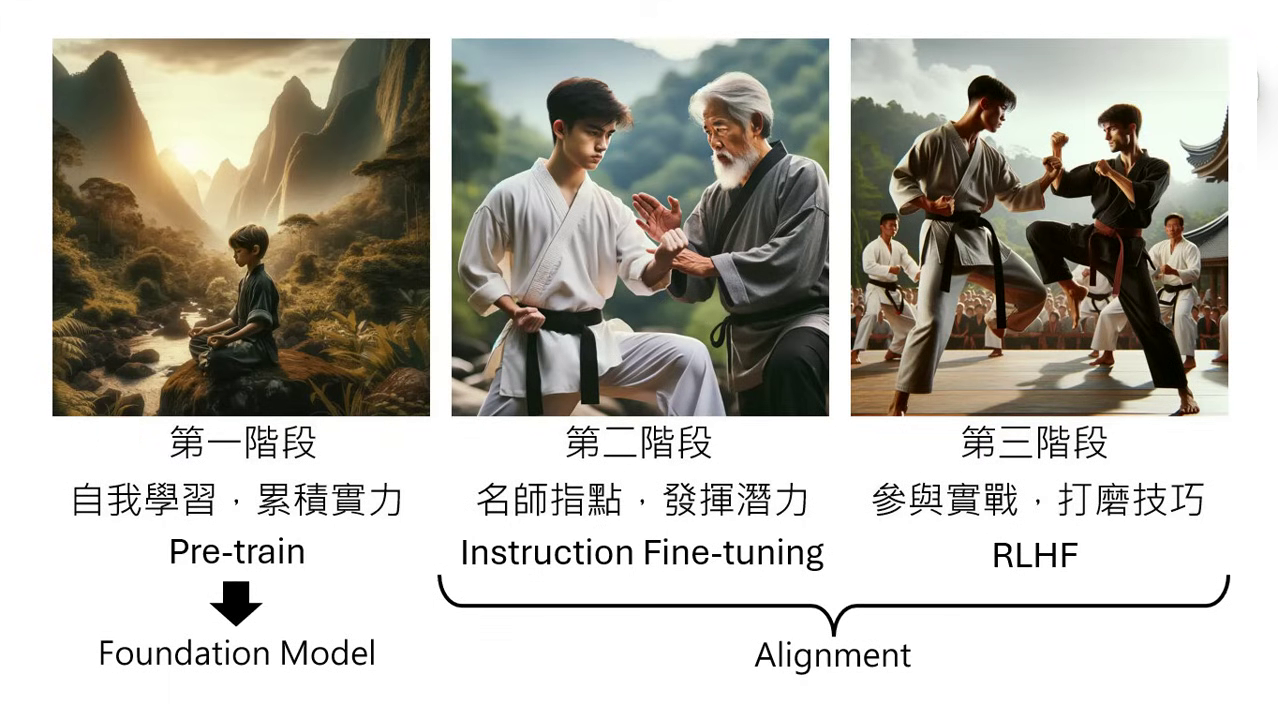
大型語言模型修練史 — 第三階段:參與實戰,打磨技巧
在第二階段,模型透過人類老師的指點學會了「招式」(回答問題的方法),但其生成的內容仍未必能完全符合人類的偏好或多元的價值判斷,因此需要進入第三階段:參與實戰,打磨技巧 (Reinforcement Learning from Human Feedback, RLHF)。

RLHF 的基本機制
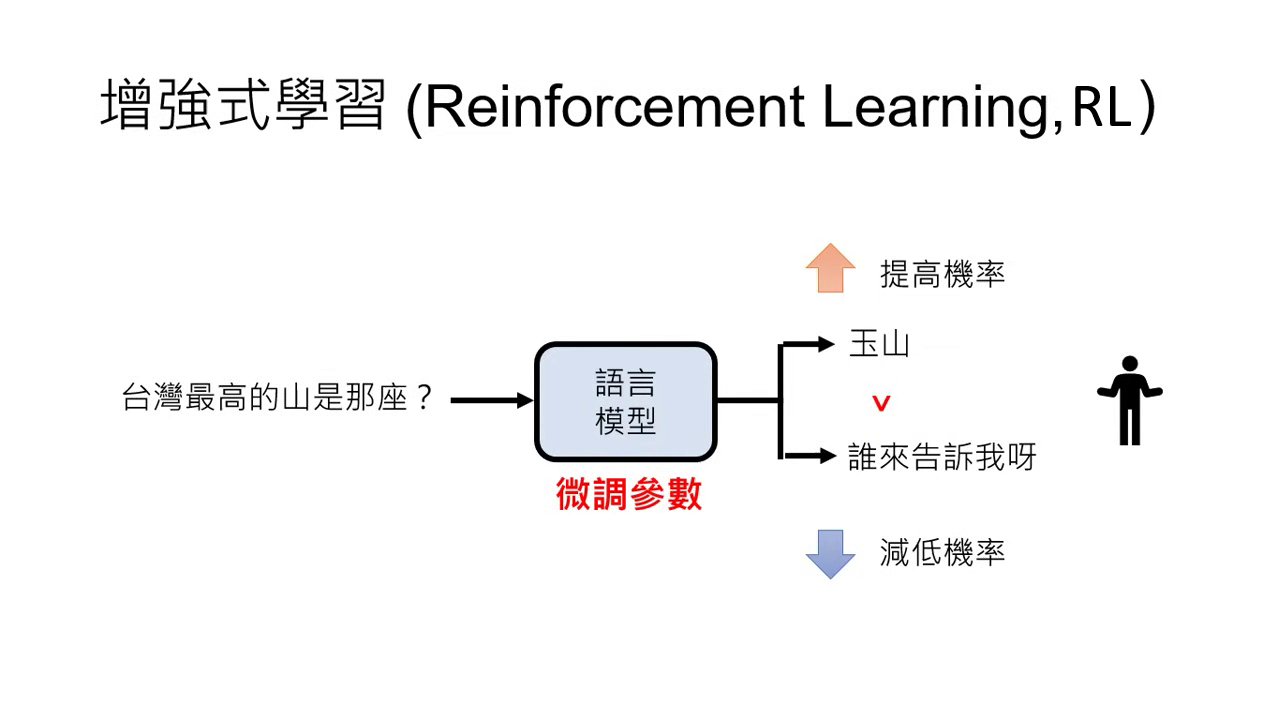
- 核心定義:透過人類的回饋資訊來進行學習的方法,稱為增強式學習 (Reinforcement Learning, RL)。
- 學習訊號:不同於前兩個階段的文字接龍,RLHF 沒有明確告知下一個 Token 是什麼,而是由模型產生多個答案,讓人判定哪一個比較好。
- 運作原則:人覺得好的答案,就提高產生該答案的機率;人覺得不好的答案,就降低其機率。
