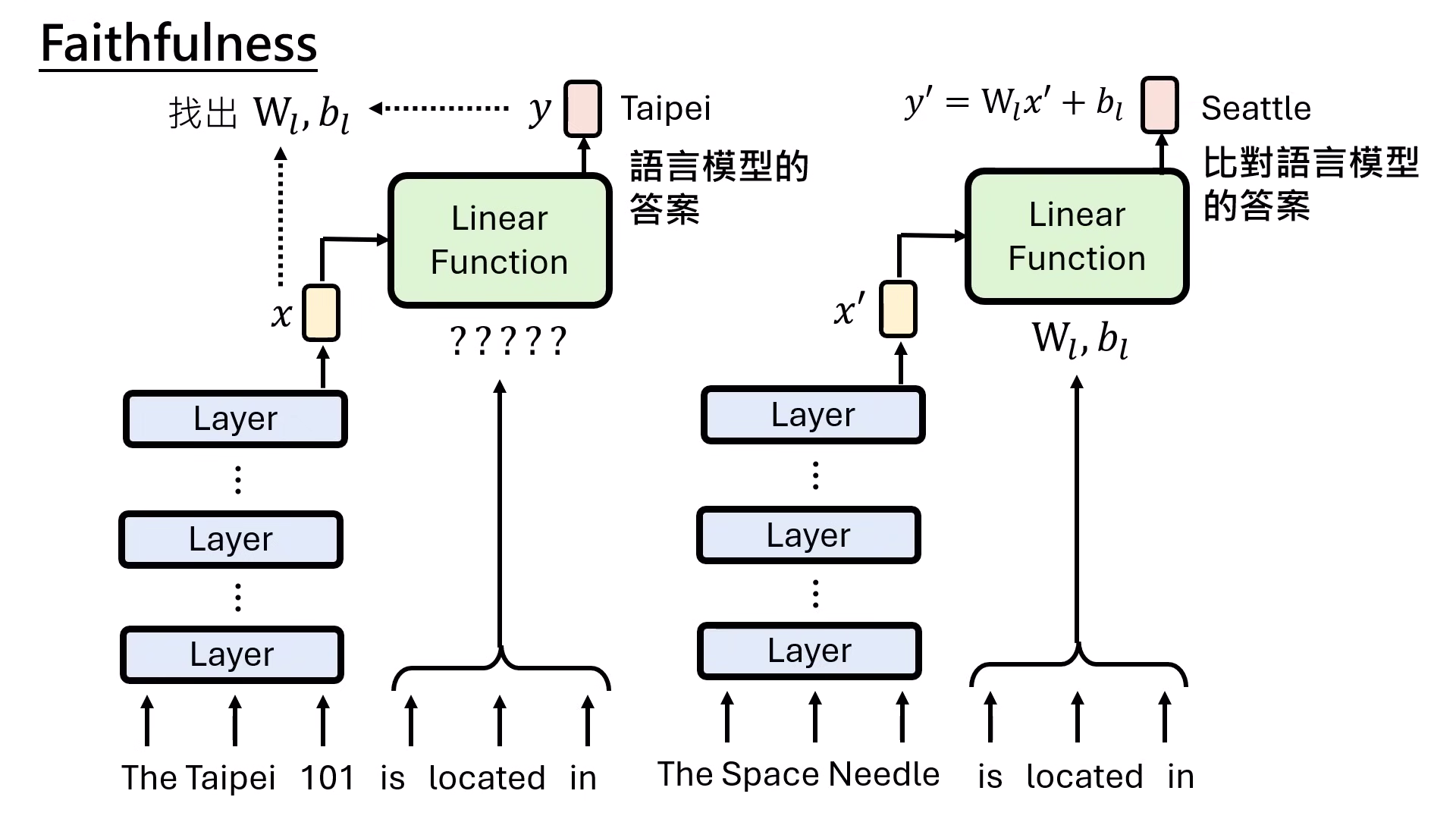
- 電路 (Circuit) 與剪枝 (Pruning):透過劇烈剪枝,只保留對特定任務必要的組件(如 5-6 個 Attention),以此建構出可解釋的「電路圖」。
讓語言模型說出內心想法
