大型語言模型修練史 — 第一階段:自我學習,累積實力
大型語言模型的本質:文字接龍
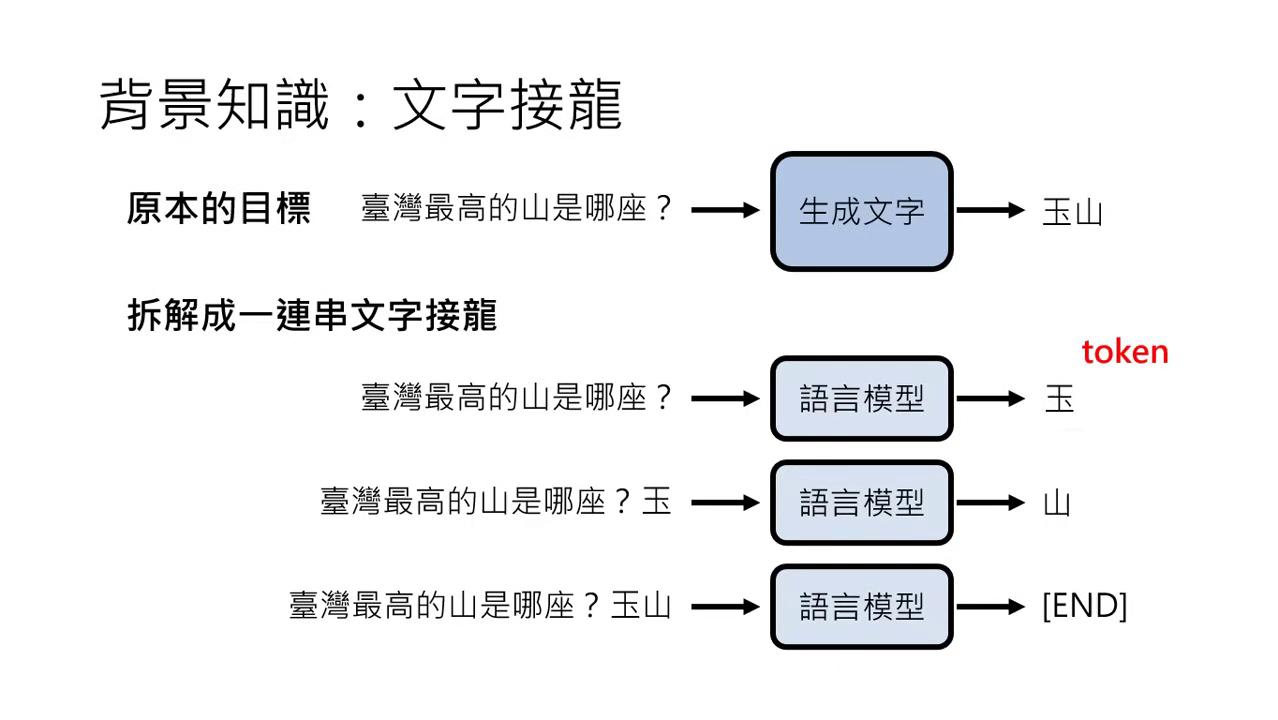
- 核心機制:大型語言模型(LLM)做的事情本質上就是文字接龍。當模型接收到一個未完成的句子(輸入),其任務是預測下一個最適合接續的單位(輸出)。
- Token(符號):
- 模型處理文字的基本單位稱為 Token。
- 不同模型對 Token 的定義不同,例如在 ChatGPT 中,兩三個 Token 才能組成一個中文字;但在課程簡化說明中,可將一個中文字視為一個 Token。
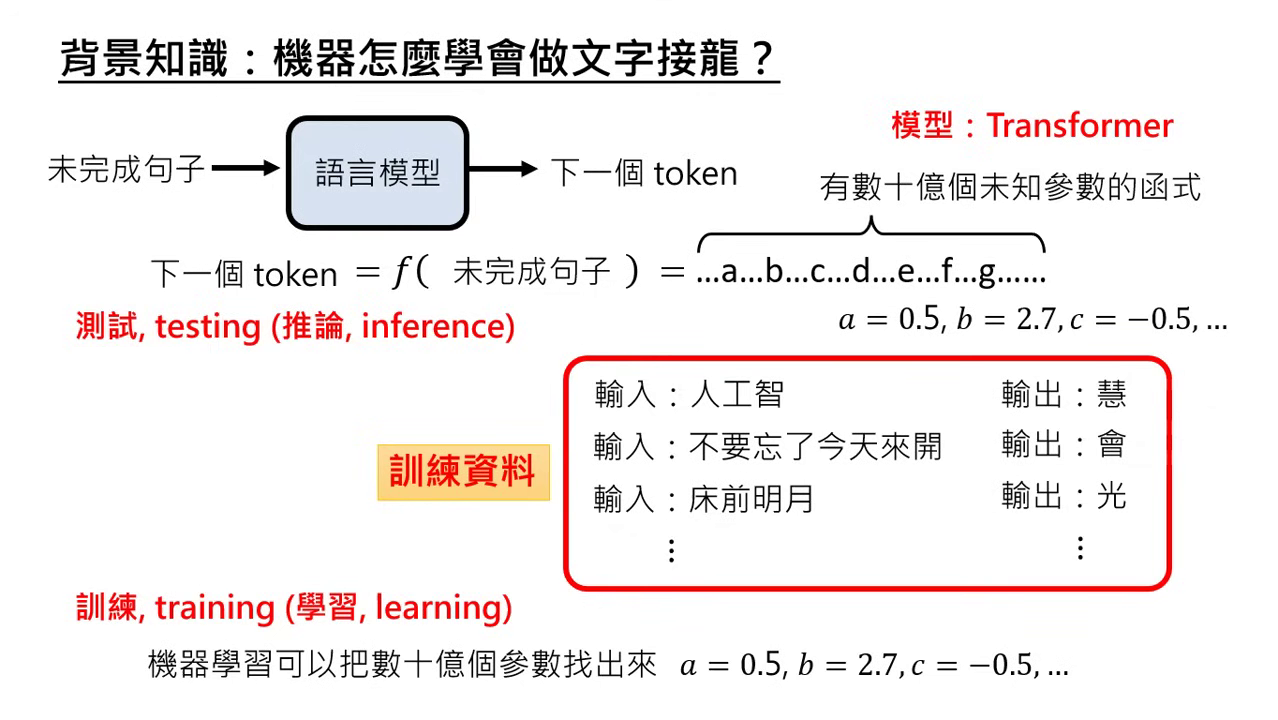
- 函式觀點:模型是一個極其複雜的函式 。輸入��是未完成的句子,輸出是下一個 Token。由於任務艱巨,這個函式需要數十億個未知參數才能達成。
訓練流程與技術挑戰