- 微調演算法:ChatGPT 在此階段使用的主要演算法稱為 PPO (Proximal Policy Optimization)。
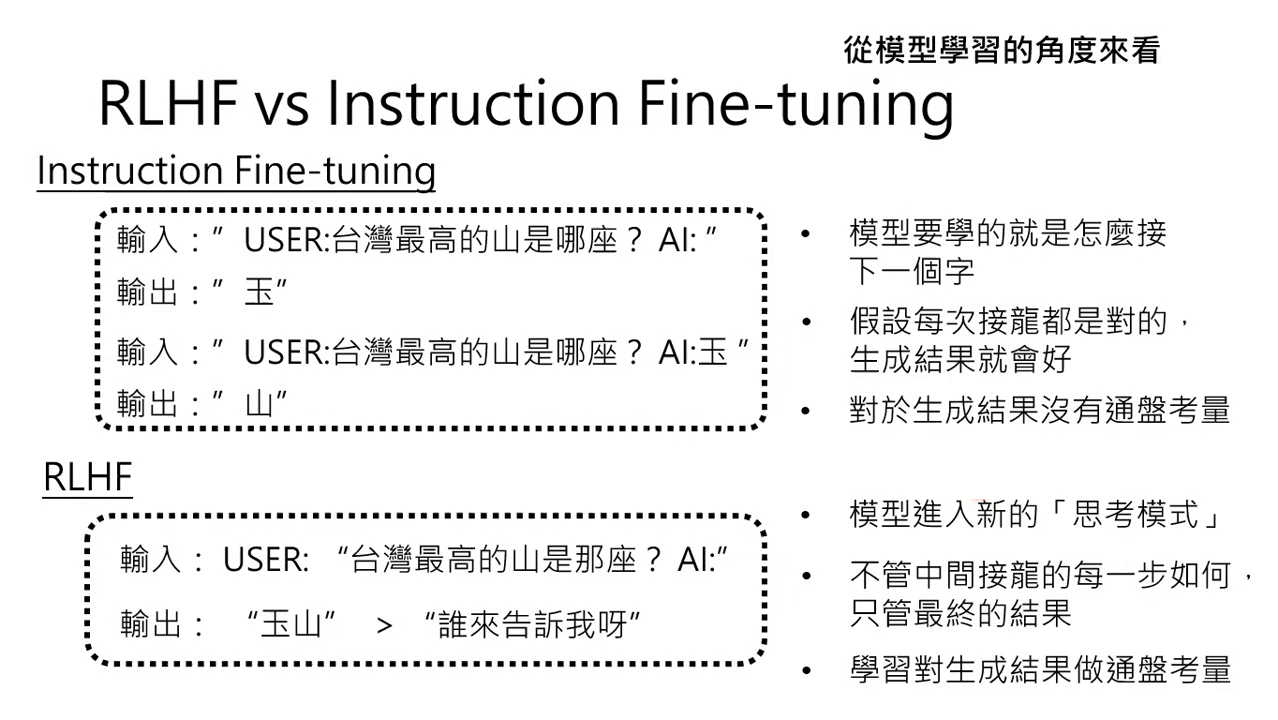
RLHF 與第二階段 (Instruction Fine-tuning) 的比較
根據來源資料,這兩個階段雖然都需要人類介入,但在執行面與模型學習邏輯上有顯著差異:
-
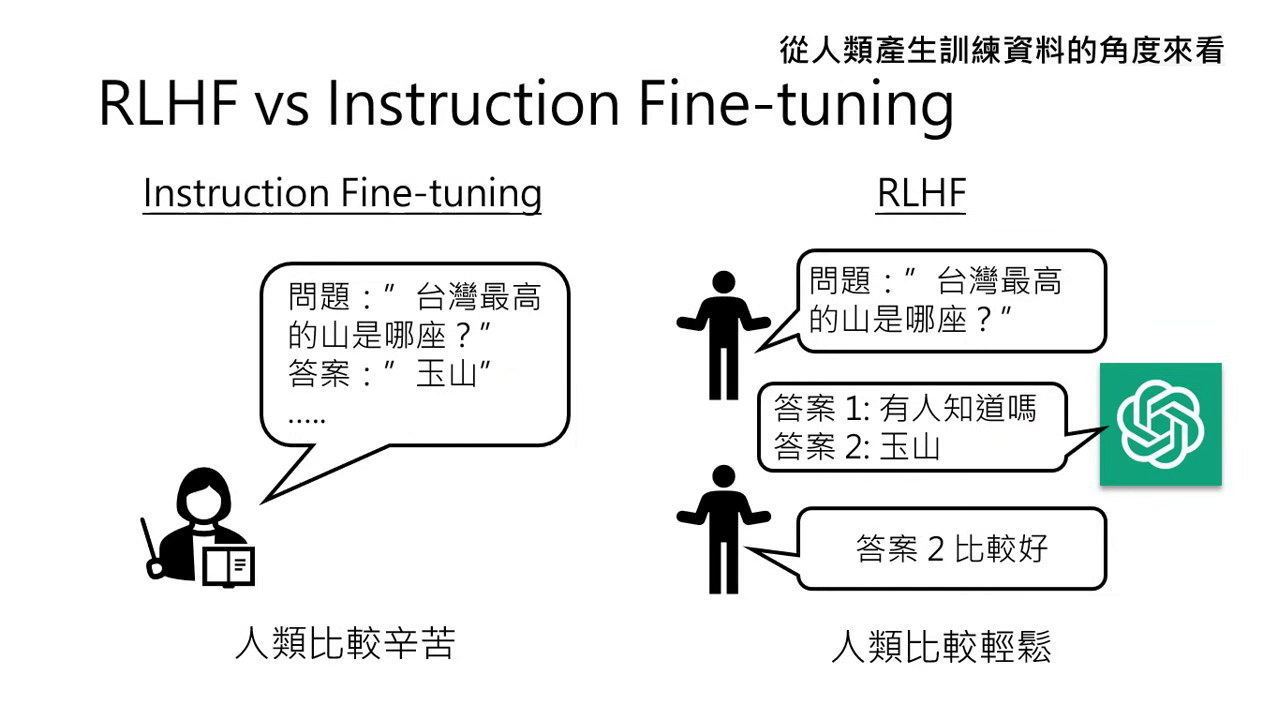
人類負擔 (產生資料的角度):
- Instruction Fine-tuning:人類較辛苦,必須想出問題並寫出正確答案。
- RLHF:人類較輕鬆,只需判斷模型產出的兩個選項中哪一個比較好。
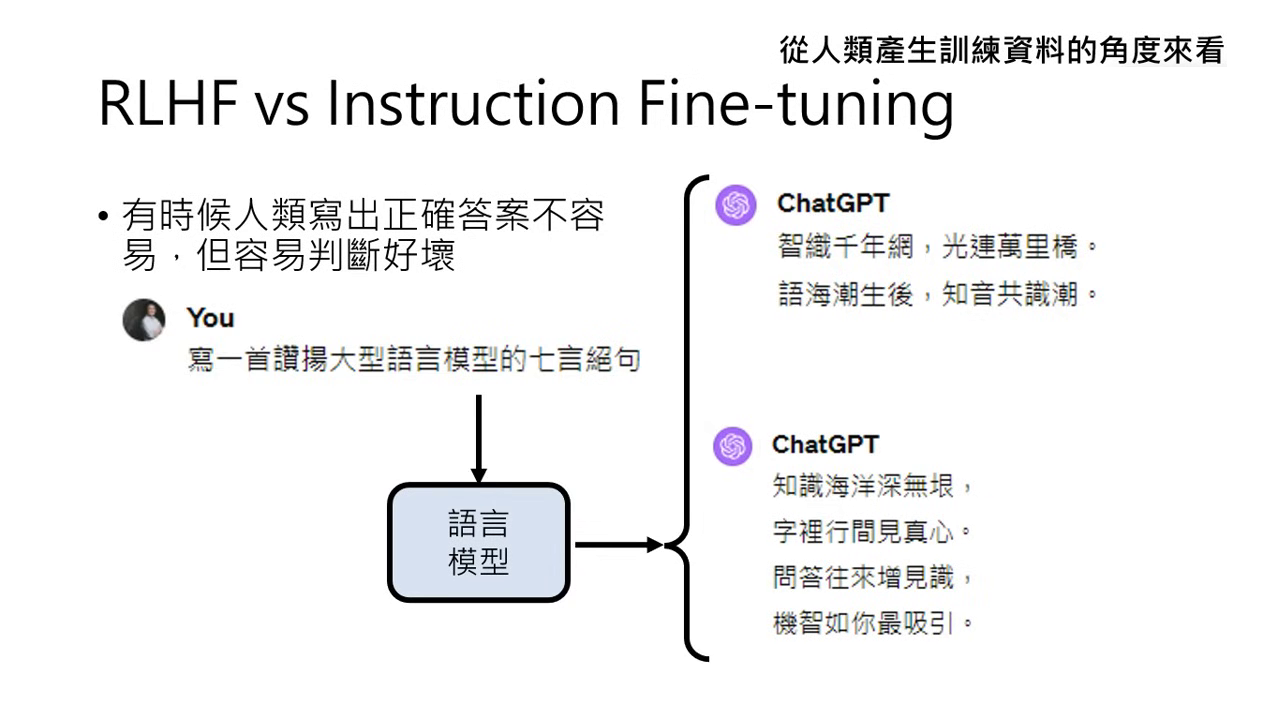