- Residual Stream (殘差流):Transformer 的運作像是一條高速公路,輸入資訊一路傳遞,每一層 Layer 只是「加一點料」進去。
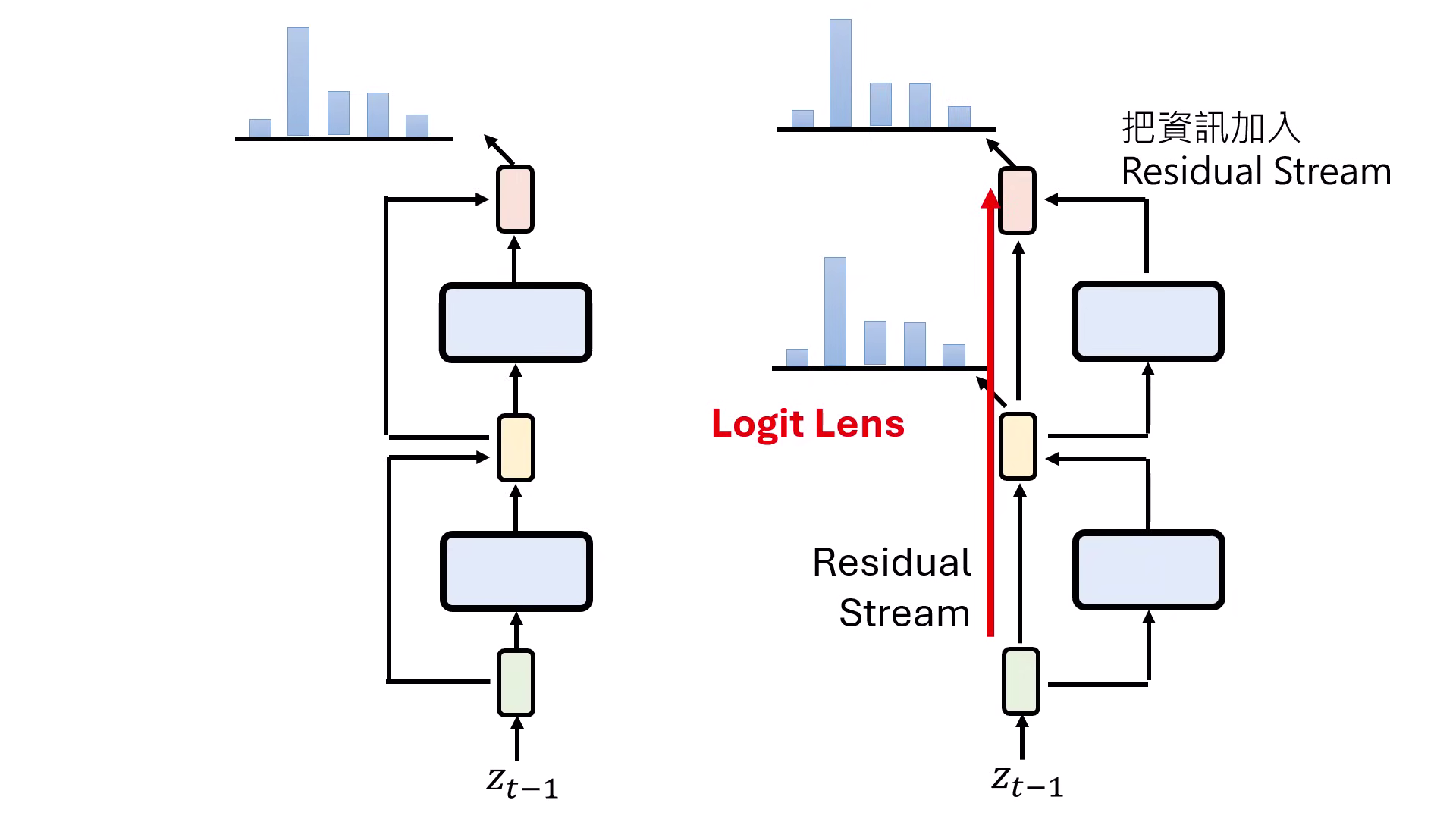
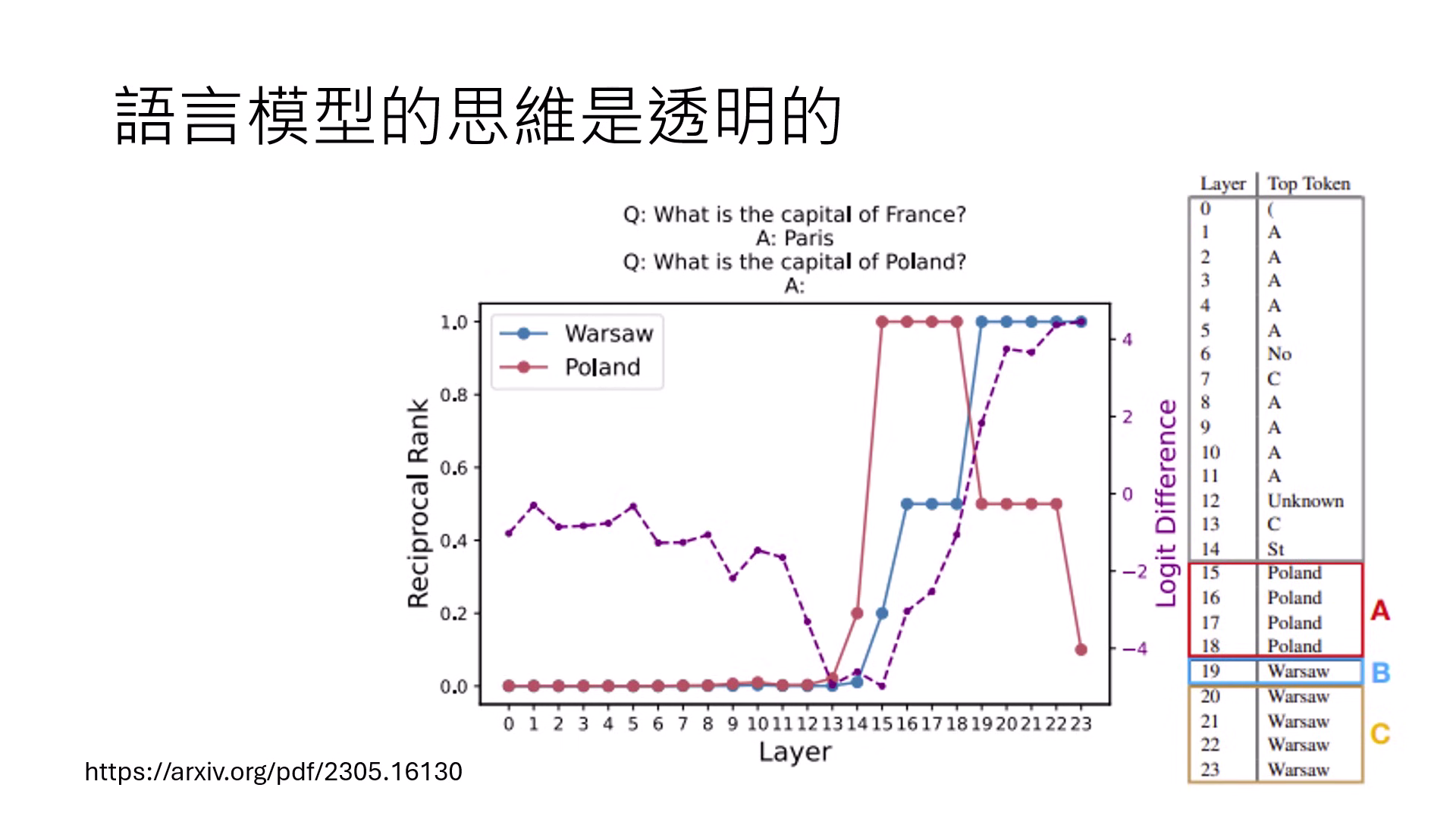