- 訓練 (Training) vs. 推論 (Inference):
- 訓練:利用大量訓練資料自動找出數十億個未知參數的過程,又稱為學習 (Learning)。
- 推論:找完參數後,將參數帶入函式實際執行文字接龍,又稱為測試 (Testing)。
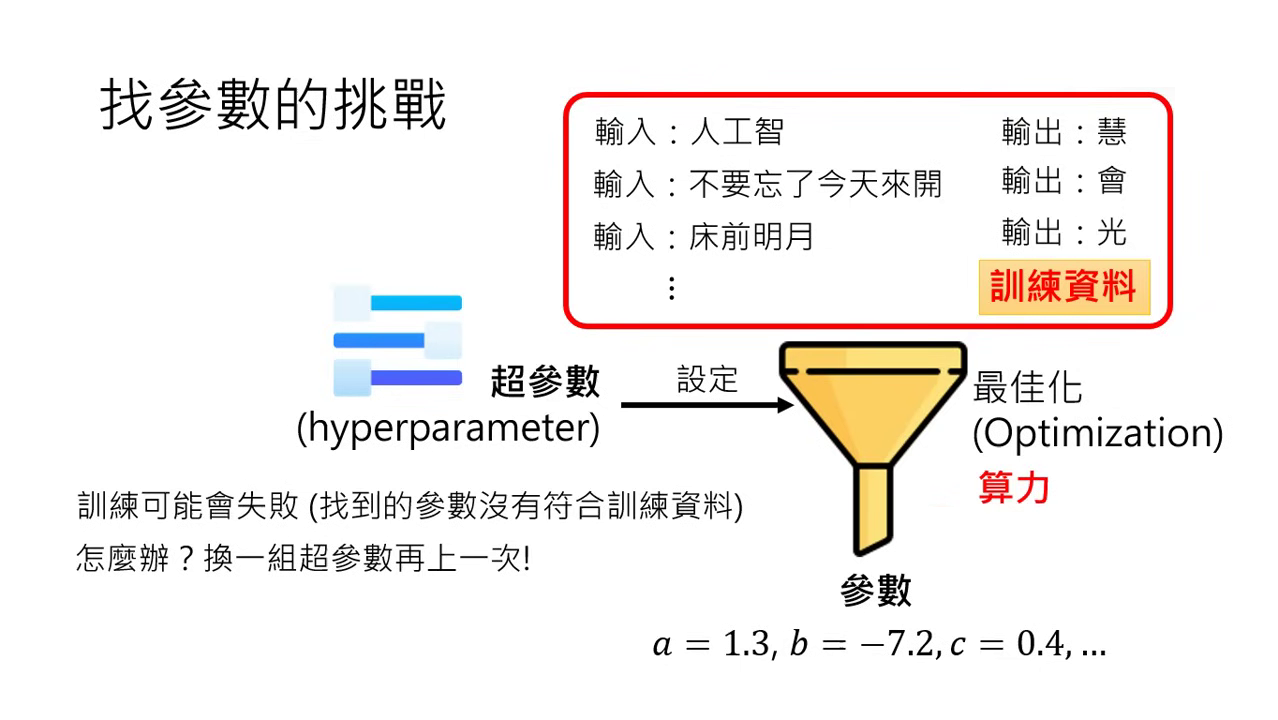
- 最佳化 (Optimization) 與超參數 (Hyperparameter):
- 最佳化是找參數的自動化過程。
- 超參數:由人類設定的最佳化機器設定(如訓練失敗時需要更換超參數再試)。一般人所說的「調參數」通常是指調整超參數。
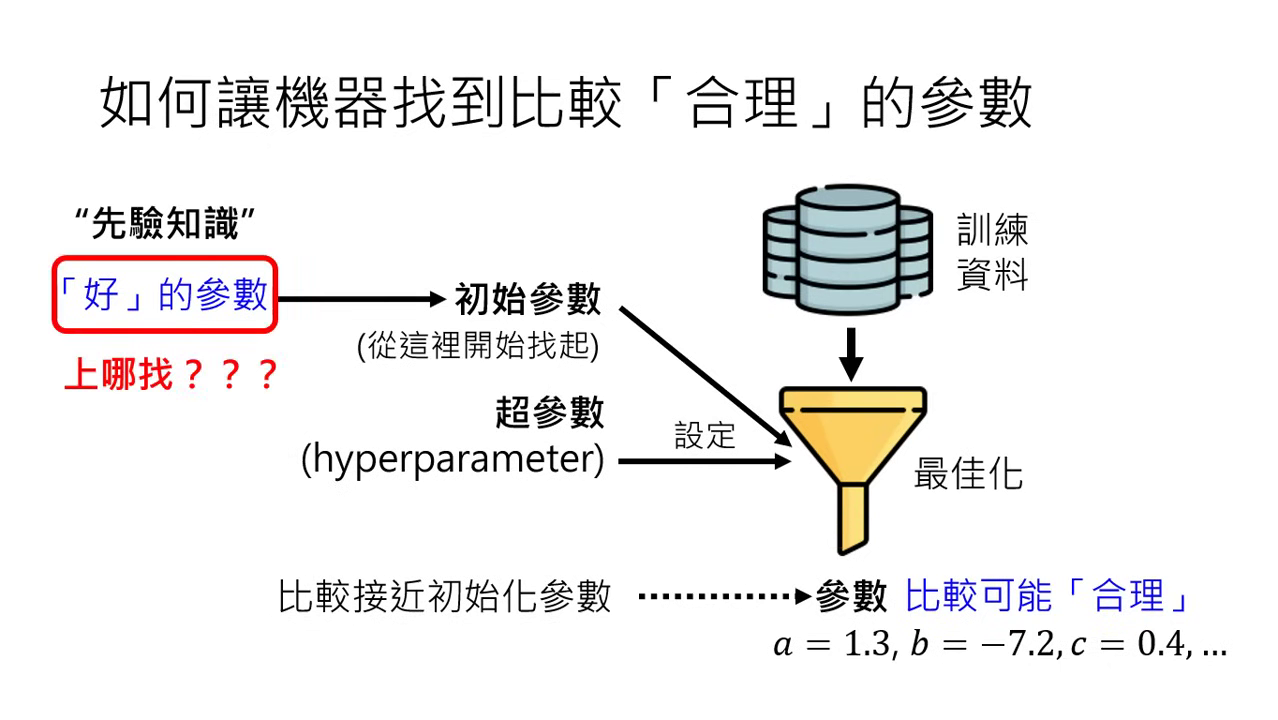
- 初始參數 (Initial Parameters):
- 最佳化演算法會從初始參數開始找尋。
- Train from scratch:從隨機生成的初始參數開始訓練。