- 判斷優於寫作:人類要寫出好詩(如七言絕句)很難,但判斷哪一首格式正確(如七言 vs. 五言)卻相對容易。
人類直接想出問題的正確答案較難 人類判斷好壞較簡單
-
模型學習邏輯 (學習角度):
- Instruction Fine-tuning:��「只問過程,不問結果」。專注於每一步文字接龍是否正確,缺乏對最終生成結果的通盤考量。
- RLHF:「只問結果,不問過程」。模型會根據完整答案的好壞來思考,而非僅專注於下一步該接哪個詞。
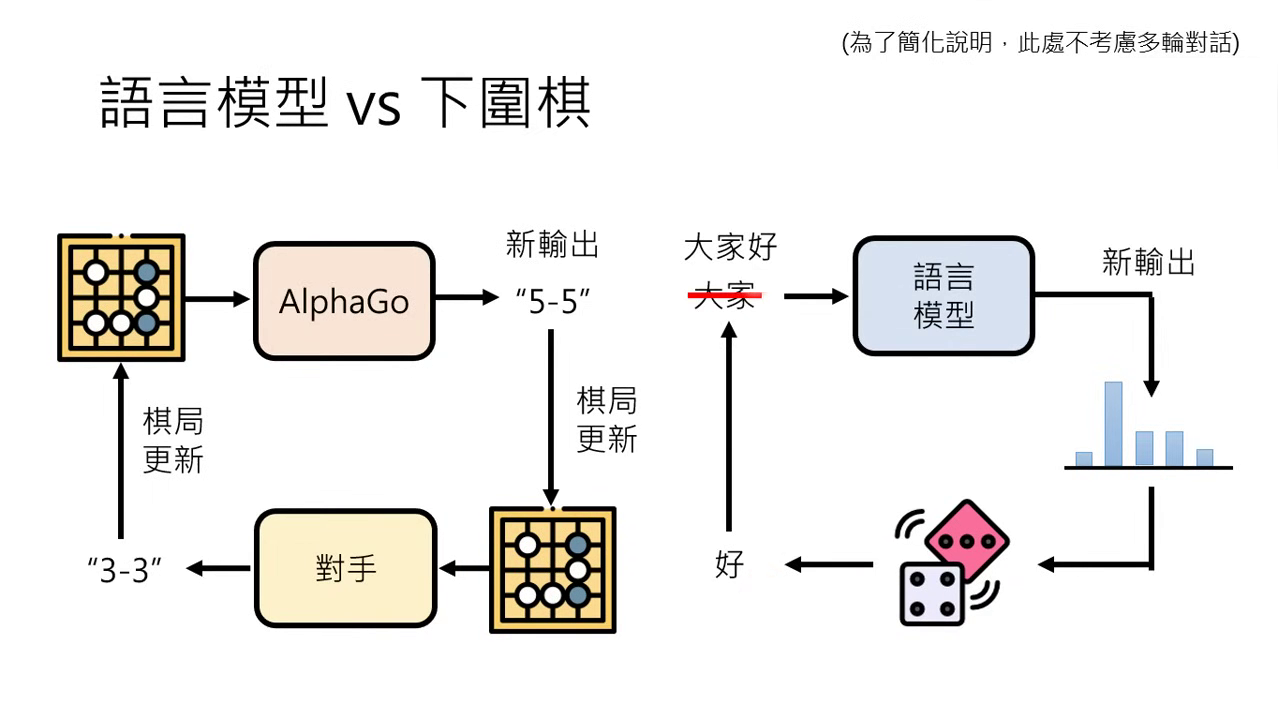
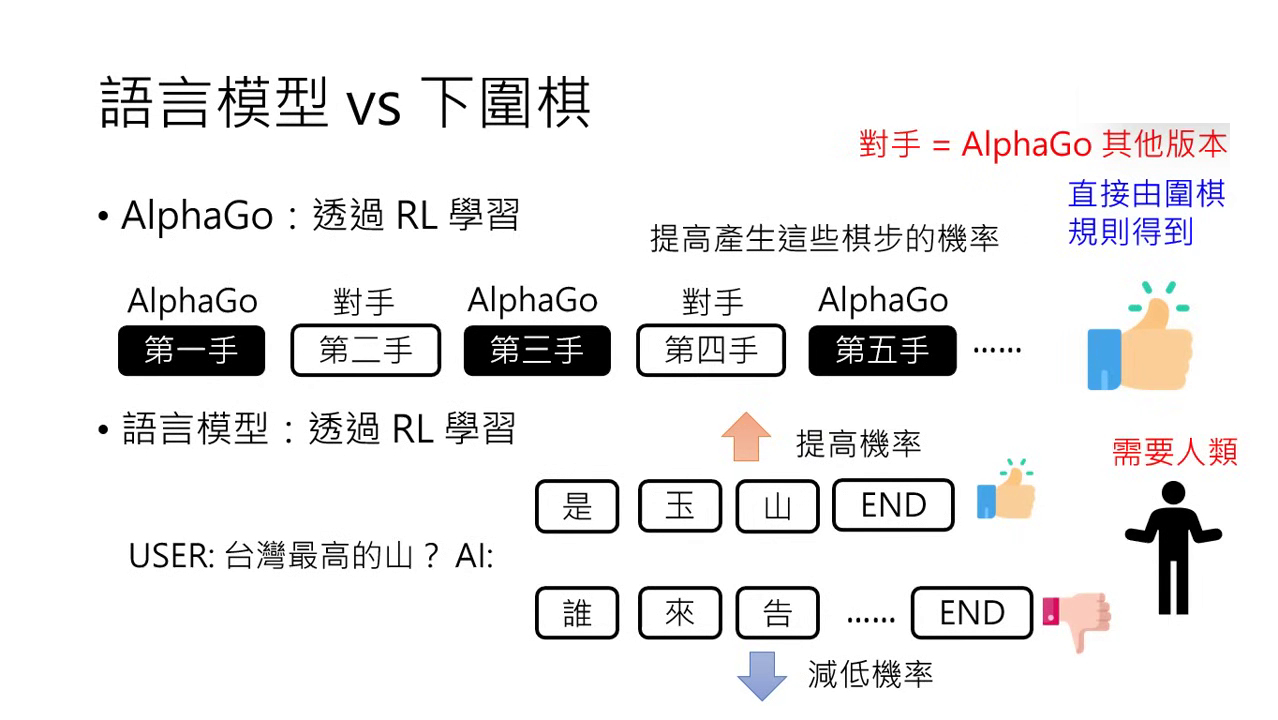
為什麼需要人類回饋? (與下圍棋的類比)
圍棋與語言生成的類比:預測下一步的任務
- 本質相同:AlphaGo 做的是看未完成的棋局並決定下一步落子位置;語言模型則是讀未完成的句子並決定下一個 Token。
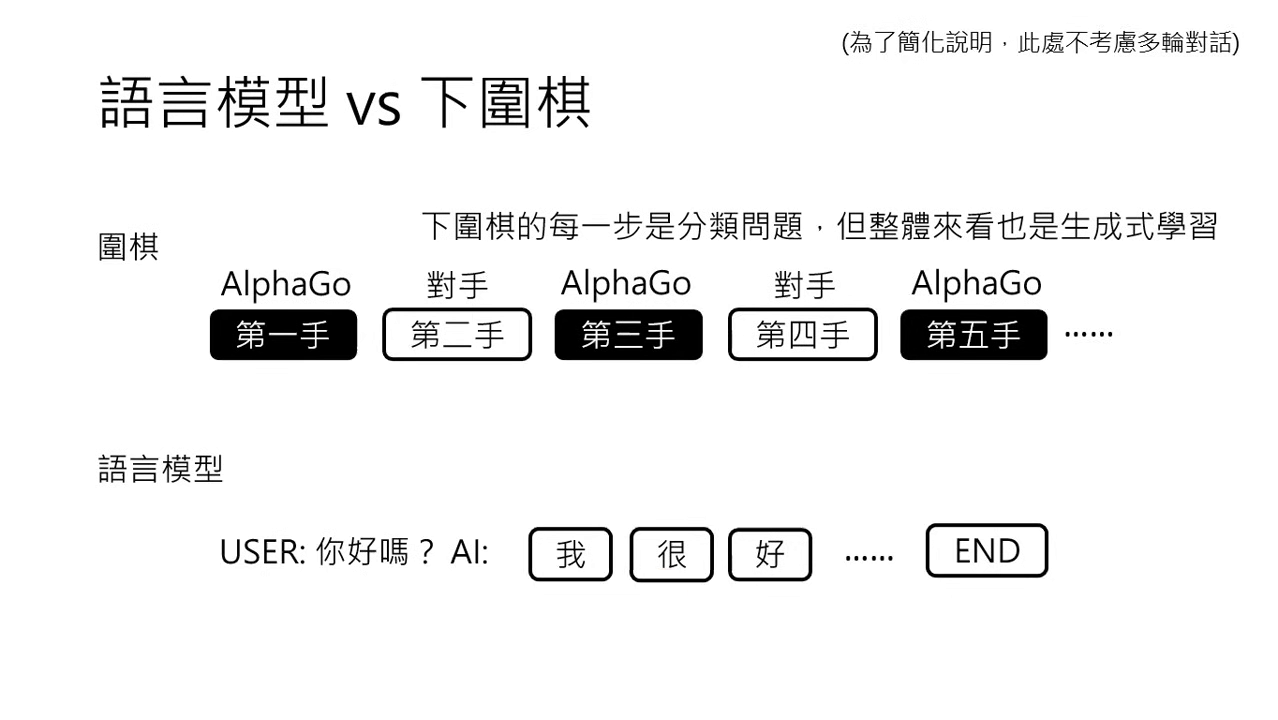
