大型語言模型修練史 — 第二階段:名師指點,發揮潛力
在第一階段,模型透過自我學習累積了深厚的「內功」(世界知識與語言知識),但仍不知道如何正確回答問題,因此需要進入第二階段:指令微調 (Instruction Fine-tuning)。

訓練機制:指令微調 (Instruction Fine-tuning)
- 教材格式:人類老師需要準備「問題」與「正確答案」的成對資料。
- 文字接龍化:將問答轉換成模型可理解的格式,例如「使用者:[問題] AI:[答案]」。模型學習在看到「AI:」符號後,接出正確的答案。
- 標註的重要性:資料必須清楚標明哪個部分是使用者 (User) 講的,哪個部分是 AI 講的。
- 若未標註,模型會無法區分這是在對話還是在��自問自答,導致輸出的結果不正確。
- 即使在 ChatGPT 介面上看不到,背後的文字接龍過程很可能也包含這些代表身分的符號。
 |  |
|---|---|
| 人類老師的指令微調 | 需要標註使用者和 AI |
為什麼需要預訓練 (Pre-train) 作為基礎?
人類標註資料的限制與錯誤學習風險
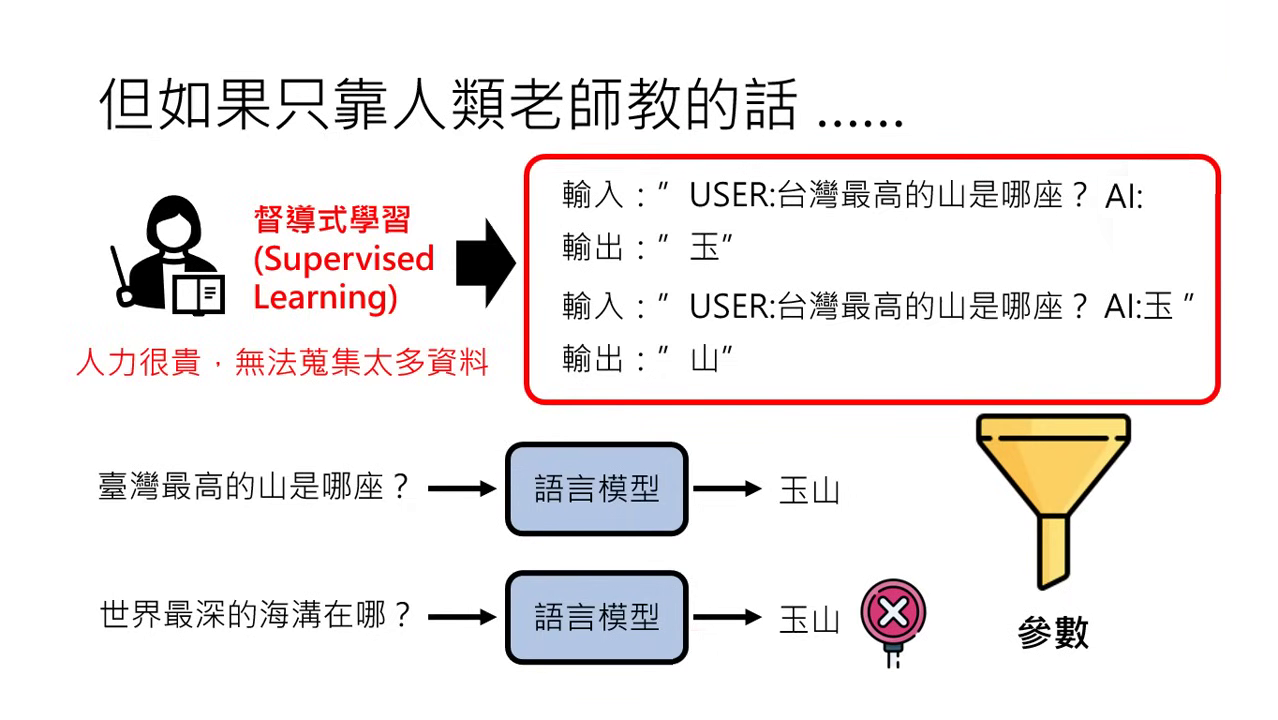
- 資料稀缺性:相較於網路上近乎無窮的文字,人類能提供的標註資料(問題與正確答案)非常有限。