- 先驗知識:若能設定一組�好的初始參數,能讓最終學習結果更符合需求。
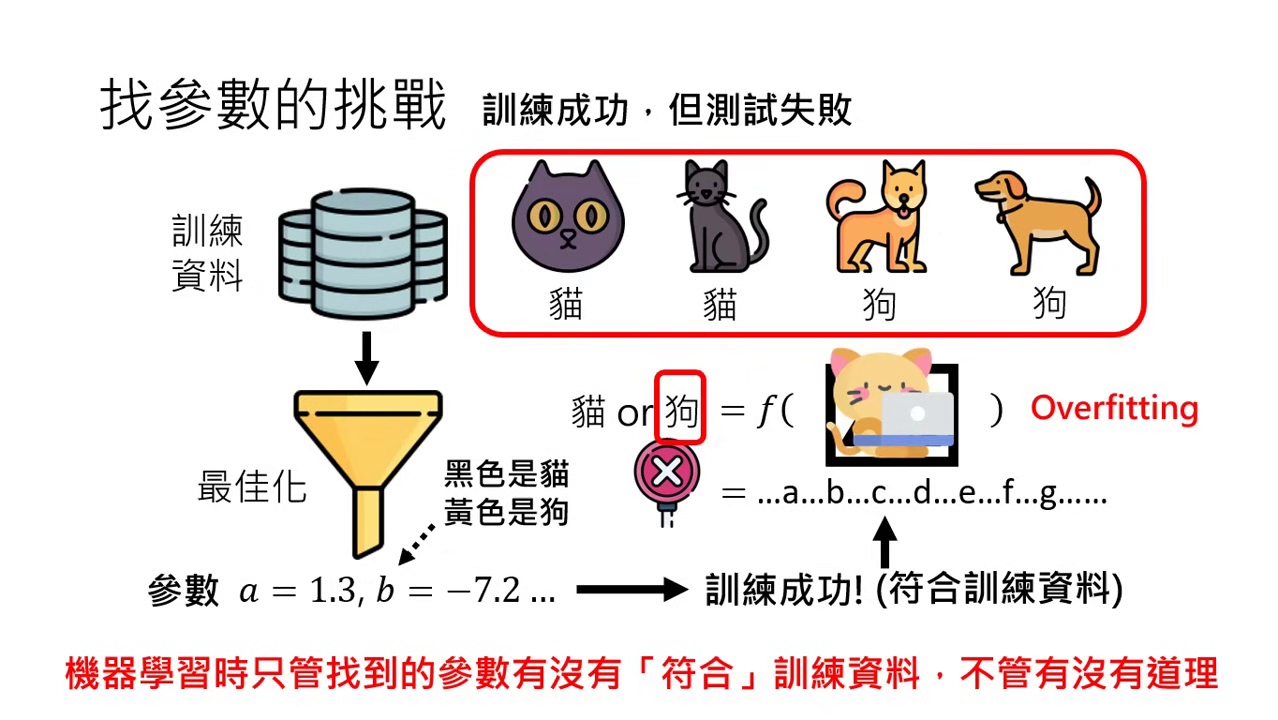
- 常見失敗:Overfitting(過擬合):
- 定義:訓練成功(符合訓練資料限制),但測試失敗(面對新資料結果錯誤)。
- 原因:機器只問參數是否符合訓練資料,而不管其是否有道理。例如只根據顏色(黑貓、黃狗)而非外型來分類。
- 對策:增加訓練資料的多樣性。
大型語言模型的修煉三階段
大型語言模型的修煉過程主要分為三個階段,雖然每一階段的核心技術都是在學習**「文字接龍」,但其使用的訓練資料與目標**各有不同。
第一階段:自我學習,累積實力 (Pre-train)
- 核心目標:讓模型學會基礎的語言知識(文法結構)與世界知識(對物理世界與人類社會的理解)。
- 訓練方式:採用自督導式學習 (Self-supervised Learning),機器透過閱讀海量的網路資料「自己教自己」。