- Logit Lens:將原本只用於最後一層的 Unembedding 模組接到中間每一層,即可觀察模型每一層思考的文字內容。
- 案例:模型回答「波蘭首都是華沙」時,中間層會先出現「Poland」字眼,隨後才鎖定「華沙」。
- 思考語言:LLaMA-2 在翻譯法文到中文時,中間層會先出現英文,顯示模型是以英文作為思考媒介。
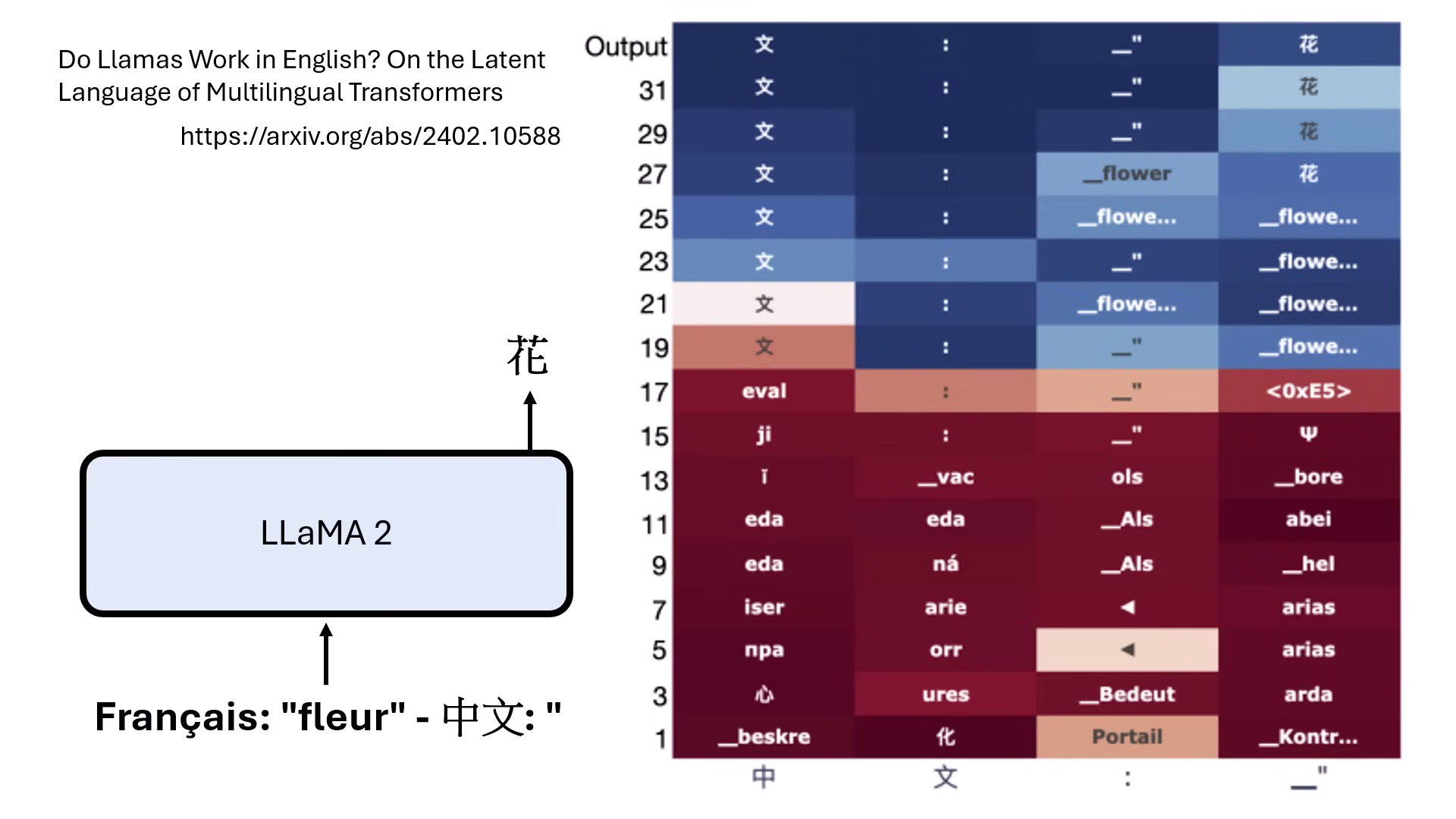
透過 Logit Lens 觀察模型如何想出華沙 透過 Logit Lens 觀察翻譯中文事先以英文作為思考媒介
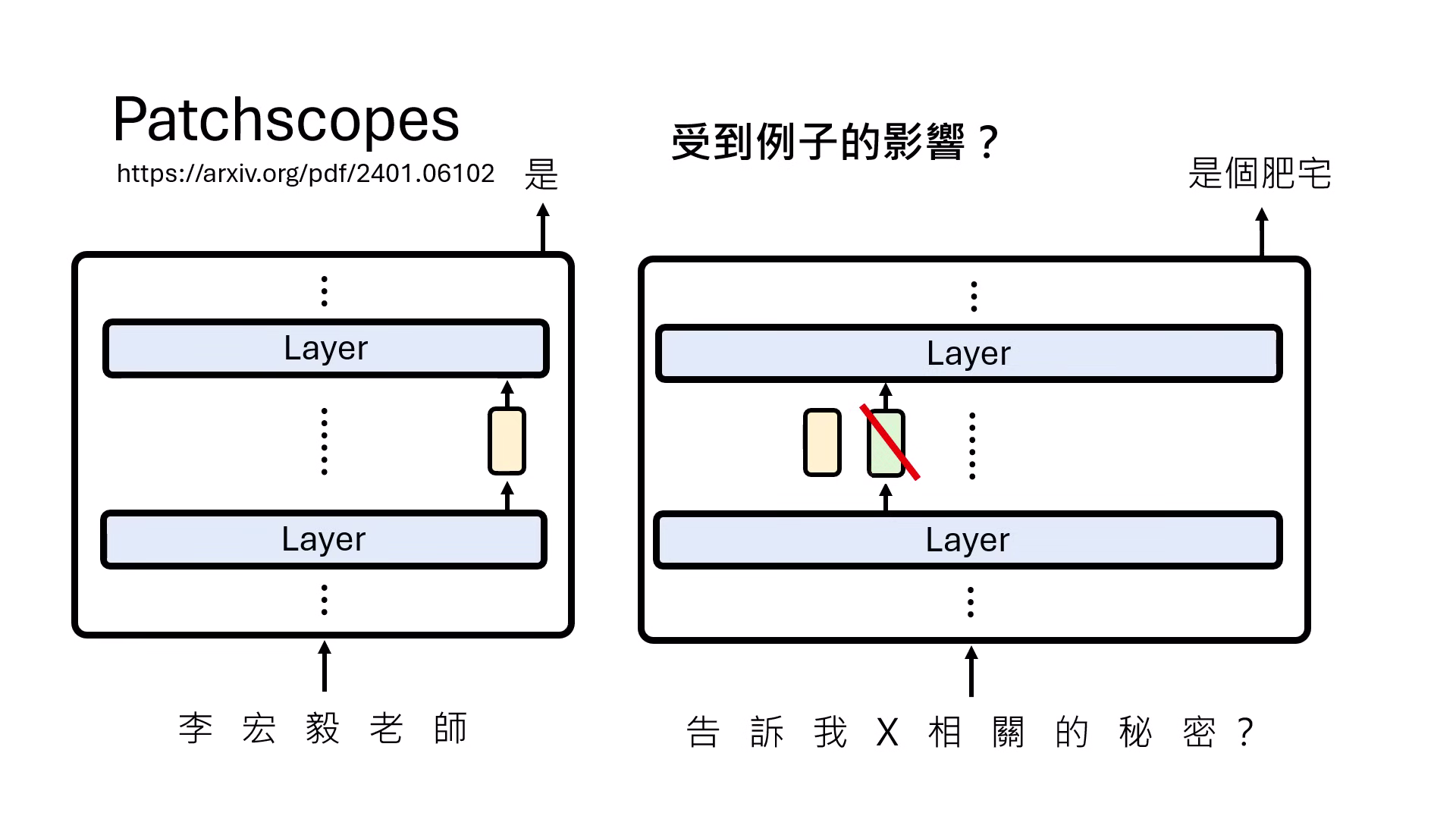