- 生成式學習中的分類問題:雖然兩者整體看起來都是生成式學習,但細究其每一步,其實都是在解一個分類問題(決定下一個字或下一手棋落在哪裡)。
- 互動過程:AlphaGo 是根據棋局變化與對手互動來產生新的輸出;語言模型則是根據機率產生 Token 並接在輸入後面,形成持續的「文字接龍」。
 |  |
|---|---|
| 語言模型和下圍棋細分每一步都是分類問題 | 語言模型和下圍棋整體看是生成式學習 |
訓練階段的深度對應:從模仿到強化
- 模仿階段(對應第一、二階段):AlphaGo 第一階段是「跟著棋譜學習」,人類怎麼下它就跟著下;這對應了語言模型的 Pre-train(預訓練) 與 Instruction Fine-tuning(指令微調),即人類老師教什麼,模型就跟著說什麼。
- 強化階段(對應第三階段):AlphaGo 的第二階段是透過 RL(增強式學習),在發現自己贏棋時提高該棋步的機率;這正對應了語言模型的第三階段 RLHF。
 |  |
|---|---|
| 模仿階段(對應第一、二階段) | 強化階段(對應第三階段) |
規則明確性與回饋機制的差異
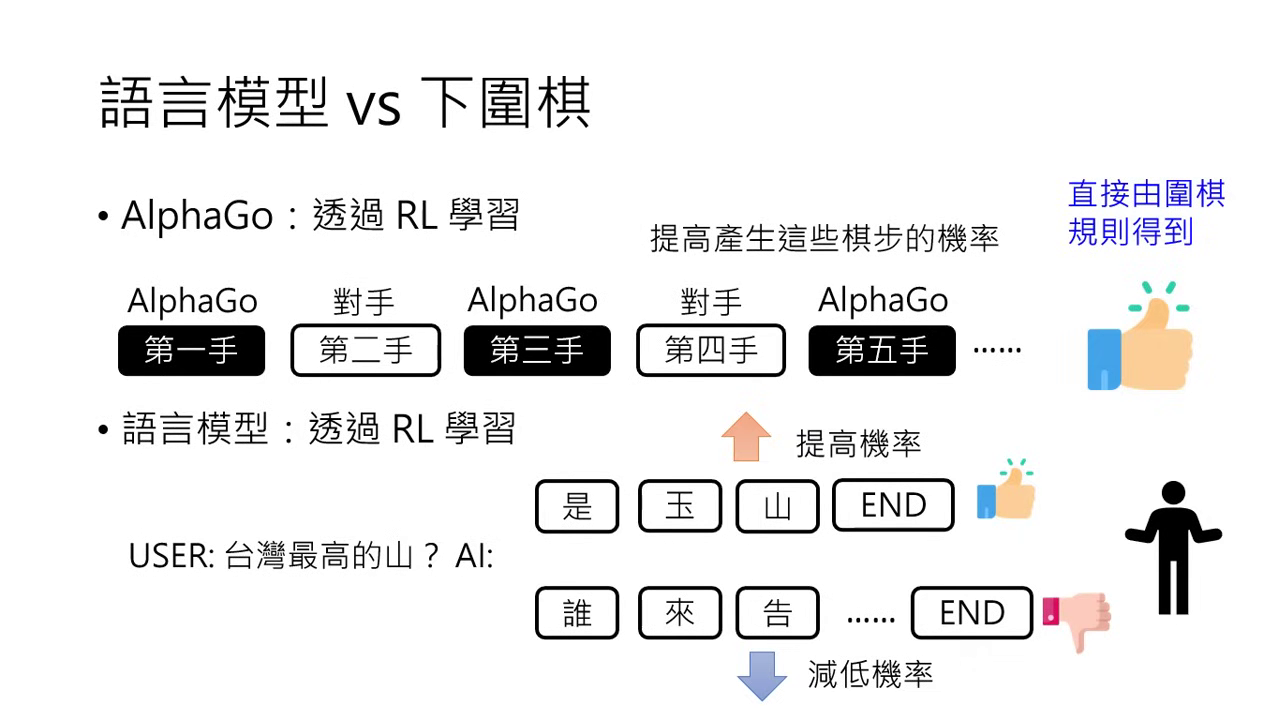
- 規則的明確性:圍棋的輸贏有既定規則,AlphaGo 可以單純透過規則知道勝負來獲取正向或負向回饋。
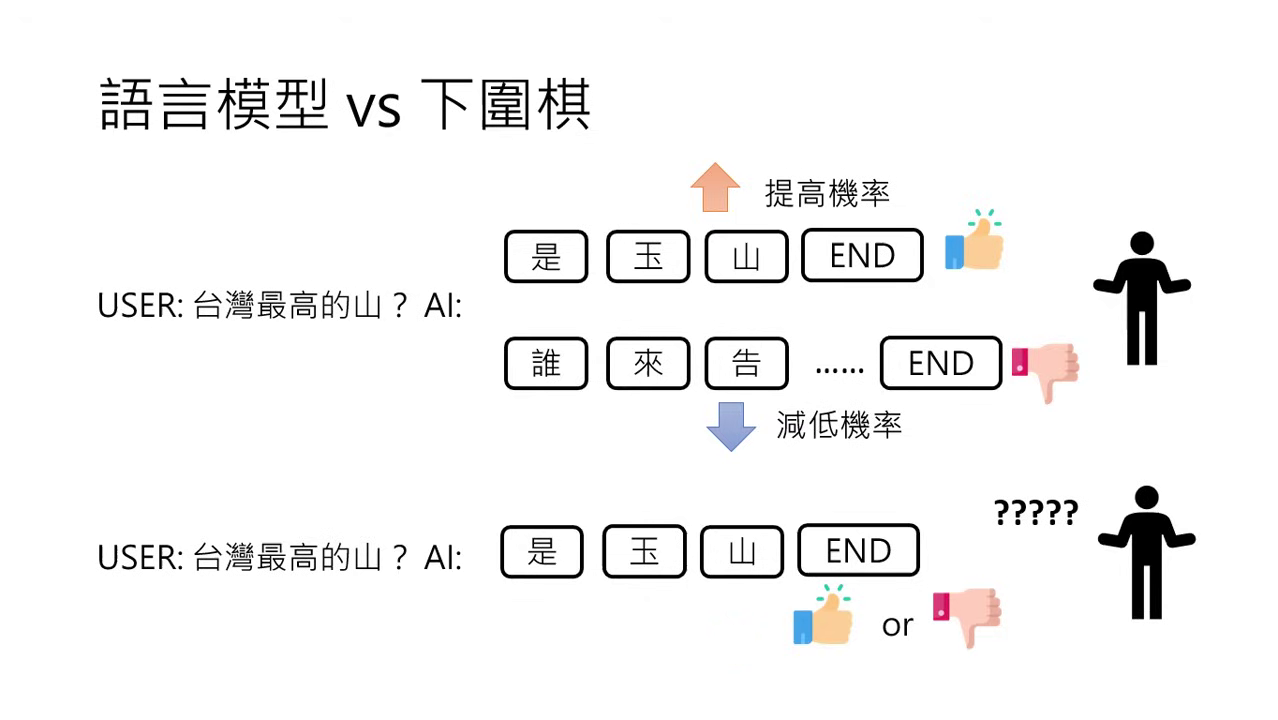
- 語言好壞的相對性:語言的好壞沒有標準答案。例如問「臺灣最高山是哪座?」,回答「玉山」可以算好,但也有人認為應該補充相關資料才算好,這完全取決於人類的主觀偏好。
- 「左手打右手」的可能性:AlphaGo 可以在不需要真人的情況下,讓不同版本的自己對弈(左手跟右手下)來進步。但語言模型則必須由人類介入,來評斷句子是好是壞。
為什麼採用「排序」而非單一評分?