- 機器的偷懶特性:機器學習的唯一目標是「找到一組滿足訓練資料要求的參數」,它並不像人類一樣理解邏輯。
- 錯誤規則的風險:
- 實例:若教材只教「臺灣最高的山是哪座?答案:玉山」,機器可能會找到一組參數,其規則是「只要看到『最』這個字,就輸出『玉山』」。這組參數完全符合訓練要求,但若問到「世界最深的海溝在哪裡?」,模型會因為看到「最」字而同樣回答「玉山」。
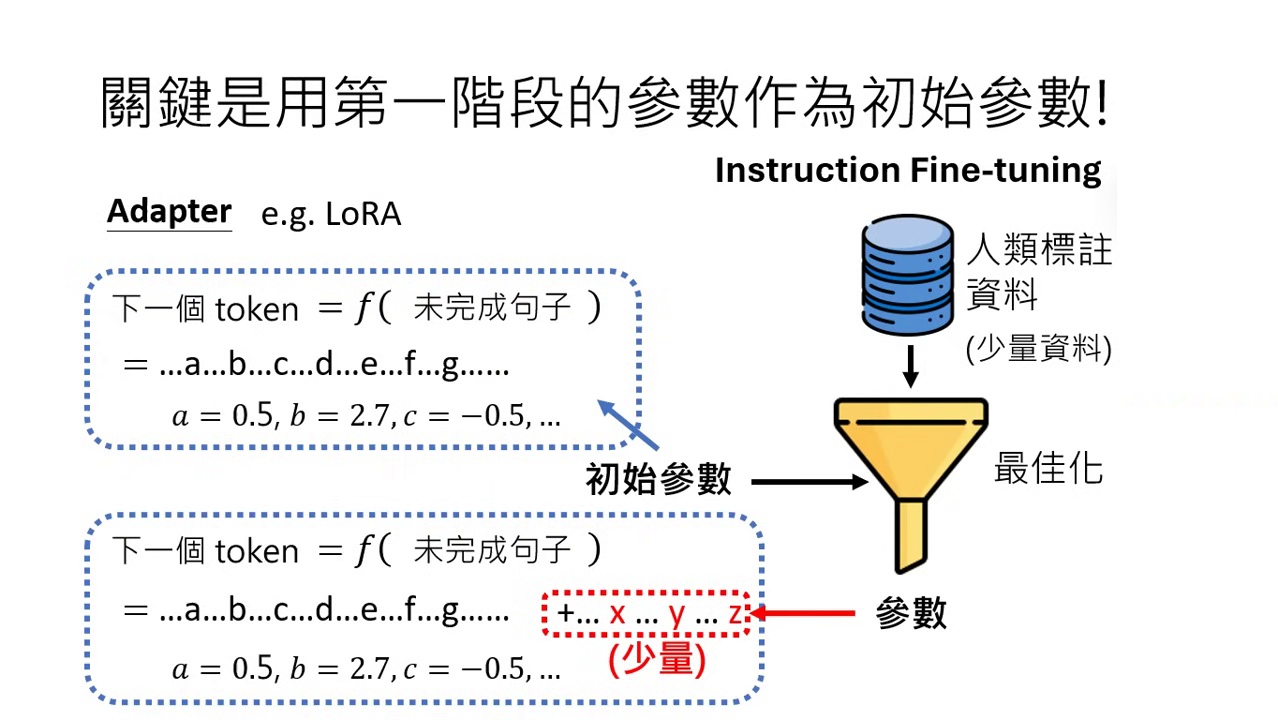
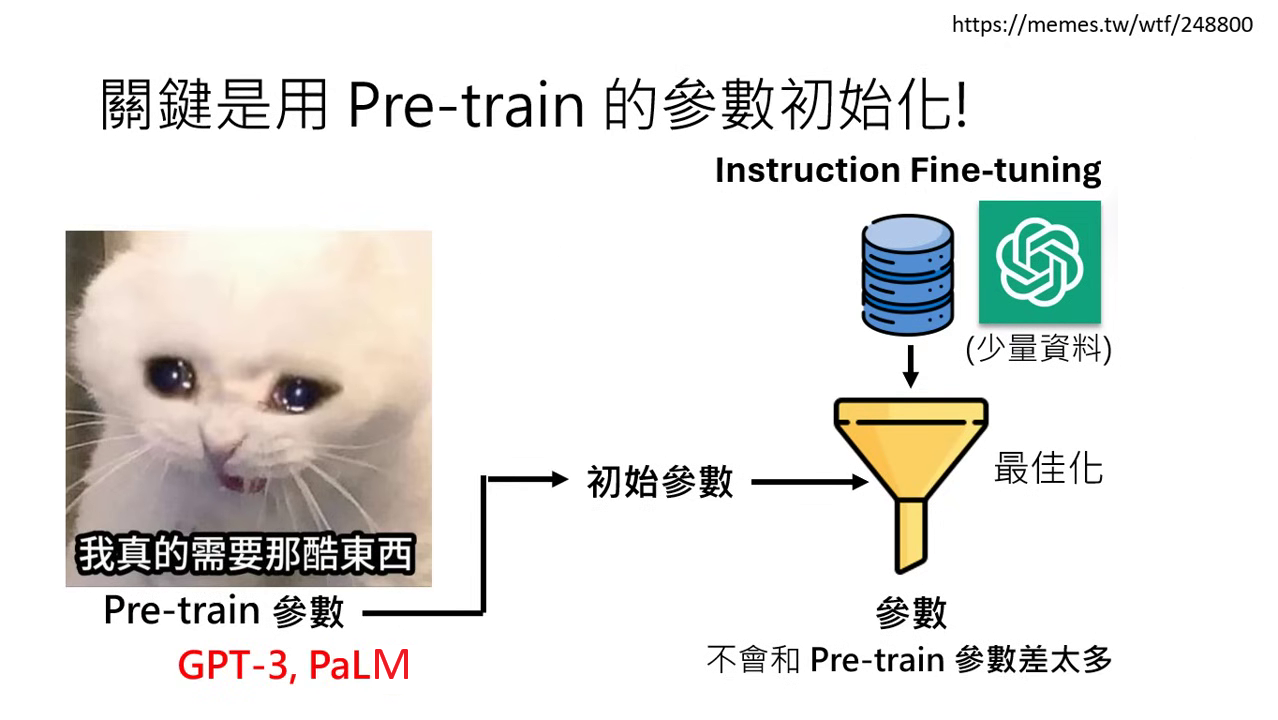
初始參數的決定性影響
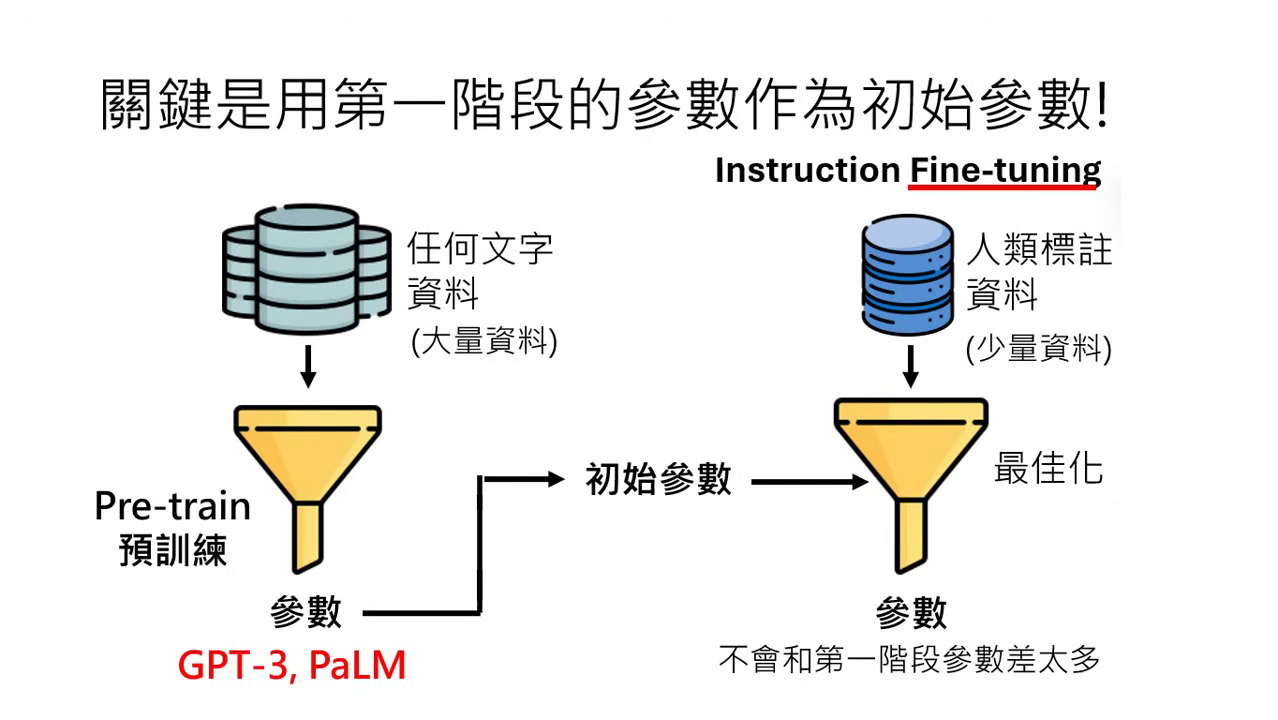
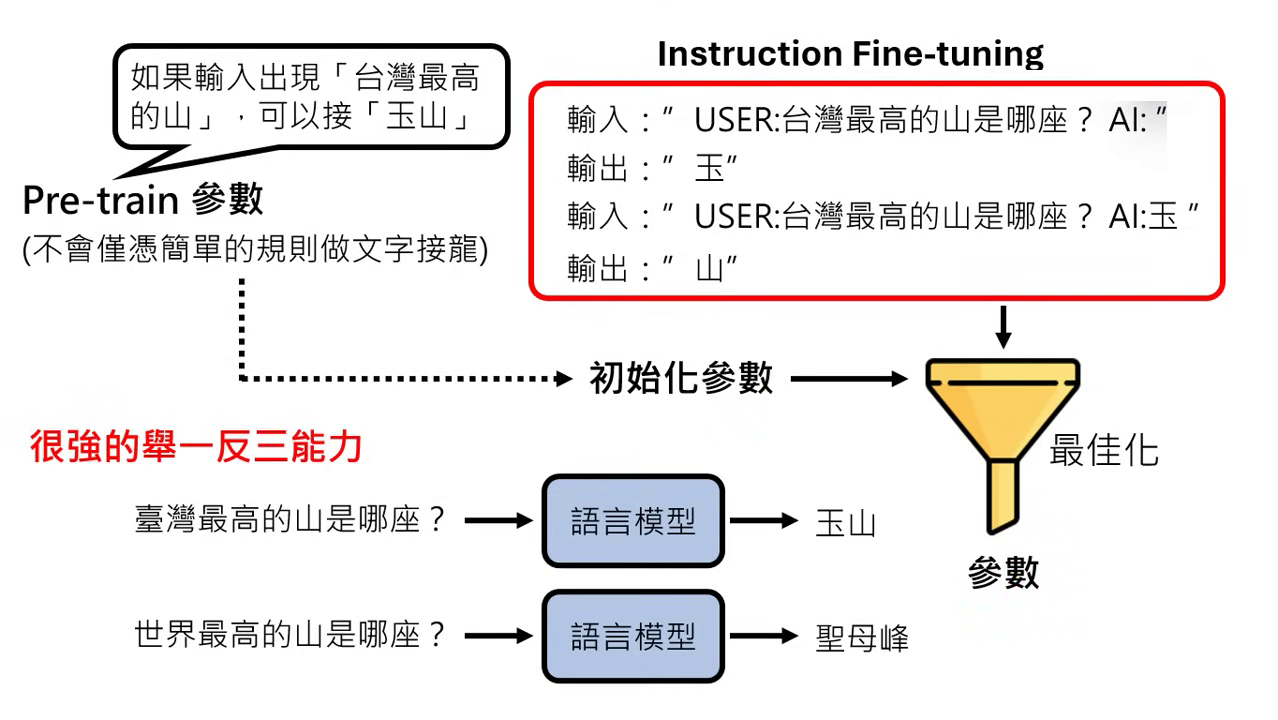
- 繼承強大內功:成功關鍵在於將第一階段透過海量資料學到的參數(如 GPT-3 或 PaLM 的參數)作為第二階段的初始參數。這意味著最佳化的過程是從一個已經具備「上乘內功」的起點開始找尋。
- 微調 (Fine-tune) 的定義:因為初始參數已經具備複雜且有道理的規則,在第二階段進行微調時,找出的新參數不會與初始參數偏離太多,從而確保模型行為仍然維持在有道理的範圍內。
- 傳承複雜的規則:
- 預訓練模型看過天文數字般的資料,它必須學會極其複雜的規則才能成功預測下一個字(例如它知道臺灣最高接玉山、世界最高接聖母峰),而不只是看關鍵字。
- 由於初始參數本身就蘊含了這些正確的邏輯,微��調後的模型就不容易退化成那種「看到『最』就接『玉山』」的無腦規則。
極致的「舉一反三」能力
- 裸考實測案例:
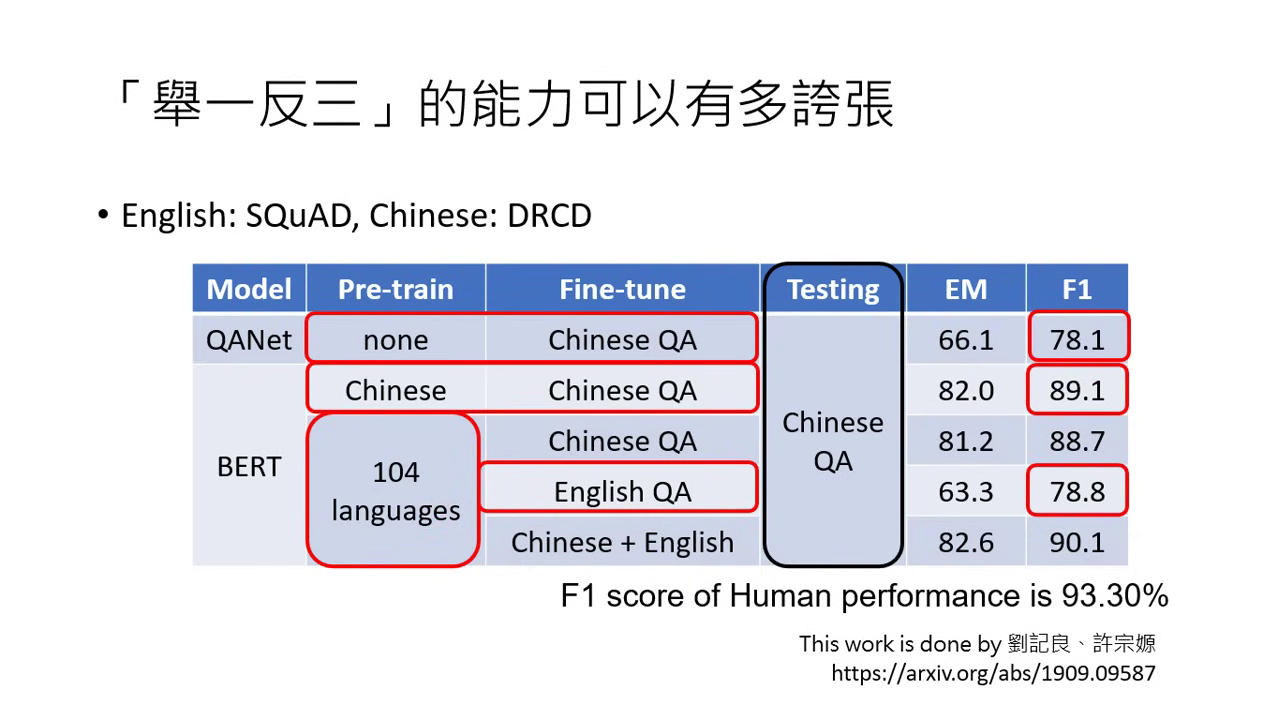
- Multilingual BERT:在 104 種語言上預訓練過。若只在「英文」的閱讀理解資料上進行微調(教它如何做英文考題),它會自動學會如何做「中文」的閱讀理解。
- 實驗數據:測試一組完全沒看過中文考題的模型(對中文而言是「裸考」),其正確率高達 78%,竟然與直接拿中文標註資料訓練出的模型表現相當。
- 原理總結:因為預訓練時模型已經具備了「世界最高是聖母峰」等知識,微調只是教它「回答問題的方法」。一旦它學會了答題框架,就能自動套用到所有它已具備知識的語言中。
技術細節:Adapter 與 LoRA
- Adapter 概念:在做微調時,完全不動預訓練的初始參數,僅在原函式後增加少量的未知數進行最佳化。
- LoRA:是 Adapter 的一種,透過這種方式可以確保新參數與舊參數非常類似。
- 優點:
- 減少運算量:不需要找尋所有參數,適合資源有限的環境(如 Colab 免費版)。
- 維持效能:在不動原始大腦的情況下,加入少量新參數即可達成目標。
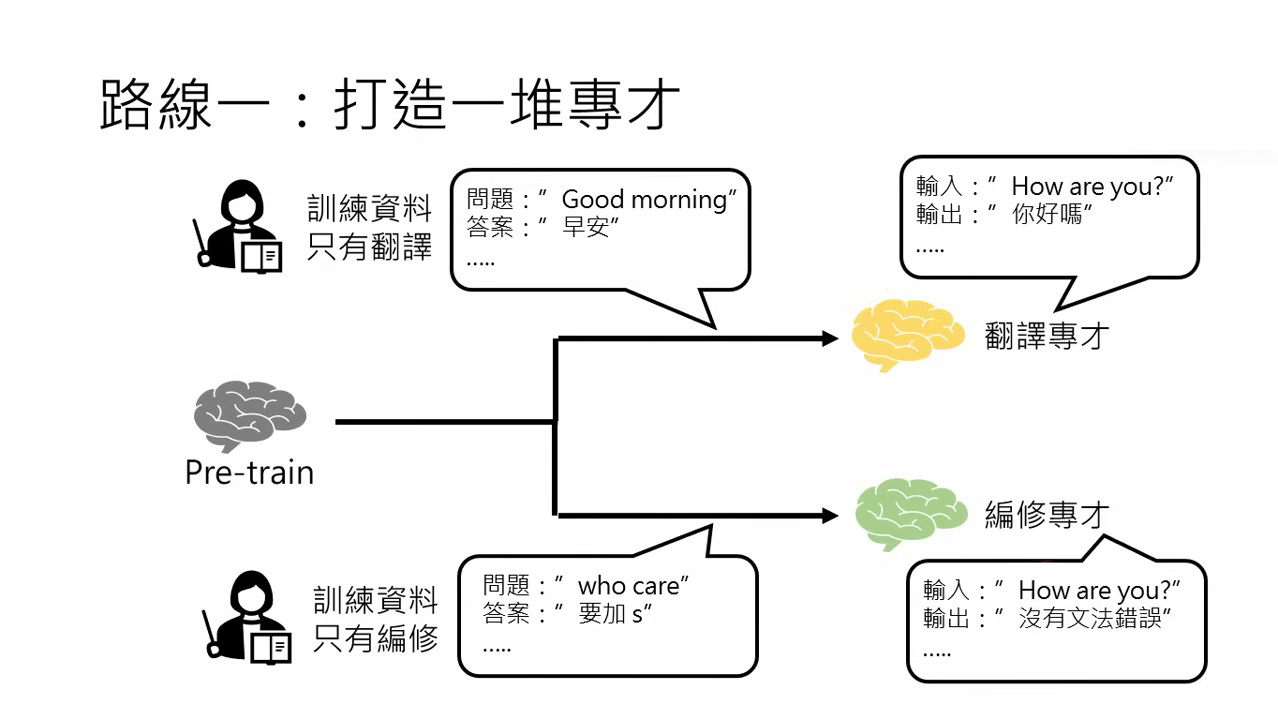
微調的兩條路線:打造專才 (Specialist)
針對特定任務(如翻譯、編修)收集大量標註資料,打造只會該項技能的模型。
具體實例說明
- 翻譯專才:收集大量的翻譯對資料(例如:輸入 "Good morning",正確輸出為「早安」;輸入 "How are you",輸出「你好嗎」)。
- 編修專才:收集文法錯誤與修正後的對應資料。例如當使用者輸入 "who care" 時,模型會學習輸出應加上 s 變成 "who cares"。
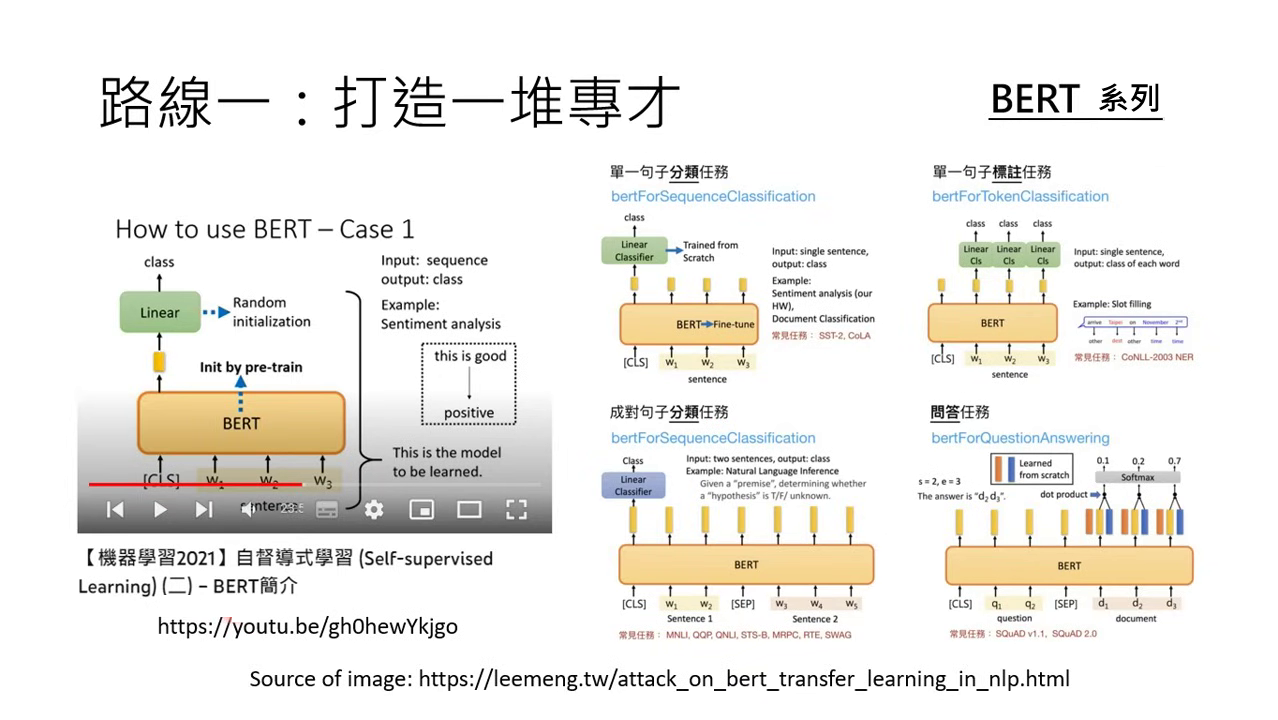
代表性模型與歷史背景
- BERT 系列:BERT 模型是走專才路線的典型代表,過去研究者常以 BERT 為基礎,透過微調打造出應對各種不同任務的專才系統。
- 早期 GPT 應用:在大型語言模型技術發展初期,人們使用 GPT 的方式也是拿它來打造一堆專門處理特定任務的專才系統。
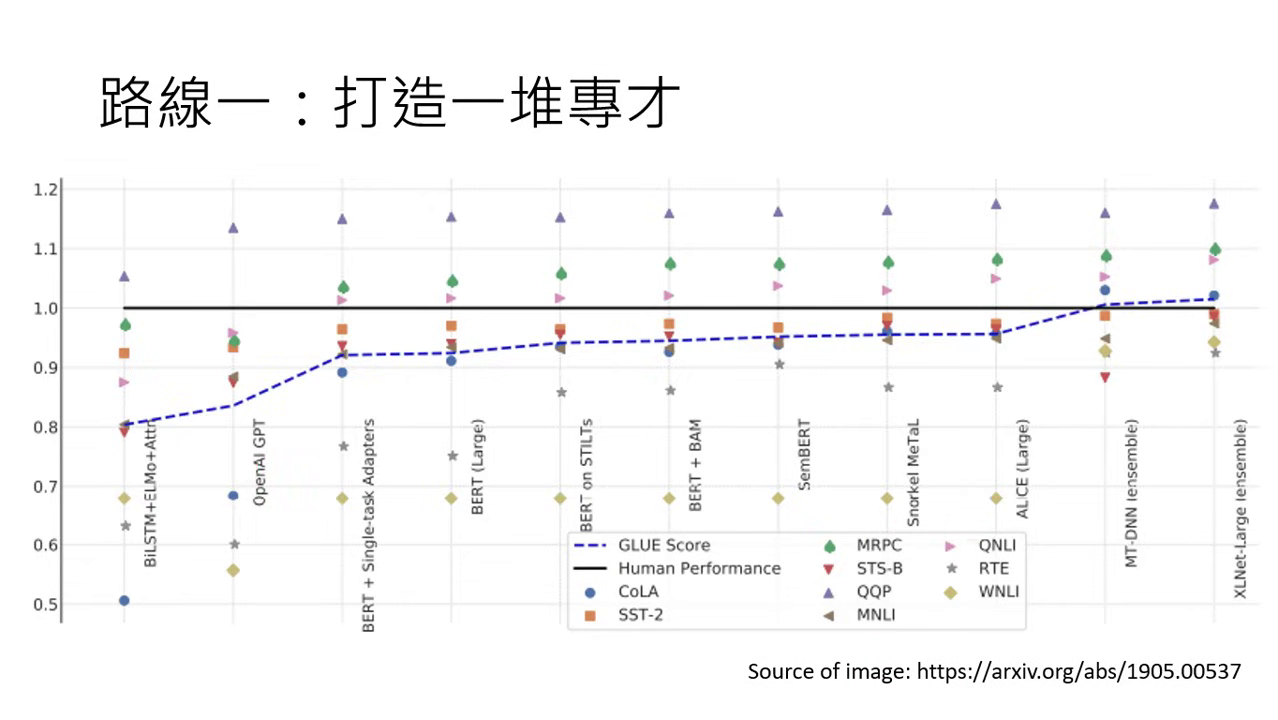