- 現狀與局限:模型在此階段雖然累積了深厚的「內功」(如 GPT-3 讀了相當於 30 萬遍哈利波特全集),但它僅是盲目的文字接龍機器,不知道如何正確回答問題或遵循指令。
第二階段:名師指點,發揮潛力 (Instruction Fine-tuning)
- 核心目標:教導模型使用知識的方法,使其學會如何「回應指令」並成為具備實用功能的通才工具人。
- 訓練方式:透過人工標註的高品質資料進行微調。人類老師會準備大量的「問題與對應答案」範例(如:標明哪部分是使用者問的,哪部分是 AI 應該回應的)供模型學習。
- 關鍵技術:有時會使用 Adapter (如 LoRA) 技術,在不動原始參數的情況下增加少量新參數進行優化,這能讓模型具備極強的舉一反三能力(例如教它英文,它能自動學會如何用中文回答)。
第三階段:參與實戰,打磨技巧 (RLHF)
- 核心目標:對齊 (Alignment) 人類的偏好與需求,讓答案更符合人類的價值觀,並確保模型的安全性與有用性。
- 訓練方式:採用人類回饋增強式學習 (Reinforcement Learning from Human Feedback, RLHF)。人類會對模型產出的多個選項進行排序,告訴模型哪些是好答案,哪些是不好的。
- 關鍵機制:引入回饋模型 (Reward Model) 來模仿人類的喜好,當模型產出人類覺得好的答案時,就提高該類答案出現的機率;反之則降低。

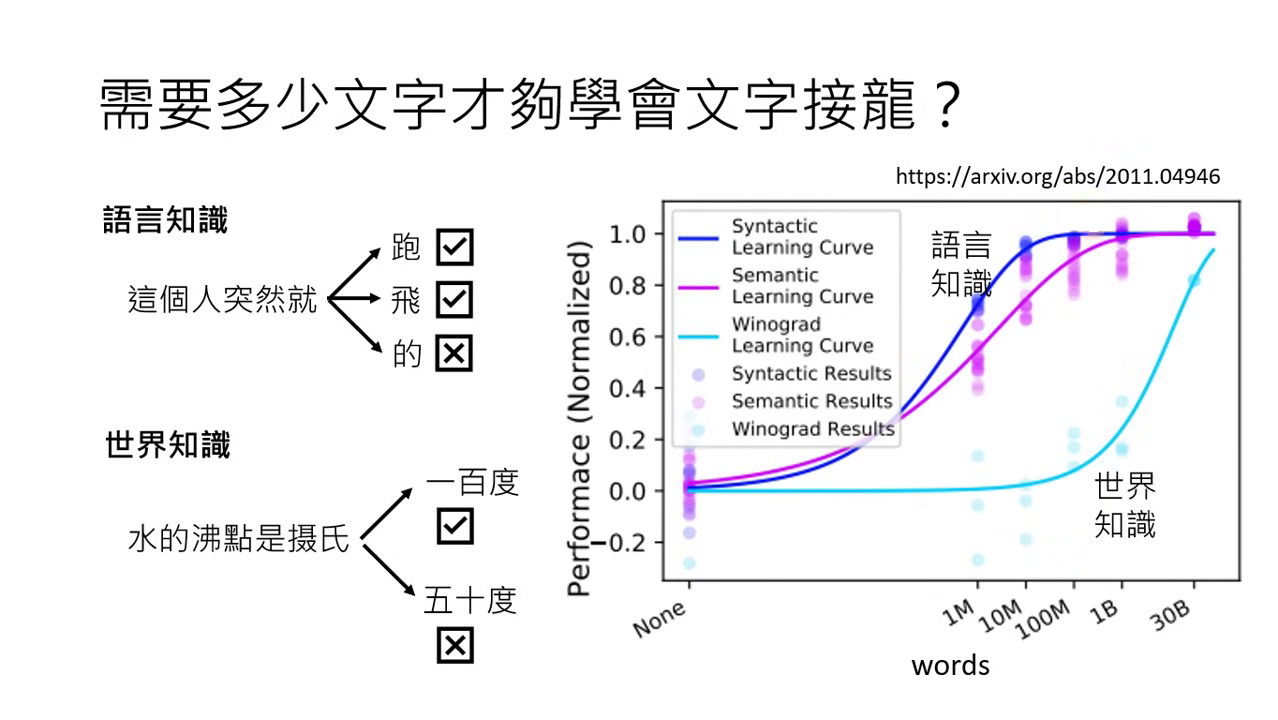
學習內容:語言知識與世界知識
要正確接續下一個 Token,模型需要具備兩面向知識:
- 語言知識:理解人類語言的文法結構。這部分需要的資料量相對較少。
- 世界知識:對物理世界或人類社會的理解(例如:水的沸點是 100 度)。這需要極其龐大且具備層次的資料量才能學好。