- 難以定義絕對好壞:直接問人類「這句話好不好」通常很難回答,�因為好壞是相對的且缺乏明確規則。
- 排序更容易操作:在文獻與實務上,讓語言模型產生多個答案並由人類進行排序是比較常用的做法,因為人類在比較兩個選項的優劣時,比給出單一絕對評分更為精準。
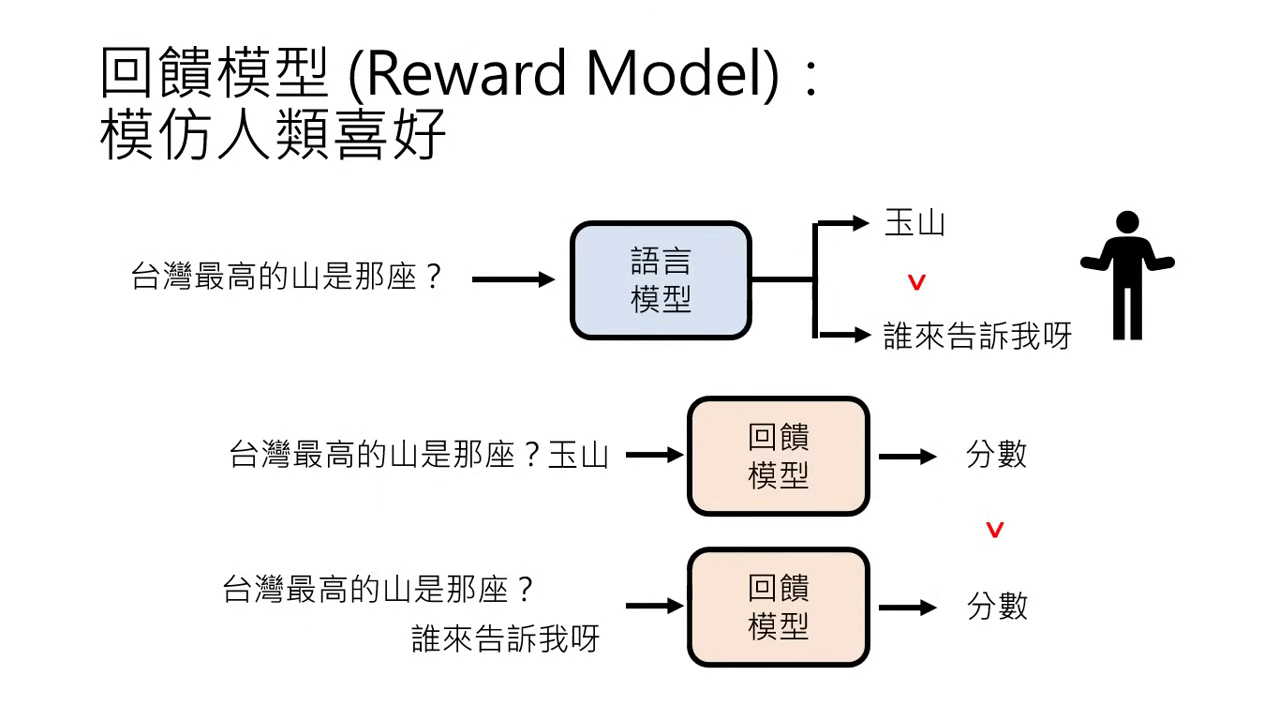
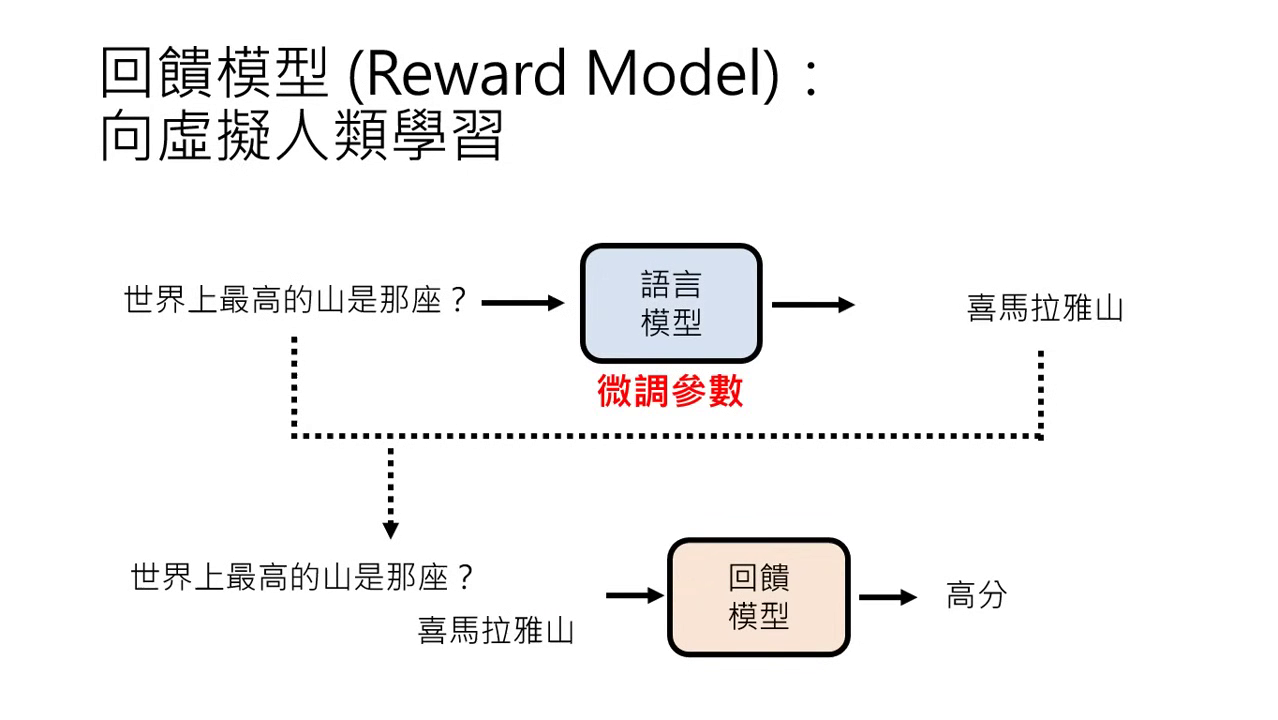
回饋模型 (Reward Model):創造虛擬人類
由於人類的時間精力有限,實務上會訓練一個虛擬的「人類老師」:
-
定義:Reward Model (RM) 是用人類的喜好資料訓練出的模型,用來模擬人類的評分機制。
-
訓練方式:輸入問題與答案,訓練模型輸出分數。若 A 答案優於 B,則 A 的得分必須高於 B。
-
使用方式:
- 篩選答案:產生多個答案後,由 RM 評分並只選最高分者給使用者看。
- 指導學習:讓語言模型直接跟著 RM 學習,根據得分高低微調參數。