效能表現
- 超越人類平均:在 2019 年的研究中,研究者針對 9 個不同的任務分別打造了專才模型。實驗數據顯示,這些以強大模型為基礎打造出的專才,其平均能力在某些任務上甚至能超過人類的表現。
- 開發成本:雖然專才表現強悍,但缺點在於世界上任務成千上萬,為每一項任務都單獨收集資料並訓練一個專屬模型顯得過於麻煩,這也促使了後來「通才」路線的興起。
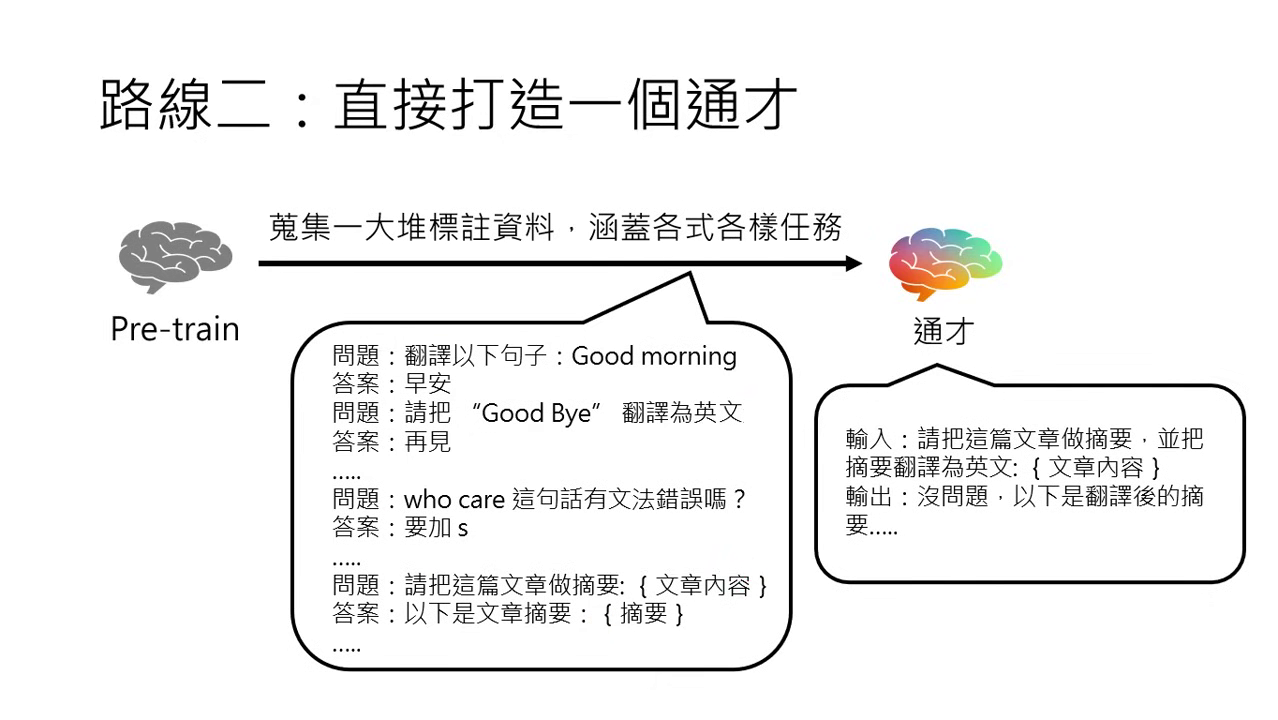
微調的兩條路線:打造通才 (Generalist)
將所有想得到的任務標註資料全部集合起來交給模型。
具體實例說明
- 追求舉一反三的能力:期望模型不僅能完成教過的任務,還能處理沒看過的「任務變形」。例如在訓練中只分開教過「翻譯」與「摘要」,但通才模型在面對「請把這篇文章摘要後並翻譯」這類複合式新任務時,也能正確執行。
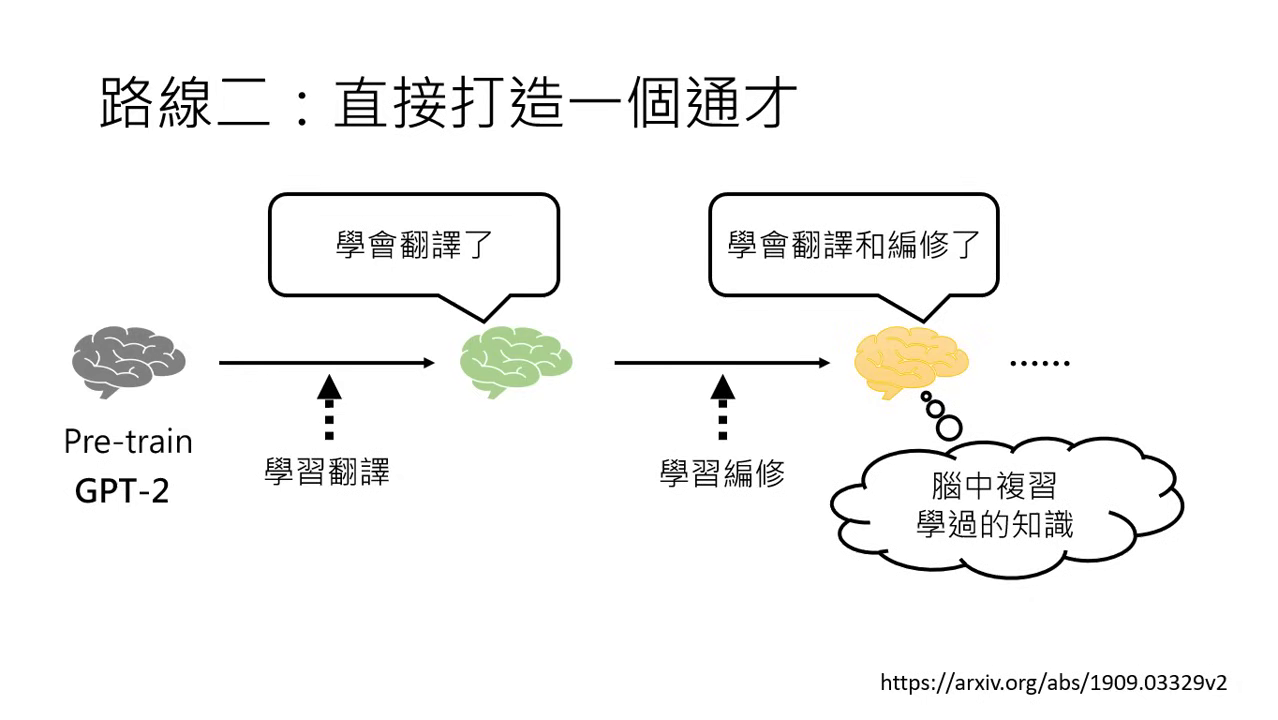
技術挑戰:連續學習與遺忘
- 災難性遺忘:19 年的研究(如以 GPT-2 為基礎的實驗)發現,若一個個任務連續教給語言模型,模型可能會忘記舊任務。
- 解決方案:研究者開發了讓模型在腦中「複習」已學過知識的方法,以維持多樣化的任務處理能力。
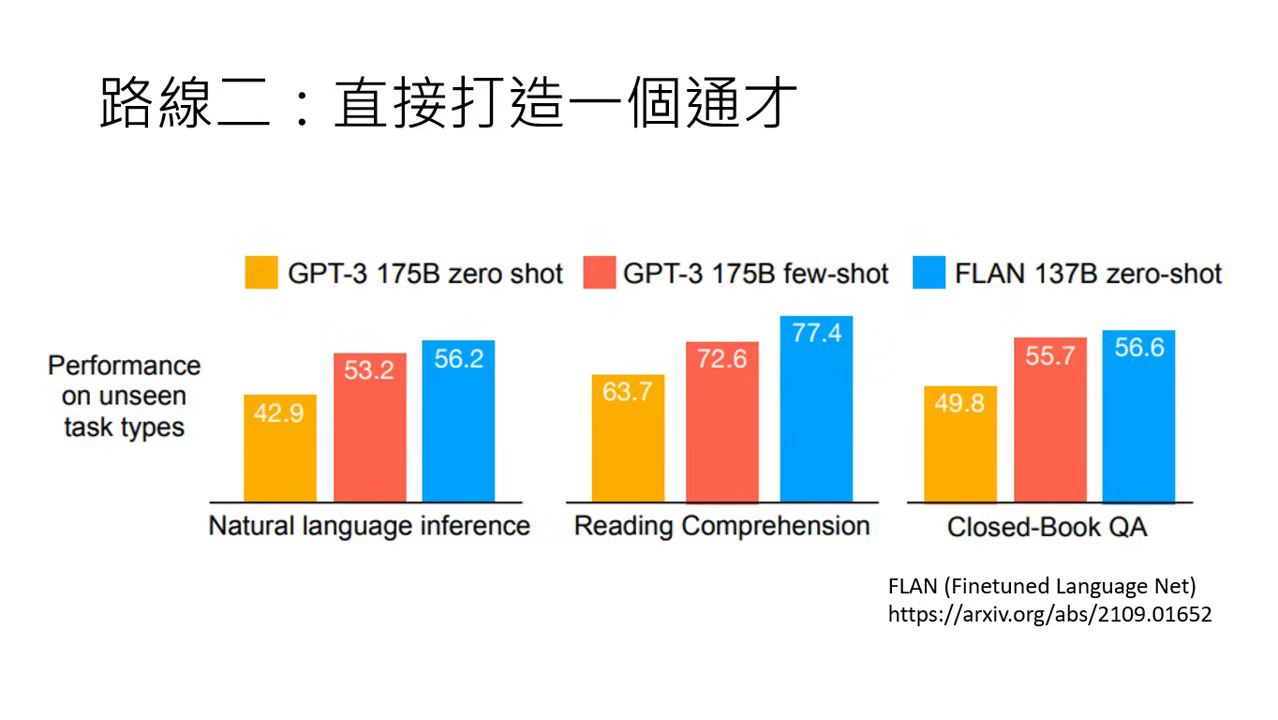