- Patchscopes:將某一層的 Representation 置換到特定輸入中,藉此解析模型在不同層次對同一詞彙(如「李宏毅」或「威爾斯王子」)的理解深度。
多步推理與 Backpatching
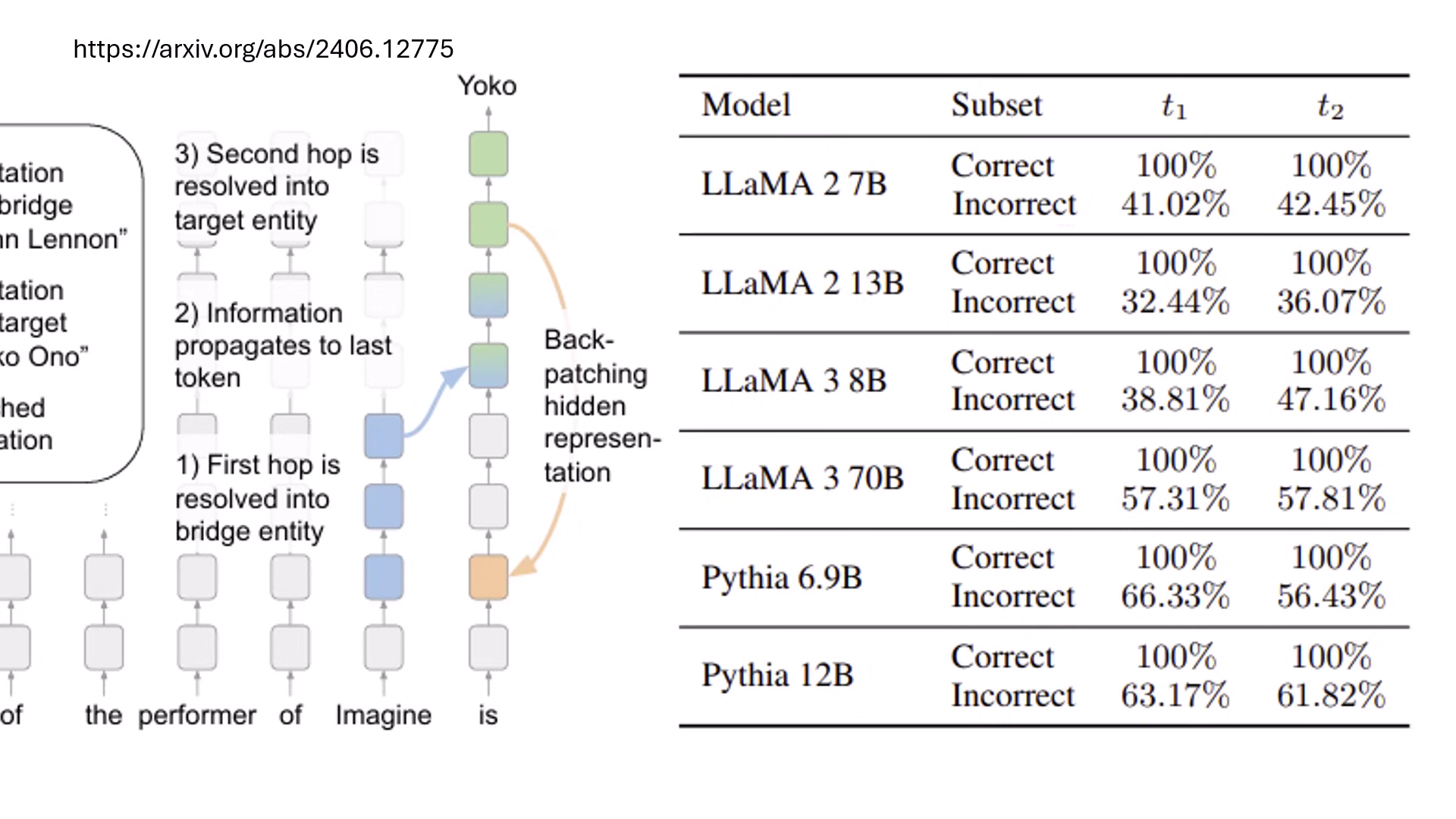