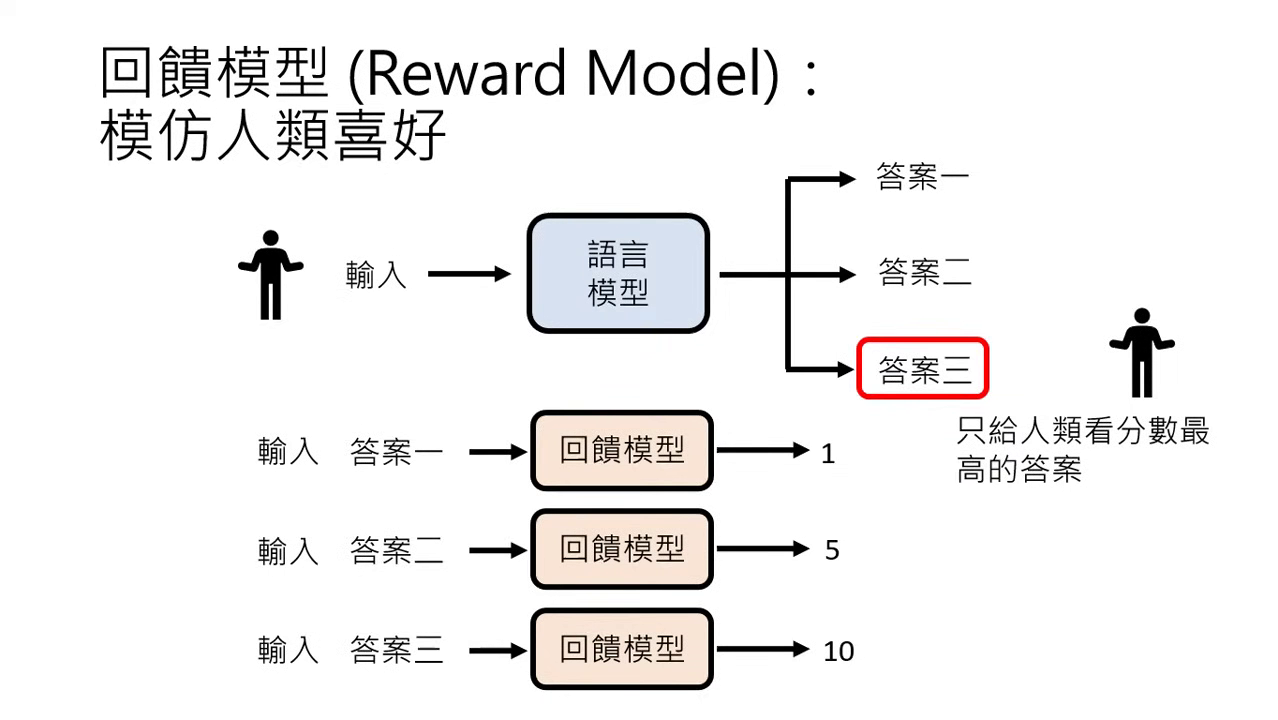
篩選答案 指導學習
-
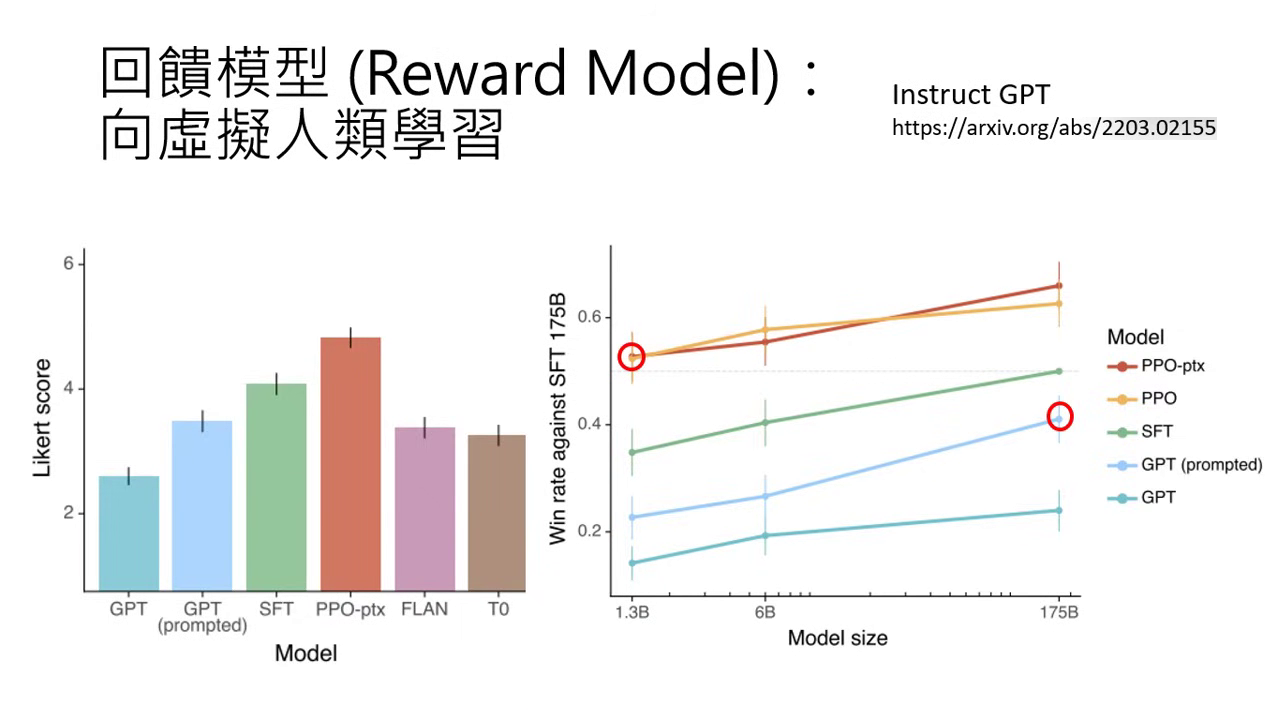
效能效益:實驗顯示,1.3B 參數的小模型若經過 RLHF,表現有機會超越沒有 RLHF 的 175B 大模型。
過度向虛擬人類學習的副作用
- 獎勵過度優化 (Reward Hacking):模型若過度迎合 RM,會產生奇怪的行為。例如 2020 年的研究發現,摘要模型會在結尾瘋狂加「please」或加三個問號,只因 RM 認為這樣分數高。
- ChatGPT 的後遺症:如說話饒舌(愛列點與總結)、過度道歉、開頭愛用「As an AI language model」、語帶保留或過於常拒絕要求,都可能是過度與虛擬老師學習的結果。
- 替代方案:目前有 DPO、KTO 等新演算法試圖在不使用虛擬老師的情況下達成同樣效果。

發展與挑戰