關鍵進展:Google 的 FLAN 系列
- FLAN (Fine-tuned Language Net):Google 在 2021 年證實,在大量任務上做過指令微調後,模型在「從未看過的新任務」上的表現能顯著超越原始的 GPT-3。
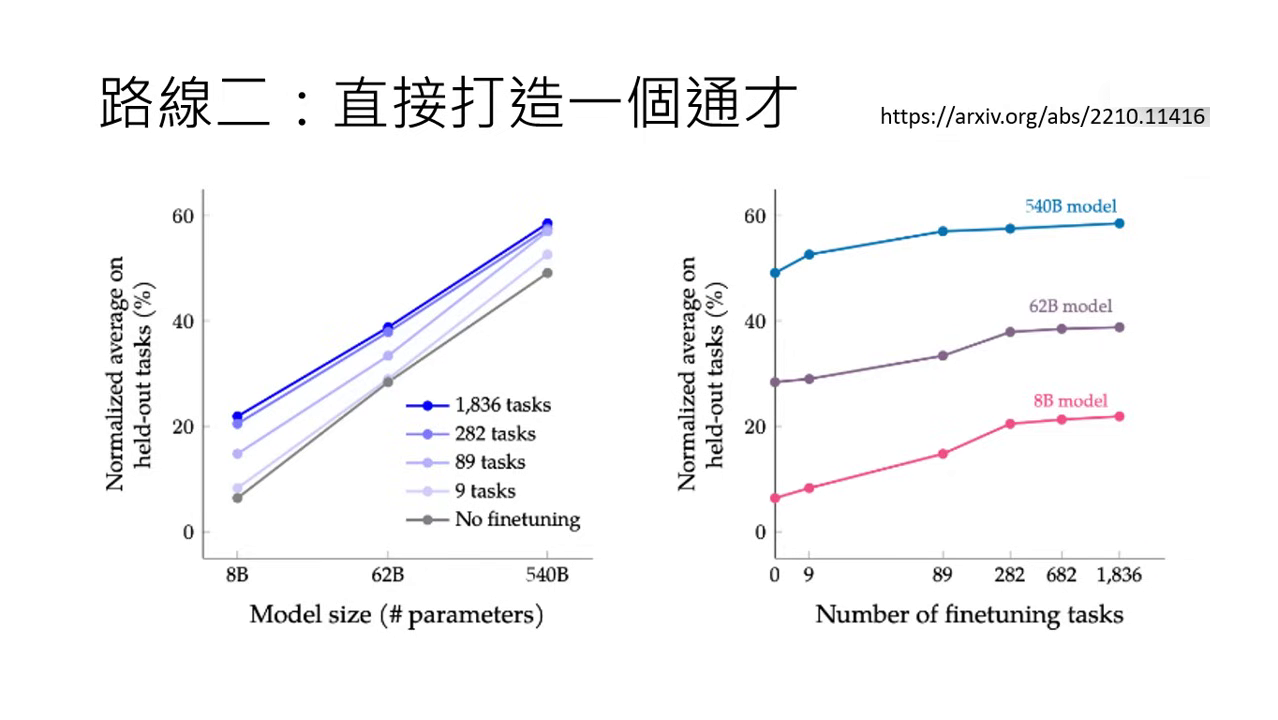
- 規模化 (Scaling) 的效益:2022 年的研究進一步將任務增加到 1800 個。這裡指的不是 1800 筆資料,而是 1800 種不同的任務(如翻譯是一個任務,裡面包含上萬筆資料)。
- 研究發現:無論模型大小,隨著訓練的任務數量越多(資料集多樣性越高),模型在陌生任務上的表現就越好。特別是小模型在接受指令微調後,能力的提升尤其顯著。
 |  |
|---|---|
| FLAN (Fine-tuned Language Net) | 不論模型大小,任務越多表現越好 |
OpenAI 的突破:InstructGPT 與真實數據
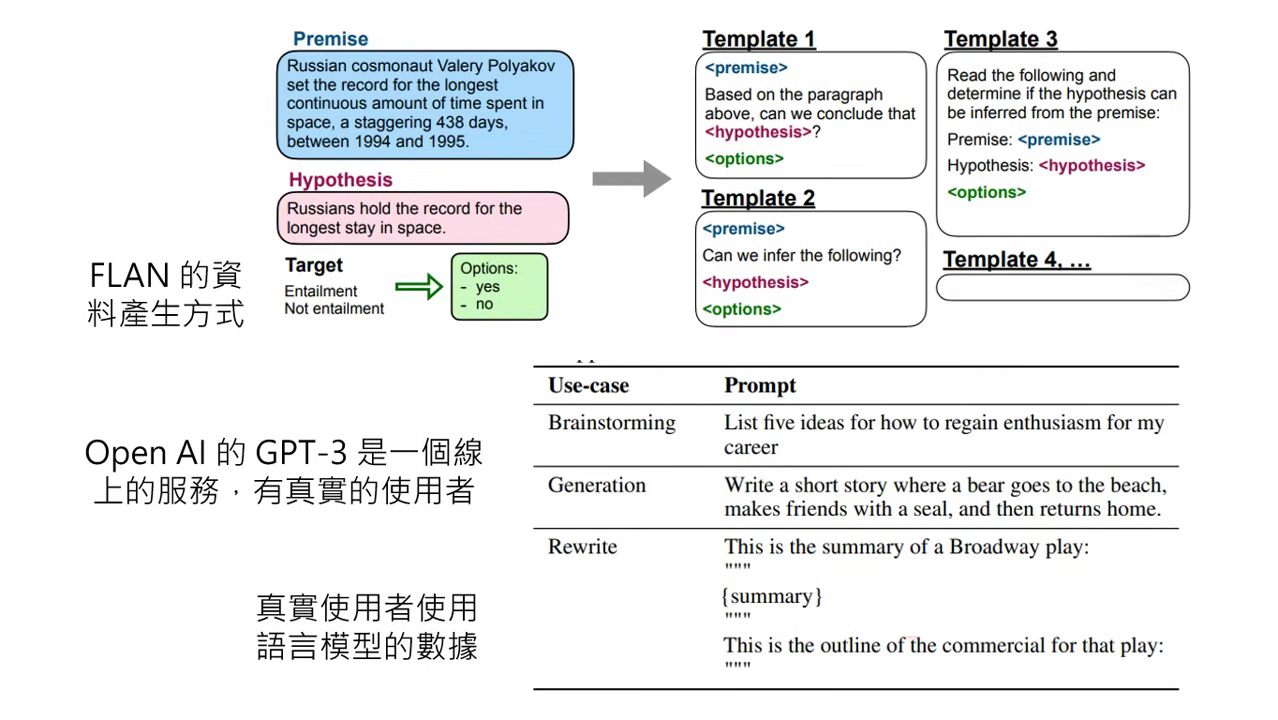
- 超越死板模板:Google 的 FLAN 資料多由研究人員使用「固定模板」將現成資料集轉化為問答。OpenAI 則認為這種方式與人類真實的使用情境落差太大。