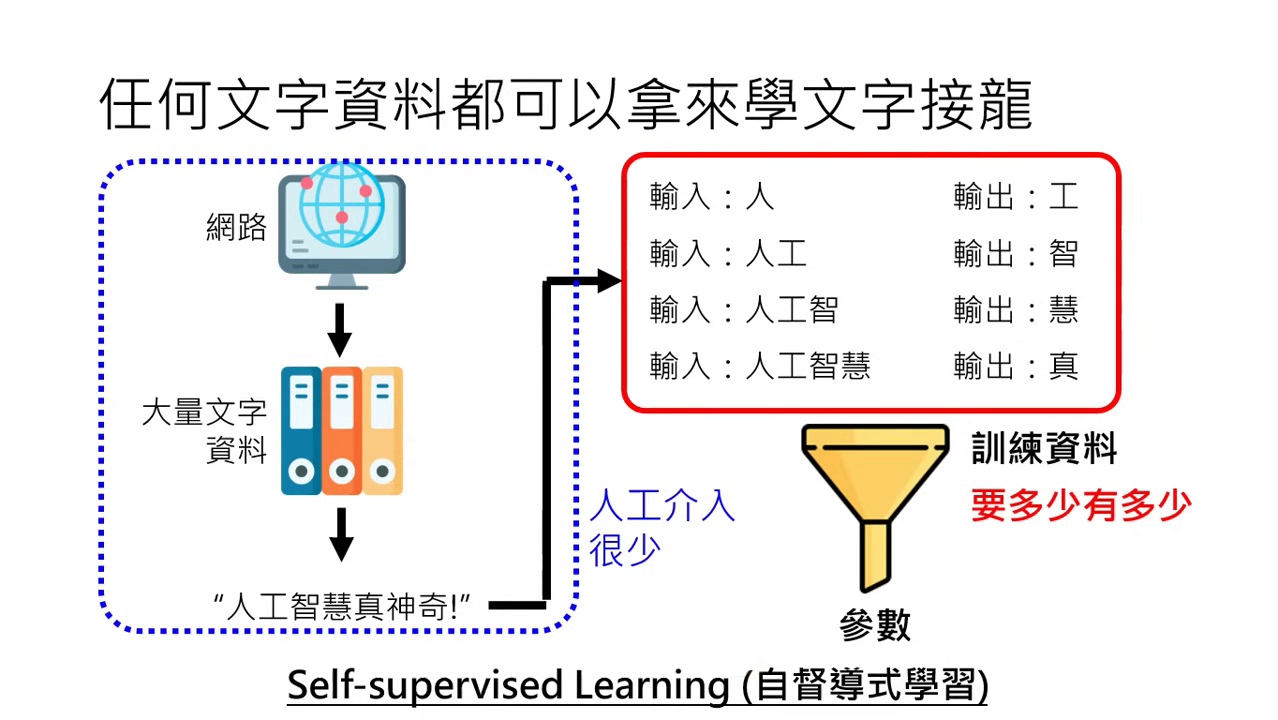
自督導式學習 (Self-supervised Learning)
- 資料來源:主要來自網路上無窮無盡的網頁文字。
- 運作方式:不需要人工標註答案,機器自己教自己。從句子中自動切分出「輸入」與「預測目標」(例如:「人工智」後面接「慧」)。
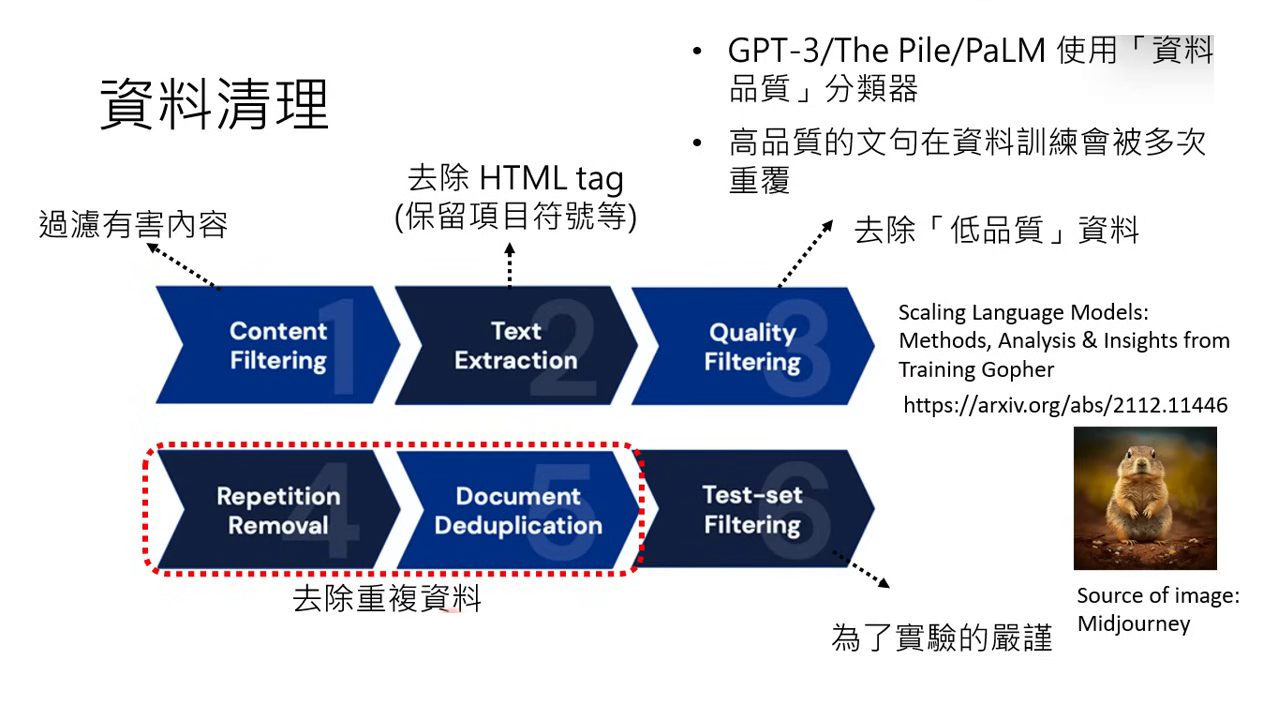
- 資料清理 (Data Cleaning):
- 過濾有害內容(色情、暴力)。
- 移除 HTML 符號,保留有意義的符號(如表情符號)。
- 去重 (De-duplication):避免模型反覆看到重複內容(如婚禮業配文出現六萬次)而導致輸出偏誤。
- 品質控制:使用分類器挑選高品質資料(如維基百科、教科書),讓模型多看幾次以增加影響力。
 |  |
|---|---|
| 自督導式學習 | 資料清理 |
OpenAI GPT 系列與模型演進
模型的能力取決於「天資(參數量�)」與「後天努力(資料量)」:
- GPT-1 (2018):1.17 億參數,約 700 本書的資料量。當時並未引起太大波瀾。
- GPT-2 (2019):15 億參數,40GB 資料。雖被視為巨大模型,但當時正確率僅約 55%。
- GPT-3 (2020):1750 億參數(GPT-2 的 100 倍),580GB 資料量(約 3000 億 Token,相當於哈利波特全集讀 30 萬遍)。正確率提升至 50 多 %,但仍極難控制,需非常認真設計 Prompt 才能正常運作。
- PaLM (Google):規模為 GPT-3 的三倍,但仍存在難以控制輸出的問題。

第一階段的局限
在第一階段完成後,模型雖累積了驚人的內功(世界知識),但它不知道使用的方法,也不懂得如何「回答問題」,只會盲目地進行文字接龍。因此需要進入第二階段:由人類老師進行指點。