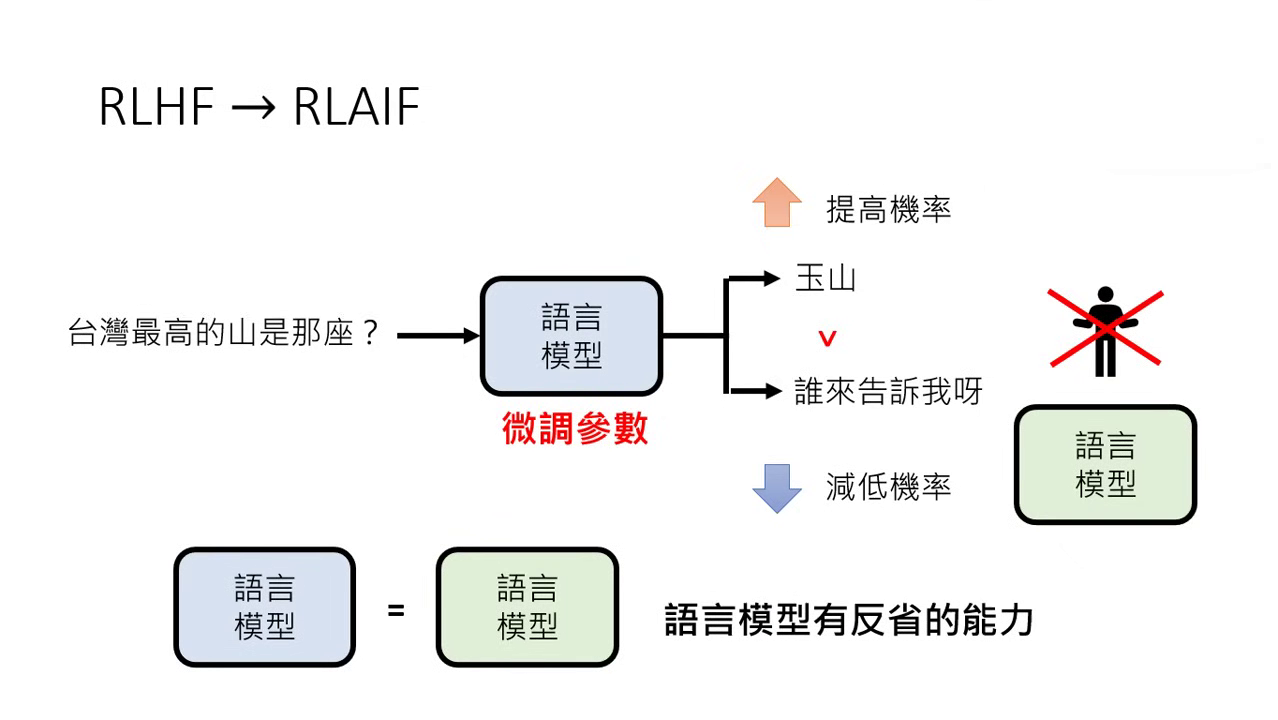
- RLAIF (AI Feedback):隨著 AI 增強,開始嘗試用 GPT-4 等模型來給予回饋(AI 教 AI),甚至讓模型「自我反省」來提供回饋。
- 價值衝突:什麼叫「好」沒有固定標準。例如「教我做火藥」,安全模型 (Safety) 覺得不教是好,有用模型 (Helpfulness) 則覺得應該幫忙,不同模型(GPT-4, Gemini, Claude)的對齊標準各異。
- 人類盲區:當 AI 面對人類也無法判斷好壞的問題時(如:該唸博班還是去工作),人類的回饋可能帶有偏見,進而引導模型走向錯誤方向。
 |  |
|---|---|
| RLAIF | 什麼叫「好」沒有固定標準 |
總結
- 第一階段(Pre-train):奠定模型的基礎能力(Foundation Model)。
- 第二、第三階段:屬於 Alignment(對齊),目的是確保模型的行為與輸出符合人類的偏好與實際需求。