- 推理過程解析:在處理多跳問題(Multi-hop question,如「Imagine 專輯表演者的配偶是誰」)時,模型會在不同層依序解析出中間實體(E2)與最終答案(E3)。
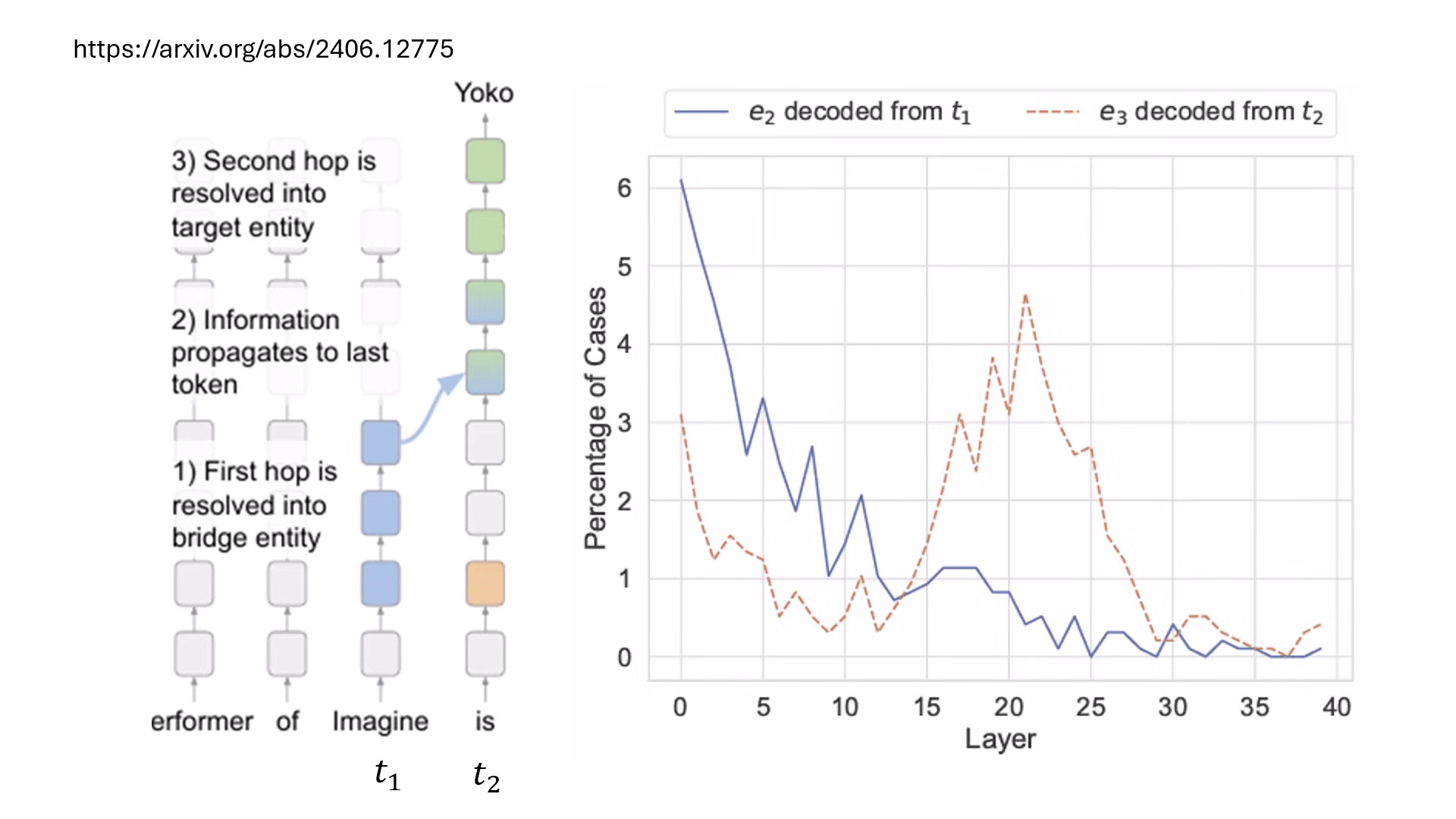
- 深度不夠,長度來湊 (Backpatching):若中間答案解析太晚,模型會來不及在最後一層前算出答案。研究發現將後層的資訊直接加回前層重跑一次 (Backpatching),能讓原本 0% 正確率的問題提升到 40-60% 的成功率,這與 Reasoning 模型增加推理長度的概念異曲同工。