- 真實使用者數據:OpenAI 利用 GPT-3 線上服務累積的真實對話,發現使用者問的問題千變萬化(如寫故事、寫遺囑、提供職涯規劃建議等),遠比學術模板多樣化。
- 實測結果:使用真實使用者數據微調出的 InstructGPT,在人類喜好程度上顯著勝過原本的 GPT-3 以及 Google 的 FLAN。
 |  |
|---|---|
| 透過真實使用者的問答模板改進訓練模板 | 實測結果顯示 InstructGPT 在人類喜好度上勝過 GPT-3 與 FLAN |
高品質資料的匱乏與 Self-Instruct 的誕生
一般人不像 OpenAI 擁有線上系統可以收集真實使用者的千變萬化問題(如腦力激盪、寫故事等)。

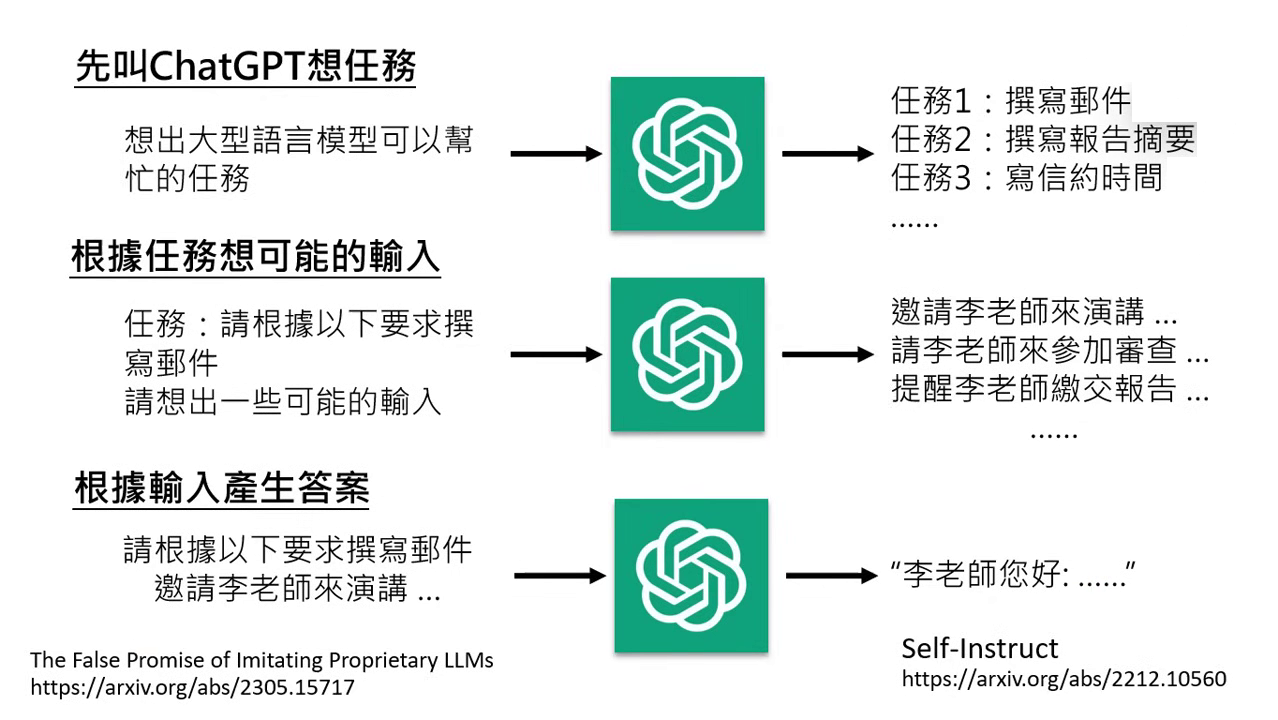
逆向工程(Self-Instruct)
- 以 ChatGPT 為師:既然沒有資料,就透過逆向工程對 ChatGPT 進行「Self-Instruct」。
- 三步驟流程:1. 發想任務:問 ChatGPT 模型通常能做什麼事(如寫郵件、摘要)。2. 幻想問題:請它針對任務幻想使用者可能會有的各種輸入問題。3. 產出答案:將幻想出的問題丟回給 ChatGPT 產出正確答案,以此自動生成訓練用的標註資料。
- 結果:小團隊雖然沒有真實數據,但能透過此方式取得「沒魚蝦也好」的訓練教材,開啟微調的第一步。
預訓練模型參數的壟斷與 LLaMA 的開放
強大的預訓練模型(如 GPT-3 或 PaLM)參數並不公開,這導致全世界曾一度卡在「沒人能打造自己模型」的狀態。
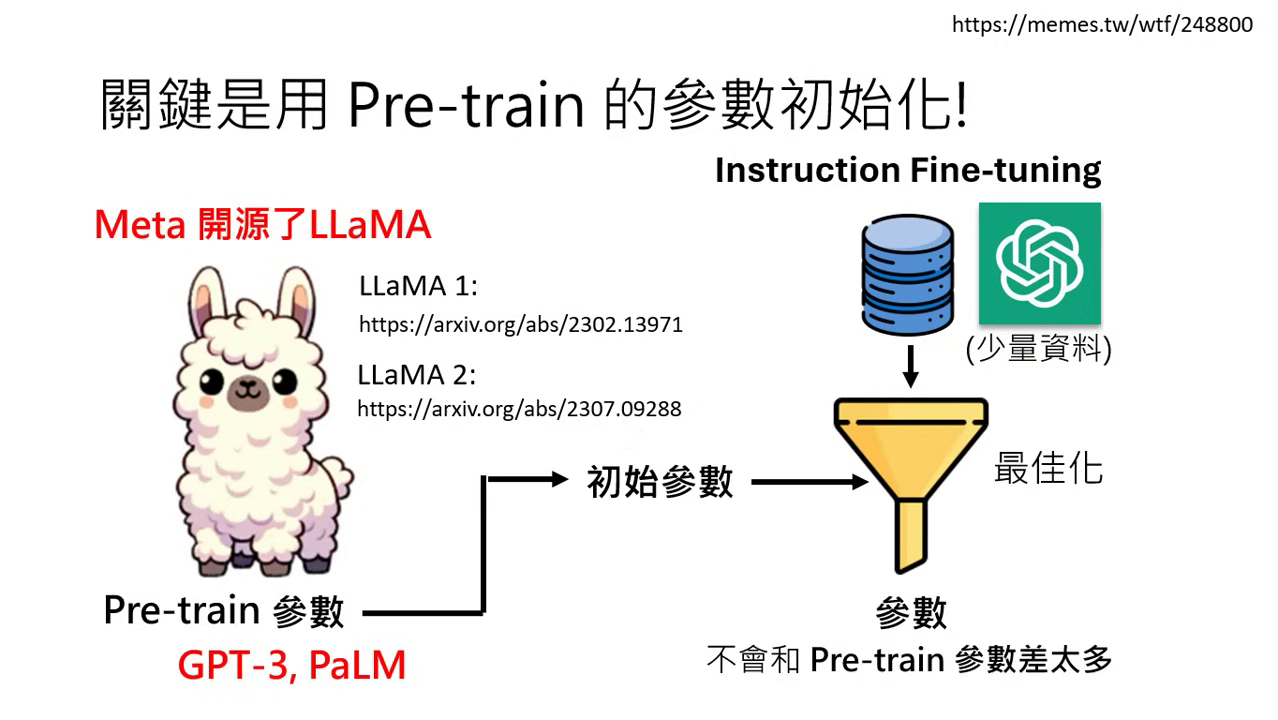
LLaMA 的出現與解放
- Meta 改變了生態:2023 年 2 月 Meta 釋出了 LLaMA 的預訓練參數,打破了技術壟斷,讓任何人都能以其為初始參數來打造模型。
- 子孫模型的爆發:
- Alpaca (Stanford):使用 LLaMA 參數搭配從 ChatGPT 取得的 5 萬筆資料微調而成。
- Vicuna:使用 LLaMA 參數搭配分享網站上的 7 萬筆真實對話資料微調而成。
- 結果:結合 LLaMA 與 Adapter (如 LoRA) 技術,大幅減少了所需的運算量,讓「人人都可以 Fine-tune 大型語言模型」的時代正式開啟。
 | 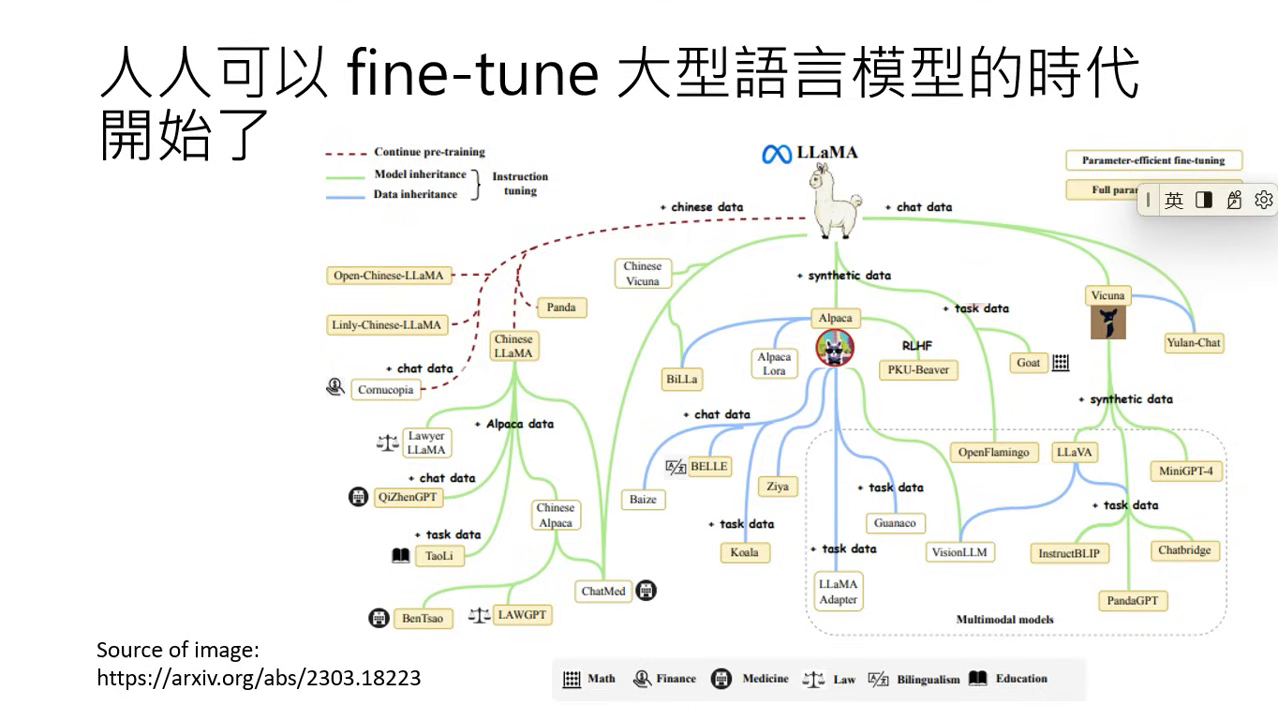 |
|---|---|
| Meta 釋出了 LLaMA 的預訓練參數 | 大語言模型時代開始了 |